阅读:0
听报道
应用人工智能诊断癌症,是当前的一个热点研究领域。然而,《新英格兰医学杂志》(NEJM)2019年12月12日在“观点”栏目发文指出,缺乏金标准将导致机器学习带来的癌症过度诊断,该文还给出了解决这一问题的建议。
撰文 | Adewole S. Adamson, H. Gilbert Welch
人工智能是计算机科学的一个分支,其致力于执行通常需要人脑才能完成的任务。人工智能领域的一个主要分支是机器学习,计算机通过分析数据来学习并执行任务,而不需要来自人类的特定编程指令——也就是说,计算机生成自己的决策算法。机器学习技术的优点在于能够独立地识别数百万数据点中的模式,以便进行分类和预测。
机器学习在医学上有极大潜力,特别是在医学图像的解读方面。它的一个重要优点是速度:机器学习算法可以比放射科医师更快地解释急性神经损伤后的CT扫描,从而减少诊断延误 [1]。另一个好处是将繁琐和重复的工作自动化,例如检查多个淋巴结是否有转移性疾病的组织学证据 [1]。机器学习的实施还可以扩大某些通常需要专门技能服务的可及性,例如对糖尿病视网膜病变的视网膜扫描筛查 [1]。机器学习算法有望提供比人类更快、更一致的诊断,并最终改善患者治疗。
虽然机器学习有很大的前景,但也有固有的局限性,尤其是在诊断早期癌症方面。要理解其中的原因,重要的是应了解机器学习的工作方式。在医学中使用的大多数机器学习算法都是通过监督学习来训练的。在这个过程中,研究者会向计算机提供一些已经用外部标准标记过的图像,作为 “基础事实”。
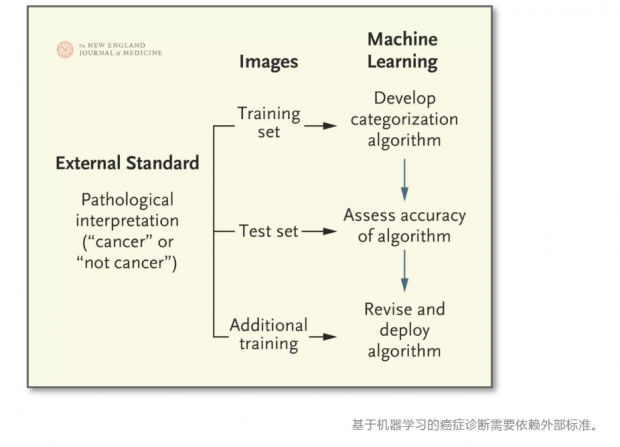
上图显示了利用组织病理学切片进行监督学习从而诊断癌症的简化版本。这个过程始于一组数字病理图像被病理学家标记为 “癌症” 或 “非癌症”,随后将这些图像分成训练集和测试集。计算机利用训练集开发能够在没有明确的说明或编程的情况下,根据模式(例如颜色、形状和边缘)最好地鉴别癌症或非癌症的算法。使用测试集来评估算法性能,测试集由计算机之前从未见过的图像组成。如果有必要,可以使用其他图像对算法进行微调。在这一过程的每一步,计算机系统都是通过判断其诊断是否合乎病理解读的外部标准来不断学习的。
然而,依赖这种外部标准是有问题的,因为机器学习并不能解决与癌症诊断相关的核心问题:缺乏组织病理学的 “金标准”。 “什么构成癌症?” 这个问题没有单一的正确答案。癌症的临床意义处于一个动态过程中:癌症是一种肯定会引起症状的肿瘤(通过局部浸润或远端转移),如果不治疗就会导致死亡。另一方面,病理解读是建立在静态观察的基础上的:癌症是根据单个细胞的外观、周围的组织结构以及这些特征与各种生物标志物之间的关系来定义的。
在病理学家中进行的观察一致性的研究中,缺乏金标准的问题很明显。譬如,关于前列腺、甲状腺、乳腺病变和疑似黑色素瘤的组织病理学诊断存在争议 [2-5]。很明显,病理学家对同一个病理切片可能有不一致的判断(特别是关于早期病变的诊断);目前尚不清楚的是,哪些病理学家正确地识别了具有临床意义的癌症。
在过去,当病理学家检查可以用手感觉得到的肿瘤时,缺乏标准的问题较小。根据病理解读诊断出的癌症是那些已经引起症状和死亡的癌症,或者是注定要引起症状和死亡的癌症。病理学家之间的不一致可能较少见。然而,现在病理学家被越来越多地要求对细微的、显微镜下才能看见的细胞异常做出判断。其中一些异常可能符合癌症的病理定义,但不一定会导致症状或死亡——换句话说,癌症可能被过度诊断。
使用机器学习算法进行的早期癌症诊断,无疑将比基于人类解释的诊断更一致、更可重复。但它们不一定更接近事实——也就是说,在确定哪些肿瘤注定会引起症状或死亡方面,算法可能并不比人类好多少。正如病理学家的共识不能解决过度诊断的问题,机器学习也不能。
事实上,我们有理由担心机器学习将加剧过度诊断的问题。配备了机器学习算法的设备可以在几秒钟内阅读切片,比任何病理学家都快几个数量级 [1]。使用这样的设备可能会比靠人来解读切片更便宜。这种组合将能够检查更多的组织切片,并可能鼓励临床医师对更多的患者进行活检。更高的通量——更多的组织,更多的患者——只会增加发生过度诊断的机会。
