阅读:0
听报道

编者按
当下人工智能的科普远不尽如人意,充斥朋友圈乃至各大媒体的报道离实在的人工智能面貌“渐行渐远”,而公众也时有困惑,莫衷一是。不少人工智能专家也颇有同感。为此,《知识分子》特邀请上海纽约大学张峥教授撰文“勘误”AI,他欣然应允。不成想,竟收到八千字长文,可谓畅快淋漓。勘误AI,谈何容易。张教授谦称,不过抛砖引玉之作,亟待同仁“反勘误”!若果真如此,唇枪舌剑,思想碰撞,乃读者之幸!
撰文|张峥(上海纽约大学终身教授、国家千人计划特聘专家)
责编|邸利会
● ● ●
未来论坛在上海纽约大学举办的一次讲座之后,嘉宾互动环节有这么一个问题:“人工智能最大的应用场景在哪?”我半开玩笑地回答:“在饭局上”。
人工智能是IT公司蜂拥争抢的标签,也是媒体和大众的热点议题。这不是坏事,但并不是说不需勘误。
比如这样的说法:
“人类的发明史上,从来都是应用需求领先,从来都不是技术领先。比如,人们想要飞,才有了飞机并不断改善;人们希望计算更快,才有了CPU。好像,人们并没有迫切需要AI。”
以上句子,摘自曾刷爆朋友圈一篇文章——“现在说自己在做AI的都是忽悠!”
这让我想起几周前参加上海科技馆一个面向中学生的科普活动时,给同学们留下的一句寄语:“以好奇之心,求无用之学。”因为在我看来,学界的AI研究动力,有一大半是(暂时的)无用之求。
科学和技术的原生力之一,是打造和使用工具。一部短短的文明史,也是人类不停发明和使用工具的历史。但是,革命性的工具不但落地时刻模糊,还要受到已有工具的阻击。上述文章里提到的集成电路芯片(IC)就是如此。电子管被晶体管替代,晶体管被IC替代,是从图灵开始之后硬件上的两大革命,但后者遇到了还在传统工艺里打滚的巨头们的顽强抵抗,直到美国航天局用IC实现阿波罗登月舱里的电脑配设。我个人认为,这是电脑史上最昂贵也最值得的原型展示(Demo):没有登月这种“无用之举”,连硅谷都不会存在。
关于“无用之有用”,从浙江大学王立铭教授那里,我还偷来三个精彩的反诘案例:“新生的婴儿有什么用?”(法拉第语);“这个研究不会有益于国防,但是会让这个国家更值得保卫”(费米实验室主任威尔荪语,于国会听证会);“(找希格斯)没用,但是我们就是想知道答案;而且我还知道你们其实也想知道答案,只不过你们自己没有意识到”(强子加速器科学家语,于国会听证会)。
科学和技术更重要的原生力,在于好奇心的驱使。
康德说最大的谜团,除了星空,就是我们自己的心智。要了解人自己,还有比再造一个“人”更直接的办法吗?在人工智能上走得远的研究者,不但应该广泛涉猎贴近人心的几个旁支,如心理学、行为学、神经科学,而在某种意义上更应是披着科学家外衣的哲学家。
就像莱特兄弟向鸟学习、引领人类飞行史一样,对人脑这个“老师”,人工智能也逐渐从“形似”过渡到“神似”,只不过万里长征才刚刚开始。人脑和AI的关系,是展开本文的一条线索。
