阅读:0
听报道

演讲 | 沈 渊 (清华大学电子工程系副教授)
整理 | 吕浩然
● ● ●
我来自清华大学电子工程系,之所以会到求是西湖学会结构生物学的专场来做一个电子工程相关的报告,这其中还有些渊源。两年前一次求是的活动中我同李雪明老师聊起彼此的研究,第一次近距离了解冷冻电镜以及结构生物学这个“时髦”的领域。李老师提到他们利用冷冻电镜重构三维蛋白质的过程中遇到了一些数学问题,而我认为解决这些问题,电子系的很多数学工具正好能用上。所以,通过电镜、通过蛋白质重构,我们开始了合作。
今天我主要想介绍我经历的两个现代信息技术应用于生命科学中的实例,它们也和结构生物学中紧密相关。
首先我们回顾一段历史,这里面也体现出信息技术和其他学科的结合。在上世纪60年代美苏冷战期间,两国都开始了太空探索,而美国NASA水手号计划担负起了行星系探索的任务。1964年,水手4号成功飞越了火星,并传回了第一张人类近距离拍摄火星的照片。

五年之后,水手6号问世,相比之前的水手4号,水手6号整体质量从两百六十千克上升到了四百千克,这也就是说火箭的运载能力变强了,能把更重的东西推向外太空;
第二,水手6号上通信设备的发射功率提高了一倍,这也使得它的回传数据率从每秒33比特升到了270比特,回传数据的能力提高了八倍,八倍的提升意味着什么?意味着,世界第一次能清晰地看到火星表面的细节。

发射功率的提高意味着科学家们需要不断突破物理的限制。发射功率若想提高一倍,在1960年需要花费约为300万美元,这代价还是很高的。不仅如此,因为它的载荷有限,人们也不可能无限制提高它的发射功率。但是水手6号的回传能力仍提高了八倍,这归功于很多新的通信和编码技术。科学家们事后估算了一下物理学和数学对水手6号性能提高的贡献比,差不多是50%对50%——物理学家能把更重的东西推向火星,能够把更大的通信设备、电池等装备到6号上;而数学家通过基于信息论的新型通信手段,大幅提高回传数据的可靠性。
如果把水手6号的例子映射到结构生物学的冷冻电镜上,生物学和电子工程的合作可以概括为:在提升硬件的同时,我们也可以在算法上改进,帮助冷冻电镜得到更高精度的照片,恢复出一些更高精度的结构。所以说,物理上我们已经有了很好的冷冻电镜,是不是我们可以在数学方法上找到一些突破?这也是我跟李老师合作的主要目的:提供更好的算法,进而提升冷冻电镜重构的性能。
我今天简单举两个例子,说明电子工程领域的一些工具和理论,怎么样来解决生物学中的问题。一个是DNA的高通量测序,如何从信息论的视角出发,提高用碎片重构DNA序列的性能;第二个是蛋白质的三维重构,我们怎么样用统计推断的技术来解决蛋白质三维重构的一些问题。
信息论视角下的DNA测序
首先是DNA的高通量测序,这其中涉及到了信息论的意义。DNA链条通常非常长,比如说由10的9次方个碱基组成(我不是生物专业,所以我讲述不准确的地方请大家指出)。我们测序的时候一般会得到很多碎片,将这些碎片整合成原来的DNA。而信息论,可以简单地看作在打电话时将声音进行编码变成数字信号,再通过无线传输送到另一端。另一端会进行解码,最后恢复出音频信息。
理解这一信息论的问题,首先需要建模,把这个问题转化成一个严谨的数学问题。1948年,信息论的鼻祖Claude Shannon在他的经典文章中提到一个关于信息论的数学模型,主要阐述怎么用一种非常简单的数学模型来建模一个复杂问题,并通过数学分析来给实际系统一些很好的指导。基于数学模型,信息论回答了两个问题。首先涉及信息传输的一个理论极限,即通信中所谓的信道容量,这个理论极限任何系统都不可能打破;第二个问题是传输方式的设计,如何通过精巧的编码方式来接近信息传输的理论极限。
所以,信息论的意义就在于它能指导通信系统的设计,有了Shannon信息论的指导,工程师们不再是盲人摸象,可以知道距离那个理论极限还有多远,进而评价一种方法有多好。
落实到DNA高通量测序上,我们得到了一些碎片信息,怎样把它组装起来,进而得到原来的DNA。从信息论的视角看,那我们要问的问题是:我们至少需要多少片段才能以高概率来恢复这个DNA。
首先,这些片段必须能够覆盖整个DNA,如果中间有片段缺失,则将会失去一些遗传信息。数学家随即进行建模,假设DNA序列的长度为G,每个碱基位由独立同分布的随机变量组成,每个DNA片段的长度固定为L,切割点位也是均匀分布。在这种情况下,数学家Lander和Waterman给出了一个需要片段数目的最小值:

