博客
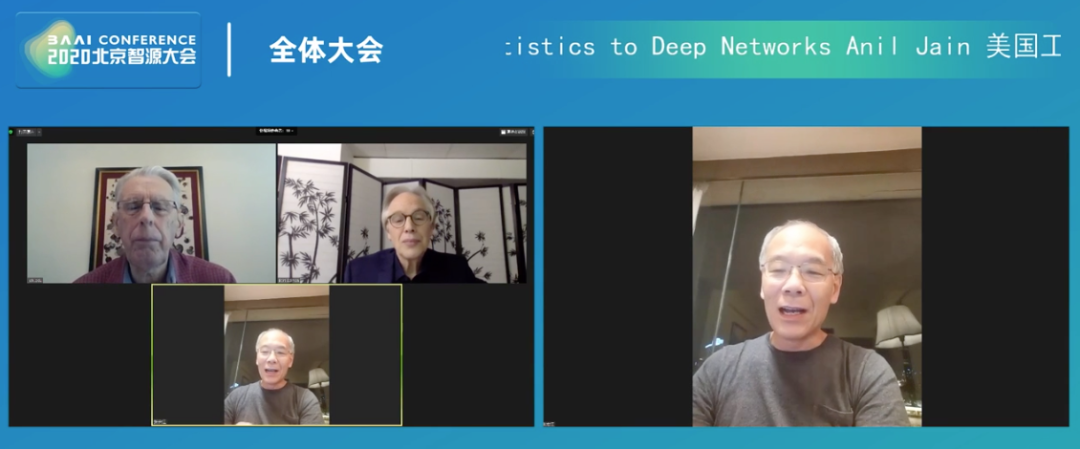
左上为图灵奖得主、智源研究院学术委员会委员 John Hopcroft;右上为 AAAI候任主席、美国康奈尔大学计算机系教授 Bart Selman;右图为智源研究院理事长,源码资本投资合伙人张宏江。回首人工智能的发展,深度学习无疑是过去十年的最大亮点,它在计算机视觉方面的突破性进展,使其几乎等同于人工智能。那么,未来十年,人工智能将朝着哪个方向前进?通用人工智能会在何时以什么样的形式出现?6月21日晚,在2020北京智源大会上,北京智源人工智能研究院理事长张宏江同康奈尔大学计算机教授 Bart Selman、图灵奖得主 John Hopcroft 就以上问题作出了回答。撰文 | 华 夏
责编 | 陈晓雪
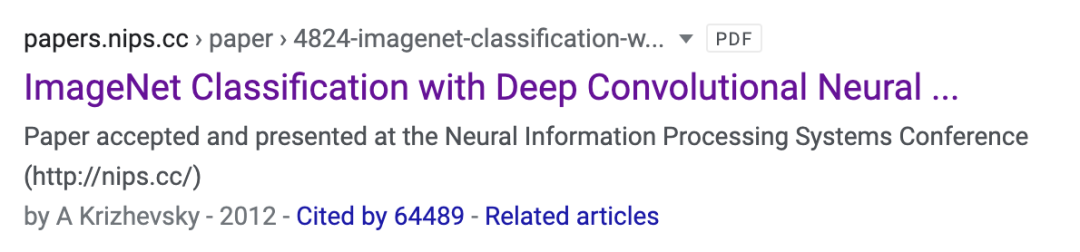
人工智能技术的出现可以追溯到二十世纪上半叶计算机学科创立之时,阿兰·图灵提出 “图灵测试”,讨论可计算性的边界。1956年达特茅斯会议上,AI 作为一个学科正式宣布诞生。但很长时间以来,人工智能都未能成功走出象牙塔,在产业和公共部门得到广泛使用,或成为人们日常生活的一部分。从1960年代的符号推理系统,到1980年代的专家系统,人工智能出现过几次破壳而出的迹象,但都未能成功变成产业级应用。6月21日晚,在北京智源大会上,北京智源人工智能研究院理事长张宏江作为主持人,同康奈尔大学计算机教授 Bart Selman、图灵奖得主 John Hopcroft 探讨了近年来 AI 的飞速发展和 AI 研究的未来:过去十年 AI 领域发生了什么?接下来十年 AI 又将如何发展?追溯这场革命,一个绕不开的时间点,是 2012年深度神经网络 AlexNet 在 ImageNet 大规模图像识别挑战竞赛中取得的惊人成就。彼时,使用8层神经元的 AlexNet 把图像识别的错误率从 25% 的水平大幅降到了 15%。自此,仅仅3年之后,人们就学会了训练多达100层神经元的深度神经网络 ResNet,将图像识别的错误率降到了3.6%。这个水平已然超越人类的水平(5%)。截至2020年6月,AlexNet 的论文被引用次数已经超过6万4千次。这是深度学习技术的惊人首秀。如今,深度学习几乎可以和 AI 划等号。深度学习的基础:人工神经网络,在1950年代已经出现,用于训练神经网络的反向传播算法(backpropagation)出现在1986年,用于自然语言处理领域的长短期记忆算法(LSTM)出现在1997年。但在过去的许多年里,训练数据和计算能力都十分匮乏。那时的研究者纵使有许多思路,也很难去验证。“在我获得博士学位的60年代初,我曾经参与手工制作了上千幅100x100 像素的符号图像,这在当时看来就已经是巨量数据了。” Hopcroft 说。但摩尔定律和互联网时代的出现终于改变了一切。到了2010年代,基于高性能 GPU 的计算和互联网上产生的大量数据,人们终于能大量训练深度神经网络,去验证自己的想法。这是过去10年 AI 飞速进步的主要原因。不过,因为深度学习技术的革命性成功,其他 AI 技术的应用被某种程度上忽略了。