既然已提及芯片,那我们就从硬件开始谈起。
人工智能芯片的发展简史
既然人脑是由海量的神经元链接而成,那么智能芯片采用同样的结构似乎天经地义,这是IBM TrueNorth芯片的出发点。而且,实现一个由大量简单计算加存储单元组合而成的芯片要远比英特尔的任何一个芯片容易得多,这让苦于摩尔定律迟早撞墙的芯片制造商看到了弯道超车的希望。另外,因为神经元互相之间发放连续的脉冲信号,TrueNoth在计算单元之间运用异步的小数据包来模拟。在对大脑的硬件“形似”上,TrueNorth作为一个代表,可以说走得相当远。
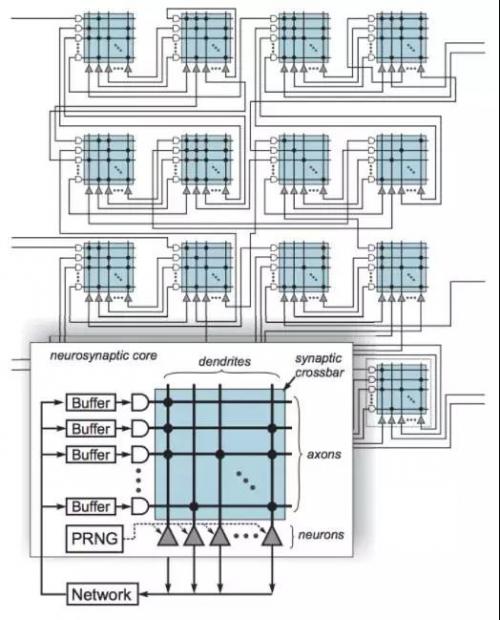
►IBM TrueNorth,受脑启发的芯片(来源:Esser, Andreopoulos, Appuswamy et al)
然而,这个思路有两大问题。第一,手握一大堆原子而不明白上层的大结构,不要说复原一个世界,连造个板凳都困难。机翼加上速度取得升力之后,必须要有“迎风而变”的可控性,而这正是莱特兄弟基于对鸟类飞行的大批观察、在自行车作坊和沙滩上大量实践之后成功的关键。其二,长程的电力运输中交流电比直流电有效率,这是守旧的爱迪生在芝加哥博览会的竞标中败给西屋公司的原因。大脑的内环境相当“恶劣”,因为脑容所限,长长短短的链接要在“汤汤水水”中绕来绕去,脉冲信号是合理的选择。可在芯片上也这么做,不见得必要。
如果说中科院的寒武纪芯片还有些TrueNorth的影子,那么谷歌、微软的AI芯片的架构不但更激进,而且更简单。
深度学习的模型依赖几个基本的计算模块(卷积网络、长短程循环网络等),但其背后更基本的精神,是高维矩阵的非线性变换,和由这些变换链接起来的数据流图。因此,把这个计算框架做好,同时衔接上层的软件开发环境,是开发AI芯片的两大重点,而拘泥于大脑的硬件架构只会自缚手脚。谷歌的TPU,存在对TensorFlow(谷歌开发的机器学习软件工具)过度依赖的问题,却是AlphaGo乌镇围棋一战中非常亮眼的明星,勘称广告史上的经典。TPU不是处理器,没有指令集,就是一坨高度优化的矩阵运算电路,其核心技术还是上世纪七十年代末的脉动阵列(Systolic array)。
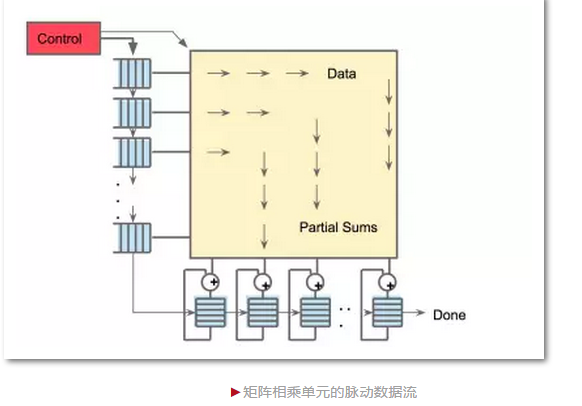
换句话说,人工智能在硬件上对大脑的神似,至少从最底层的计算单元来说,已经完成。在此之上,有些基本的、被广泛应用的计算模块(比如卷积网络和长短程循环网络)的设计也受大脑启发。
相比人脑,人工智能在模块种类上的积累还缺很多。但更多的困难来自(至少)两方面:缺乏更好更强大的数学工具,缺乏对脑科学的了解,或者部分了解了也不知道怎样“接入”最好。接下来我们就从一些貌似流行的看法说开去,不如先从很远的一个愿景——量子计算开始。
人工智能需要量子计算?