虽然可重复性有一定的价值,但医师不想冒自动过度诊断的风险。减轻这一问题的一种方法是利用医师关于病理诊断的分歧所显示的信息。换句话说,使用一个基于不同病理学家小组判断的外部标准,训练算法鉴别以下三种类型:一致认为癌症存在,一致认为癌症不存在,以及对癌症是否存在存在分歧。 我们认为,这一中间类别包含关于处于 “癌症” 和 “非癌症” 之间灰色地带的病变的重要信息。
让机器学习算法区分这三种类型有几个原因。首先,这样的分类方法将是高效的。通过机器快速分类切片,病理学家可以将精力和专业技术集中在组织学特征不明确的切片上,并且机器可以提醒他们诊断的不确定性,可能需要与同事会诊这些不确定的诊断。其次,这样的分类方法将是诚实的。在癌症诊断中强调灰色地带可以鼓励临床医师和患者在面对意义不确定的病变时考虑较保守的干预措施。最后,这种分类方法将是明智的。它应该促进对中间类型病变的自然史进行进一步研究,并促进更多的期待治疗研究。
在某些临床情况下,机器学习的分类将比 “癌症” 和 “非癌症” 这种分类更为复杂,例如前列腺癌的格里森(Gleason)评分:将世界卫生组织使用的5个格里森评分等级分组纳入机器学习算法,将需要15个类别来说明两个病理学家之间的一致和不一致。考虑到这种复杂性,研究者可能会质疑传统分级的细节是否与临床相关,或者是否应该将重点放在简化诊断分类上——例如,将前列腺癌分为低风险、中等风险或高风险。
与所有医疗干预措施一样,对癌症诊断采用机器学习既有好处,也有坏处。机器可以提高诊断的速度和一致性,但也可能加剧过度诊断。机器学习不能解决金标准问题,但可以进一步暴露这个问题。 最终,对患者和临床医师来说,重要的是癌症诊断是否与生命的长短或质量有关。我们认为,在这种技术被广泛采用之前,应该认真考虑训练机器学习算法来识别 “癌症” 和 “非癌症” 之间的中间类别的可能性。强调灰色区域的存在可能为病理学家提供一个重要的机会来讨论什么构成了癌症。
相关文献:
Adamson AS, Welch HG. Machine learning and the cancer-diagnosis problem — no gold standard. N Engl J Med 2019; 381:2285-2287
参考文献
[1] Topol EJ. High-performance medicine: the convergence of human and artificial intelligence. Nat Med 2019;25:44-56.
[2] Sooriakumaran P, Lovell DP, Henderson A, Denham P, Langley SE, Laing RW. Gleason scoring varies among pathologists and this affects clinical risk in patients with prostate cancer. Clin Oncol (R Coll Radiol) 2005;17:655-658.
[3] Franc B, de la Salmonière P, Lange F, et al. Interobserver and intraobserver reproducibility in the histopathology of follicular thyroid carcinoma. Hum Pathol 2003;34:1092-1100.
[4] Elmore JG, Longton GM, Carney PA, et al. Diagnostic concordance among pathologists interpreting breast biopsy specimens. JAMA 2015;313:1122-1132.
[5] Elmore JG, Barnhill RL, Elder DE, et al. Pathologists’ diagnosis of invasive melanoma and melanocytic proliferations: observer accuracy and reproducibility study. BMJ 2017;357:j2813-j2813.
文章来源于NEJM医学前沿

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号