经典的 AI 技术,例如机器推理、规划、搜索等,在过去十年同样取得了很大进步。Selman 说, “一个很好的例子是 AlphaGo。它除了使用了基于深度学习的强化学习技术,也使用了2006年左右发明的蒙特卡洛树搜索技术。这是一个经典的、纯粹的符号逻辑算法。” 另一个例子是自动驾驶系统。虽然对街道上物体的识别技术来源于深度学习,但在设计交通路线的时候,还是需要依靠传统搜索、规划、推理等 AI 技术。Selman 认为,忽略非数据驱动的 AI 技术,可能会成为 AI 技术在未来十年取得更大突破的障碍。“如果说数据是大量标注好的图片,或者语音和文字的对应关系,那么知识就好比是牛顿定律,往往只需少数几条,就能解释大量数据。” Selman 说。数据驱动的 AI 技术虽然在许多应用领域非常有效,但仍然比不上人类学习的效率。人类学习过程是基于 “小样本” 的,Selman 说,“只需要几个例子,外加一些老师的指导,人类就能理解某个知识。”2019年8月,Selman 和现任国际人工智能学会(AAAI)主席 Yolanda Gil 共同起草了《美国未来20年人工智能研究路线图》( A 20-Year Community Roadmap for Artificial Intelligence Research in the US)。该白皮书强调未来的一个研究重点是 “有自我意识的学习”(self-aware learning)。 “某个人在学习某个科目,比如说微积分时,他对自己的知识掌握情况会有一个评估,他会主动提问,或者针对自己的弱项进行更多的练习。” Selman 解释道。这些是目前 AI 欠缺的能力。仅仅靠数据驱动的路径,虽然能让 AI 在一些领域达到接近或者超过人类的水平,例如人脸识别。但在另一些领域,比如自动驾驶,我们需要的是接近100%的安全性。Selman 认为,这最后的10%、5%的提升,可能不是深度学习本身的进展能够解决的,我们需要不同的思路。Selman 指出,深度学习技术除了在效率上的不足外,还有更多的问题。例如黑箱问题。深度学习算法通常只能给出判断,却不能给出判断的理由。假如基于深度学习技术的 AI 是考试的阅卷官,它虽然能够评分,却不能给出评分的理由,被评分的学生可能会非常不满。假如这样的 AI 系统要负责给出医疗诊断的方案,却不能让医生理解这个方案的道理,那么医生们可能会拒绝执行这样的治疗方案,病人也很难获得充分的沟通。此外,端到端(end-to-end)训练的深度学习系统,可能会过于复杂,使得工程师无法分别针对其组成部分进行质量测试。这对于需要极高安全性的自动驾驶系统而言就会成为一个问题。另外,数据驱动的 AI 技术还面临着数据偏见的问题。例如当前科技领域的从业者主要是男性,如果 AI 作为招聘官,可能会认为男性更适合从事高科技职业,从而拒绝合格的女性应聘者。这些偏见存在于数据之中,人类能够凭借自己对历史和社会的认识,去避免过分地看重某些经验数据。但目前的 AI 系统仍然大多处于 “偏见进,偏见出”(bias in,bias out)的状态,无法纠正训练数据中的偏见。