训练再复杂的模型,数学上都能归结为一个非线性的优化过程。这决定了深度网络和其错误回传、梯度下降的训练方法不过是其中的一个不错的、但绝不唯一的一个可能性。因此,不管白猫黑猫,能够优化就是好猫,任何数学工具都能用,都应该尝试,包括量子计算。
模型的学习过程的本质是非线性优化,对这一点,学界没有异议,但对其计算过程要和大脑有多“形似”却一直争论不休。
反向传递方法的发明人之一Geoffrey Hinton教授有个多年的心病,就是在对大脑的研究中尚未发现类似机制,应和者中不乏其他大佬,包括蒙特利尔的Yoshua Bengio,麻省理工的Tomaso Poggio等。但业界其他人,包括人工智能研究的“三驾马车”(Geoffrey Hinton,Yoshua Bengio以及Yann LeCun)中的第三位——纽约大学的Yann LeCun就觉得,反向传递更优美,是数学神器给我们的礼物。他对优化过程是否和大脑“形似”不太关心。
我持拿来主义的态度:优化就是优化,优化就是神似,过程形似没有必要。不过我认为,整个模型采用深度网络是必要的,使得模型和脑科学的实验比照存在可能性。从长远看,这么做会给脑科学提供另一种实验手段,反过来也会进一步促进人工智能的“神似”之旅。
对脑科学的了解,也能让我们判断这样的理由是不成立的:有一派人认为,大脑的工作机理就是量子计算,所以要量子计算。
我觉得,人类在一个基本符合牛顿定律的物理世界中竞争而生,需要量子计算这么高端、复杂的计算模式作为基石不太可能,也没有任何证据。支持者认为,神秘的“第六感”源自量子纠缠,但很多心理学上的实验表明,所谓“第六感”,不过是因为大脑在下意识中捕捉到很多细微、难以查觉因此无法言说的信号而已。
再让我们看看眼前的一些人工智能实例。
人工智能等于实时翻译、图像识别么?
一直以来,这几个应用有非常高的出镜率。目前,这些模型背后的工作原理,是从海量数据里总结统计规律,完成一个自底向上的深度非线性的映射函数,把标签Y拍到信号X上。但是,如果我们老老实实叫它们的实名——“统计学习”——那是多么的不酷啊!
这些模型最底层的单元计算,采用卷积网络或者长短程循环网络,除此之外,整个大的计算过程和人脑相差很远,连神似的皮毛都不沾,可这几个应用的热炒直接导致了不少的问题和误解。
人工智能极度依赖大数据?
“大数据”是个十分混乱的概念。首先,什么是打造人工智能需要的大数据?其次,多大才算大?比如,掀起深度网络大热潮的ImageNet数据集,有一百二十万张带标注的图片。图片中有哪类物体,在哪,通过互联网众筹的人力标定,再喂给模型来学习。一百二十万张是个什么概念?相当于一个人每秒一张,一天八个小时,看一整年的图片量。
这其实并不算多。人活一年,睁眼看世界,摄入的视觉信息远比这个要多得多,更不提人活一辈子会看多少。但如果每张都要让人记住是狗还是猫、是花还是草,不要说一年,我猜任何人连十分钟都挺不住。
换句话说,人脑消耗的数据量要大得多,但其中刻意去学的又少得多。
除了大脑强大的记忆和泛化能力,至少还有两个重要的手段,把大部分工作在下意识中自动处理掉了,这才使得昂贵的学习只成为了浮出水面的冰山一角。
第一个手段是,大脑对来自底层感官下一时刻的信号随时预测,预测准确则过滤掉,只有错了才进一步处理。不如此,淹没在各种各样的噪声之中的大脑就会“过劳死”。这也是一个人挠自己痒痒不会发笑的原因。我们的日常生活空间尺度足够大,符合牛顿物理定律,也因此充满结构,这使得大脑能对周遭世界建立模型,有了模型就能进一步建立预测机制。具有预测功能的大脑也更稳健,能容错通讯中因为噪音而丢失的信息。
第二个手段是让来自不同感官的多路信号互相监督。比如孩童把玩一个玩具,手上拿着的、眼睛看到的、耳朵听到的,是不同模态的信号,分别在不同的大脑皮层被处理。来自同一个物体这个事实,已经是个很强的监督信号,并不需要额外标注。相反,如果信号之间不自洽,比如看上去很轻的却拿不动,才会被注意到,并得到进一步处理。
带自顶向下预测、多模态协同的无监督学习方法,是现在的人工智能模型所缺失的。
强标注的样本在整个样本群中比例越小越好。我的好朋友江铸久九段说,人类棋手下过的好棋谱大概三万左右,那么在学习完这些对局之后,AlphaGo自己下了几盘呢?保守一点估计,AlphaGo自己对弈大概一秒一盘,每天八万多盘。按脸谱公司田渊栋博士的推测,谷歌动用了上万台机器,而AlphaGo项目至今已经两年多了。所以,AlphaGo发展到今天的围棋智力,其中有标注的数据只占总数据量的千万分之一或更少。
因此,人工智能确实需要更多的数据,但更需要减少其中强标注数据的占比。要达到这个目标,必须对算法和模型做原创性的改进,更“类脑”,而不是一味采集更多的人脸照片、标注车辆,行人、人声等等。
人工智能必然高能耗?