我们再来看一张图:
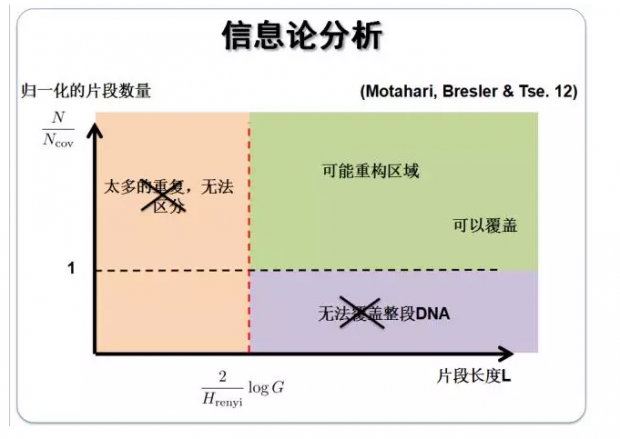
图中的横轴是片段的长度,纵轴是归一化的片段数量。图中左上和右下打叉的区域分别是因重复数量过多导致无法区分以及片段数量过少导致无法覆盖整段DNA,从而无法进行DNA重构。所以,可以重构区域只能是绿色的部分,也就是说,在理论上可能进行重构的部分,这个边界就是信息论告诉我们的。
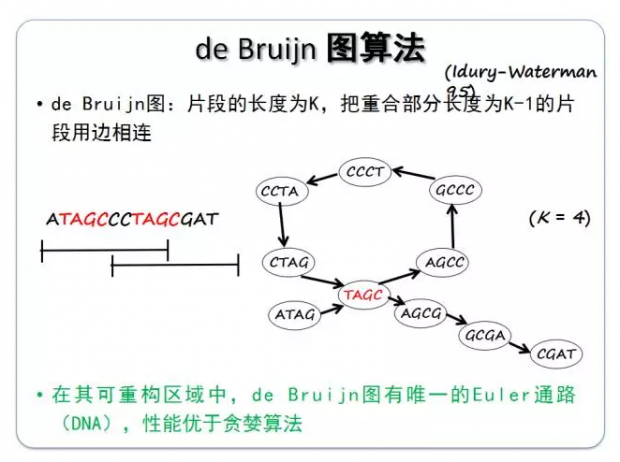
在得知理论极限后,我们怎么重构一组DNA?最简单的方法是运用贪心算法。贪心算法把短的片段都接起来,将重复的部分去掉之后得到期望中的DNA序列,这也是最直观的方法,却也有一些弊端。另一种算法叫de Bruijn图算法,我们将每一段序列打碎成图上的节点,然后将有连接关系的全联起来得到一个有向图,再通过图的方式结合起来,此时DNA重构的问题就变成了怎么样在这个图上找到一条最长的通路,这个图的算法可以有一个唯一的欧拉通路,它能够得到最长的可重构的序列。这个算法已经被证明性能要优于贪婪算法,就是利用了一些图的结构。
回到2012年伯克利研究组的工作。假设两个片段在原始的DNA上就是重复的,在重构时,如果片段不够多或者片段太短,就会导致无法区分两个重复片段哪个在前,哪个在后。研究组的工作告诉我们在这种情况下还需要更多的测量,才能够把它们区分开,形成非常直接的一条通路。这样的话能解决更多的问题。
信息论可以让我们衡量一个算法到底够不够好,如果不够好,我们应该怎么去进一步改进。所以,从信息论的视角来看DNA测序可能跟生物学家看DNA测序的视角不太一样,可称得上是一块他山之石。当然,信息论视角在实际的应用中也存在一些挑战,如果建模的工作做得不好,可能理论给出的极限就有偏差,所以一定要把模型建好;其次,读取片段时存在误差、算法不够缜密进而出错,这些都是更进一步的数学问题。这些就是信息论和DNA高通量测序之间的一些联系,或者说一些探索。
统计推断与蛋白质重构
第二个可能大家更熟一点,就是统计推断和蛋白质重构的之间的关系。我们可以利用所谓的统计推断方法来进行蛋白质重构:从一堆冷冻电镜拍摄的照片里面能够重构出一些蛋白质的三维结构。
一句话来概括统计推断,即基于系统模型利用未知参数的间接测量与先验知识去推断未知参数。就是说我们不知道明天会不会下雨。只能根据最近的天气情况去推断明天下雨的概率是多少。因为我看不到明天,看得到明天的话就不是预测了。
在蛋白质重构方面,它的未知参数是什么?未知参数就是我们想要知道的三维的结构。我们的观测、测量是什么?是冷冻电镜得到的二维投影图片。我们的模型是什么?因为我们的测量是通过一个投影矩阵和一些高斯噪声组合而成的,我们得到一些图片。
下图是我们的一个系统模型,通过这个模型测量,可以推测一个未知的结构,也就是说我们能将一个蛋白质重构。所以说,从统计推断的角度来看,蛋白质重构可以建模成一个比较经典的问题。
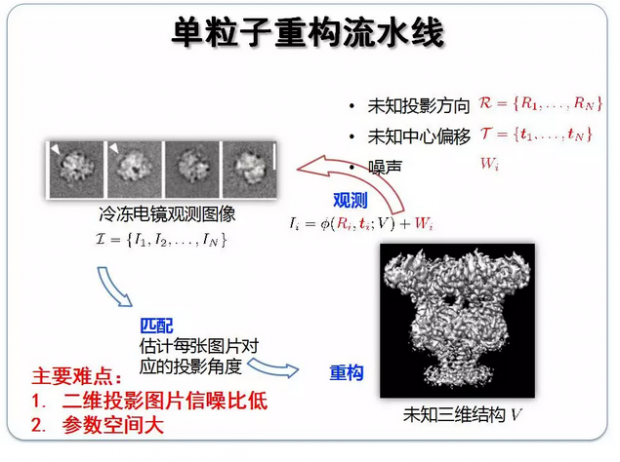
我们通过冷冻电镜观察蛋白质的二维照片,这些照片是经过积分投影矩阵和观测噪声作用而成的,科学家要通过这些二维图片,重构出这个蛋白质的三维结构,这就是蛋白质的重构问题。在投影的时候,蛋白质虽然被冻住了,但它冻住的“姿态”都不太一样,所以它的投影、偏移和噪声也不尽相同,这些都是未知参数。在这个过程中,难点在于二维投影图片的信噪比相当低,仅-10dB,而且未知的参数空间非常大。如果要用传统方法来统计推断的话,计算量很大,这也是为什么之前在进行三维重构的时候都需要运用计算机集群的原因。
而我们则采用了一种电子工程领域的粒子滤波技术来解决这个难题。这个粒子不是图片,而是一些离散的样本点,用这些离散的样本点来逼近计算中所需要的概率分布曲线。这样做的好处在于我们不再需要用一个非常规整的格点来描述一个带有权重的样本,而是用一种随机采样的粒子滤波方法,用一句俗话来说就是好钢要用在刀刃上。在做参数、姿态估计的时候,应该在最有可能的方向上进行高精度的分辨,而不需要去用同样的力度全盘采样,这就是粒子滤波技术大致的含义。