事实上,在《美国未来20年人工智能研究路线图》中,Selman 对以上问题进行了更全面的回应。该白皮书确定了三个需要重点关注的研究方向:分别是(1)集成化的智能(Intergrated Intelligence),强调要将各种解决特定问题的 AI 技术模块组合起来,同时要建立 AI 能理解的人类知识库; (2)有意义的交互(Meaningful interaction)强调人机交互时的隐私问题,以及用户对系统的理解、信任和控制能力; (3)有自我意识的学习(Self-aware learning),强调小样本学习、因果推断、高稳定性的学习算法,有意图(intentional)的感知和行动。这三个方面均对目前深度学习之外的 AI 技术,或者深度学习的弱点进行了补充。在6月21日的会议上,Selman谈到,现在 Google,Facebook,Apple 等大公司吸收了大量的 AI 资源,包括有天赋的学生和教授 ,但商业利益导向的研究可能会忽略掉一些重要领域的需求,比如教育和医疗系统。他提议,美国在未来需要更多地支持学术界和非 IT 商业领域的 AI 研究,建立一个 AI 的国家基础设施,包括共享的数据集、软件库、计算资源等等,以便那些因为资金和影响力的原因而无法获得足够资源的行业也能为 AI 的发展做贡献。不过,这些努力是否能让我们在未来十年看到能够灵活解决各种问题、而非局限于具体任务的通用人工智能出现呢?在 Selman 看来,通用人工智能可能还需要20年以上的时间才可以实现。“不过如果我们在未来五到十年能在真正的自然语言理解上获得突破,使得 AI 可以去阅读图书,从互联网获得知识,那么这个进程可能会被大大加速。” Selman 解释道。同时,他表示对未来 AI 从数据到知识、从大样本数据训练到小样本知识获取的进步感到乐观。Selman 认为,技术是加速发展的。人类发展农业技术用了几千年,发展工业技术用了几百年,发展 AI 技术只用了几十年。我们现在有了更高效的编程语言,更方便的计算设备,大量的数据,基于互联网的高效知识共享,以及产业界的大量投资,技术的进步将会越来越快。我们无法在短期内达到通用人工智能的原因,Hopcroft 补充说,是因为目前的 AI 研究普遍是具体工程指标驱动的,人们花了很多精力,在特定的领域去改善算法的表现。他认为,我们需要更多好奇心驱动的研究,需要更多地回到基础科学问题上来。“未来人工智能领域重要的突破,可能并非来自计算机科学专家,而是生物学研究者。” Hopcroft 说,毕竟人类现在对于人类大脑进化历程和儿童大脑发育机制知道得仍然非常有限。这也提醒了我们人工智能这一学科成立的初衷。我们并非只是为了获得工程上有效的算法。我们希望能理解人类的心灵。如费曼所言, “我造不出来的东西,我就没有真的弄懂。”(What I cannot create,I do not understand.) 

话题:

财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。







 京公网安备 11010502034662号
京公网安备 11010502034662号