这又是一个似是而非,常用来批评人工智能的结论。其逻辑是这样的:大脑功耗约25瓦,一个四卡GPU服务器超过一千瓦——AlphaGo胜之不武。由此可以推论,类脑必须低功耗,尤其必须在低功耗的类脑芯片上实现。
这里引出的一个问题是,人脑和AI,在能耗上应该怎么比更合理?
能耗的分布在两个地方,一个是模型的训练,一个是模型的使用。
训练模型的确非常耗能。我曾参与创立的深度学习平台MxNet最近创了个最低记录,从头训练一个高性能图像分类器ResNet,耗资一百二十万美元。这笔钱相当于十几个国家自然基金面上项目,显然不便宜——但和训练AlphaGo的能耗比,实在可以忽略不计。
人脑确实只用25瓦能耗,如果必须耗用2500瓦,在自然界的竞争中必然被淘汰掉。但请注意,它不是一夜练成的,而是历经百万年的进化到了今天。把时间累积在一起,再加上各种试错,再加上各种天灾造成的重启和格式化,总能耗就一定低了吗?
所以,我们更应该关注模型在使用时的能耗。AlphaGo下棋的大致流程和人类棋手相符,但区别在于每一个变化都会一路算到底,而下一步又生出了新的变化。AlphaGo优化了搜索策略,限制了搜索空间,即便如此,千万步总要走的,而人类顶级棋手平均也就算二三十步。用几十步抗衡千万步,已经非常了不起了。但反过来,如果限制AlphaGo的计算步数,能耗下来了,胜率也一定会下跌。
在其他一般性的任务中,人工智能模型的效率确实非常低,但根源在于算法和人脑差很多。图像解析我在下文会讨论到,单拿自然语言处理来说,其他不提,成句时挑词,要把整个词表扫一遍,而实用的词表有至少上万个词,这显然极其浪费——人说话的时候,每个时刻的候选词并不多,这其中的量级之差上千上百。
对AlphaGo的苛求
和人脸识别、实时翻译等等相比,下围棋是个阳春白雪的活动。但是,谷歌的AlphaGo绝对是人工智能发展史上重大的一笔。它包括了智能思考过程中极为重要的几个步骤:感知,自省,判断,演绎,执行。AlphaGo是对大脑智力活动的神似,正因为这样,才走得远。
补充一句,AlphaGo算法中依赖的搜索树是模型中的重要组成部分,但并不由深度网络构成——不代表不能这么做,只是效率不会高。这又是一个不拘泥于形似的例子。
AlphaGo离真正的智能还远,但并不是因为以下几个流行的说法。
流行说法之一,AlphaGo没有通用性。这么批评AlphaGo的人忘了,大脑的通用性不在于它是变色龙,而在于它是瑞士军刀,配备了大批灵活合作的专业脑区。要求下棋的AlphaGo变身通用型人工智能,是无理的要求。AlphaGo的通用性只针对一类问题,这些问题规则简单,变化繁多,既有少量专家样本,又能零成本产生无数新样本。
人工智能要达到普适的通用性,需要继续向人脑取经。比如,如何以最经济、最灵活为准则,实时实地整合高复用的组件来应对复杂多变的环境?再如,怎么使得各组件的学习、计算的机制尽量一致,但又不失去专业性?举例来说,整合自上而下的预测反馈和自底向上的注意力,利用工作记忆组装在不同时间点获取的信息块,是各种任务都需要的基本架构。但视觉要解决“是什么”、“在哪里”,语言要解决语义、语法,每个任务内含几个互相缠绕的子问题,所涉及的功能块和任务紧密相关,无法也没必要和其他任务的功能块共享。
对AlphaGo的另外一个批评是,它没有情感。“AlphaGo可以赢棋,却不能赢得快感”,我的一个朋友这么调侃。
不错,它输了也皮厚,一点不会不好意思。可所谓至柔则刚,没有胜负心、心无杂念,这种至高的境界却是无数棋手苦求而不得的。人的世界完全不一样,人是感情的动物,多巴胺的奴隶,在人生的舞台上,太大、太小的压力都会让我们演砸了戏,只有适当的压力才刚刚好。
情感的来源在于对形势的解读,情感的作用在于对行动作出调整。再精准的解读如果没有用武之地,就没有多巴胺介入的必要性,而这正是AlphaGo实战的情况。如果对AlphaGo运行环境做限制,设定耗能的上限,那么按照对局势的判断,它有时候会提高主频放手一搏,有时候则进入省电模式闭眼瞎蒙。时不时“脸红耳赤心跳加速”的AlphaGo,是不是有了我们人类的情感呢?