我们通过粒子滤波技术重新估计每张图片的投影角度和中心偏移,主要用到了三个方法:首先是随机粒子采样,它使得采样的速度更快,样本数也更少;其次,还有对图片进行加权,我们评估一张图片是否更像一个蛋白质的实际结构,这样可以将一些拍摄质量较差和非目标蛋白质的图片去除;最后,通过粒子滤波的方法还能不断地进行精确校准,可以将结构的旋转、平移和高度等结构校准出来。经过多轮迭代之后,得到的结果会越来越聚集到正确的一个方向上,它的结构信息的细节也越来越多。
我们和李(雪明)老师在粒子滤波技术的应用方面已经取得了阶段性的成果,实验显示,蛋白质重构的质量得到了很大提升。下一步,我们将尝试使用其他现代信号处理的方法来改进蛋白质重构算法,例如稀疏信号的处理。
如何理解稀疏信号处理?大家都知道我们可以对JPG图片进行压缩,文件大小大大降低,为什么?因为压缩的过程通过对整个信号进行傅里叶变换之后,其实大的系数都是在低频段,在频谱上集中在前段。所以,我们用一些低频的信号就可以很好的恢复一幅图片的原貌。也就是说,稀疏信号处理可以很好的解决欠定的逆问题,同时提升噪声下算法的鲁棒性。
从蛋白质的结构上来看,在结构中各原子之间也存在着一个稀疏性的问题,比如在一个100*100*100的结构中,它里面真正有蛋白质或者原子的地方可能仅有5%~10%,存在着稀疏性。所以,我们用算法再重构的时候不需要去将每个点都等效地来看,因为如果有些点不太像信号的话,就很可能是噪声。所以在工作过程中,我们尝试用稀疏信号处理来指导蛋白质的重构。我们已经对现有的算法作出了一定的改进,算法的结果仍还在测试中。
总结一下,我主要讲了两个信息科学领域的方法在生物工程方面的应用,一个是信息论和DNA高通量测序之间的关系,它能给生物学家们带来一个新的视角,告诉他们算法的一些边界;另一个就是运用统计推断去指导蛋白质重构,通过算法上的改进提升重构的蛋白质分辨率。这两个例子展示了信息科学的一些方法去帮助解决一些生命科学的问题的可行性。
反过来看,生命科学中的很多问题也会给信息科学以启发,使得信息科学产生一些新的方法,或者将一些已有的方法进行拓展,帮助我们更好地发展算法及相关的硬件、软件,对我们来说也产生了积极的作用。这也是交叉学科的一个意义所在,不同学科之间进行交流,了解真正的问题在哪,接着学科之间互相帮助,解决实际问题。所以,我觉得中国各学科之间需要一个比较长期、充分的交流和沟通。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号