集万千宠爱于一身的AlphaGo,没有生存的压力,“感情”是个多余的东西。而让单兵作战的人工智能获取“感受”、改变策略,没有那么难。在人机共生的未来,让人工智能在这种环境中捕获和预测人类微妙的情感变化,和人“感同身受”,才是真正需要研究的大问题。
既然说到了人类的情感,相对于人工智能,让人“自豪”的另外一个领域是艺术创造,可果真如此么?
艺术创造是人独有的,人工智能不会?
不止一次听过这种介乎安慰和宣言之间的说法。从这里出发,引申出的一个推论是,等机器人把脏活累活包了,人类可以安心地享受艺术创造了。
天底下有两种职业贵在原创:科学研究和艺术创作。这两方面的素养很重要,但它们作为职业,从古至今,都是处在长尾端、脑子长得不太“正常”的小众活动。在人机共存的未来,和机器人抢活儿干倒更可能,也应该抢,必然会抢——艺术创作领域很可能类似。
人工智能能不能从事艺术创作?一开始的几年,业界端出来的“作品”是不忍看的。其中一类,让模型把看过的样本“吐”出来,计算过程中有意无意的随机采样生产出一堆犹如恶梦中的怪物。比如训练样本中狗的图片多,就变成这样:

这和二十世纪初的达达主义很相似,当年所谓的“自动写作”就可以视为随机采样的过程,产生出来的文字效果上是一样的。达达主义的贡献在于矫枉必须过正,很快让位于超现实主义,昙花一现。
还有一种是照葫芦画瓢,更容易让人接受——只是“手抖”得有技巧,学了梵高的抖法就都成了向日葵、星空,学了蒙克就处处惊叫。

这些都和艺术创作的精髓相去甚远。摄影如要精进,除了勤按快门,要花同样多的时间看好照片,花更多的时间去挑照片。把好的艺术品喂给模型不是难事,难的是怎么“挑”。艺术创作不是胡乱踩点,要紧的是如何判断,有一度我觉得这后一点是死穴:AlphaGo可以判定局势的好坏,但应该不懂如何评判艺术吧?
不过,这几年人工智能学界的一个现象就是,不要把话说得太死了。
最近很火的一个深度学习分支叫“生成对抗网络”:把随机数推送给一个生成网络,合成伪数据(图片或声音),然后再把这些伪数据送进判别网络,判别网络比较真伪数据后,再产生让生成网络努力“造假”的压力。
这个框架的最终目的,是以少量样本充盈分布空间。两个网络共生共长、阴阳互补。这虽然和AlphaGo用强化学习左右手互博,是两种不同的训练方式,但在精神上都相当辩证。
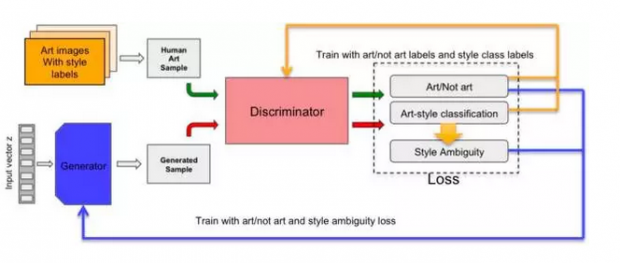
最近我注意到一项工作(CAN: Creative Adversarial Networks Generating “Art” by Learning About Styles and Deviating from Style Norms),让一个模型学习从十五世纪到二十世纪超过七万张作品,从巴洛克开始涵盖二十五种风格。这个模型的创新点在于判决网络有意为之的“四不像标准”,要求生成的图片既要像某种风格,又不能太像。

有人会说,那不过是已有风格的混杂而已,但熟悉艺术史的应该知道,混杂和迁移本身就是风格突破的重要源泉之一。令人惊讶的是,至少在网上“公投”的结果来看,已经是雌雄难辨。
在职业棋手被集体降级之后,艺术家会不会是下一个被碾压的群体?
我个人不是很关心这个问题。乌镇围棋大战之后我的总结是,围棋永远是人类脑力健身房中的宝贝,只是棋手的健身房中多了一个AlphaGo。艺术的“下场”也一样。该下棋下棋,该画画就画画。只是,不要再说机器不会艺术创造了。
艺术的美学标准,艺术家的“手抖”规律,AI作为神偷,已经化作自己的创造力。我认为(也十分期待)的下一个引爆点,是对艺术联觉的运用。简单的说,联觉是缺乏某类感官刺激,但被他类刺激引发的感知经验,就像纳博科夫在字母中“看”到、李斯特在音符中“听”到的颜色。
再比如诗歌,其充满张力的想象裹挟了视、听、乐感,是诗人对联觉的有意无意的挖掘,也是读诗的快感之一。不具备联觉功能的AI诗歌创作,在技巧上经不起推敲。我读过微软小冰的“诗作”,如果认为其想象力的背后有联觉的作用,也是我们读者自己在脑补。至于一些诗人的批评,因为对人工智能缺乏了解,也就没说到点上。
联觉的技术基础在于符合大脑计算机制的多模态信号处理。上文已经说过,大脑能够处理海量数据但又不需要强标注,之所以能这样,除了大脑的预测功能之外,还有赖于多模态信号之间的自洽和互相监督。而人工智能在这个领域的工作,还非常粗糙。我的看法是,这里的瓶颈在于单信号的处理还没做对。
即便完成了联觉,人工智能离真正的创作还差得远。AlphaGo能给自己的故事拍一个记录片吗?能发明一个游戏吗?要做到这些,不把人工智能“神似”人脑推到一个高度,不可能完成。
人工智能会往哪里走
讨论了这么多,大众普遍关心的一个事关未来的问题是,下一步人工智能会如何发展?从2012年到现在短短五年,人工智能的研究发展之快令人吃惊。如果有一个准确的预测,那就是测不准。不过,严肃的从业者都知道路途有多远。
在几年前的一个学术讨论中,我问几个专家,解决下面这个问题需要多久:树上五只鸟,开枪打了一只,还剩几只?
这个问题的设定本身是模糊的模糊的,从一只没有到五只都是可能的答案,不管答案是什么,无一例外我们都能说出为什么。换句话说,信息和信息的处理过程是透明的,可传递,可解释。解决和回答的过程包括转换、推理、同理心、常识的运用、语言的组织等等。一位专家的三岁女儿的回答是还剩下三只鸟。专家问为什么?她回答说,“因为被打死的那只鸟的朋友也走了。”不得不说,这是我听过的最具人性的回答。相比来说,如今的聊天机器人会说:你当我傻子啊?机器人的这种卖萌很可爱,但完全不是真正的智能。
类脑计算到底是什么,该怎么做,既令人兴奋,又让人困惑。把大脑想得太复杂,把电脑想得太简单,可能是寻不到主动脉、找不到衔接桥梁的原因。把“神似”的层次提高,做深,和脑科学进行比照,螺旋性地上升,将为今后人工智能的远航提供燃料。比如:单模态信号处理中有机整合自上而下的预测和自底向上的显著性,多模态信号处理中的协同学习机制,结构化信息在生成网络中的挖掘,带模型预测(model-based)、层次化(hierarchical)的强化学习等等,这其中的任何突破都让人期待。
原创之伤,在于缺了三点水
最后,我想谈几句相关的“题外话”,也是有关技术之外的另一种“勘误”:中国人工智能研究已经走在世界前沿。
我相信,若单把人工智能作为服务落地,中国有可能成为世界第一,但若论人工智能的研究,目前国内的状况不容乐观。
从学界的统计数字来看,发自中国的论文总量到世界第二位,和GDP同步。但另有一个关于影响因子的统计,在34位。把这两个数字放在一起看,显然落差非常大。这两个数字很笼统,计算标准也没有定论,但是中国学术界总体缺乏原创性,而且缺口相当大,应该没有疑问。2017年的顶级AI会议NIPS(Neural Information Processing Systems,神经信息处理系统进展大会),录用六百多篇,中国各高校加起来入选二十多篇,而一个小小的纽约大学就有十篇。
另有报道,在今年的国际计算机视觉与模式识别领域的顶级会议CVPR(Computer Vision and Pattern Recognition)中,华人学者占了近半。这个统计数字可喜,但也不是没有问题。大概十年前,我还在系统研究领域工作,在和MIT的一位教授共同创办亚太地区系统研讨会的时候,对该领域顶级会议做了一个类似的统计,但添加了另外一个指标:除了参与的文章外,统计了华人学者作为指导老师的文章数,结果两者比例十分悬殊,而且连年如此。换句话说,当年攻坚拔寨的华人学生,毕业后很少成长为有视野、有创造力、有野心的指挥官。就像一把好枪,一旦出了厂,就丢了瞄准镜。
中国学术界原创乏力,原因在哪?我认为原创之伤,在于缺了三点水。资本驱动之下加上过度注重实用;短期、“有用”的研究蔚然成风;日积月累之后,对“源”头发问的习惯在工作中缺席。
在研究刚起步的时候,吃透别人的方法,想办法改进,这时候问的是“毛病在哪,怎么能更好?”这种提问,是在问题链的末端。往上回溯,可以问“这是正确的、有意义的衡量手段吗?”或者“这问题的假设对不对?”。更进一步可以问,“这一类方法的共性是什么?缺点在哪?”“这是个真问题吗?这问题背后的问题是什么?”等等。
这一步步的追问离源头越来越近,离当前的“潮流”也越来越远,也就越来越可能在性能上输给流行的、打磨了太久太多的模型,但也越有可能做出原创的工作。
有一次一个年轻的创业者和我聊天,谈起他们最近一个把深度网络稀疏化、降低功耗和减少内存消耗的工作。这工作显然对优化现在的模型很有意义,但我问他知不知道人在解读一张图片的时候由注意力驱动,看几眼就够了,而每眼只消耗几个字节的带宽?有没有意识到,这是我们睁眼就有的视觉行为。
相比之下,现在流行的深度学习框架从一张图上并行检测几千个小窗口,完全违背人脑视觉系统的计算过程,如果真要降低功耗,是不是应该想想这个框架是不是对?所谓机器已经在识图问题上超过人类,只是在特定的几个子领域,这不是学界常识吗?
流行的框架不但浪费资源,还会丢失信息。下面是斯坦福大学李飞飞教授开的网课“卷积神经网络和计算机视觉”第一讲里的一张图。这张图在说什么?

喂给AI大批这样的图片,加上“户外运动”这样的标签后,模型甚至可以吐出“草地上四个人在玩飞盘”这样靠谱的回答。人脑解读这样的图片,是个串行的时序过程,比如从姿态、眼神,追踪到左手第一人手上的飞盘。一个依赖并行探测的模型,很难或者不可能恢复其中丰富的信息。能恢复时序、恢复时序中隐蔽的语义的模型,更类脑,更难实现,但显然更有泛化能力,也更省能耗。
人工智能必须向大脑学习,并不是说要在细枝末节上进行高仿真的拷贝。一味追求“形似”,反过来会阻碍人工智能的发展。应该认真思考的,是如何做到“神似”,得其精髓而不拘泥枝节。显然,这里要问的,还是“源”在哪。唯有如此,才能在飞鸟的背后,捕捉到飞行。
学术要做最先,落地要做最好;原创的责任归学术界,落地的责任归产业界,前者从0到1,后者从1到无穷大。如果学术界追求体量而不是原创和影响力,那将是对资源的大浪费。
事实上,对原创的重视分布在整个生态环境。谷歌、脸谱等一线大公司在实验室里圈养大批优秀人工智能专家,其开源和长线的基础研究,质和量都不输、甚至超过学校实验室。除了推进科学,这样的布局也有商业上的考虑。举例说,卷积和长短程循环这两个基础部件,如果不是因为它们的专利已经过期,那么今天几乎所有的深度网络模型都要交专利费。可以想象,体量如此大的中国市场,要交的份额只会最多。
向“源”而问,才有原创,才能培育真正的科学精神,才能避免未来的巨额“原创税”。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号