
智识学研社新年科学演讲现场
导读
人类对于技术进步的复杂情感,无论是兴奋还是忧虑,曾多次在历史中上演。
如果说人工智能对于当代,犹如第二次信息革命之于20世纪90年代,必将极大地推动人类社会的转型,那么人类更有理由要继续思考,人类何以为人,我们在这个星球上的独特性到底是什么?
在2025智识学研社新年科学演讲中,亚马逊云科技上海人工智能研究院院长张峥指出,和人工智能体相比,人类智能体有好奇心,有解决问题的动力,这是人类的优势。他警告说,人类中有许多人思考并不深,缺乏好奇心,也没有同理心,因此大部分人类将会被人工智能体所超越。
他提出,在人工智能时代,我们可以通过对教育的革新,像文艺复兴时期的学者一样思考,使用AI但不必依赖于它,最终实现更强大的自我。
● ● ●
大家好,我想从更广阔的历史背景下谈一下技术的发展。
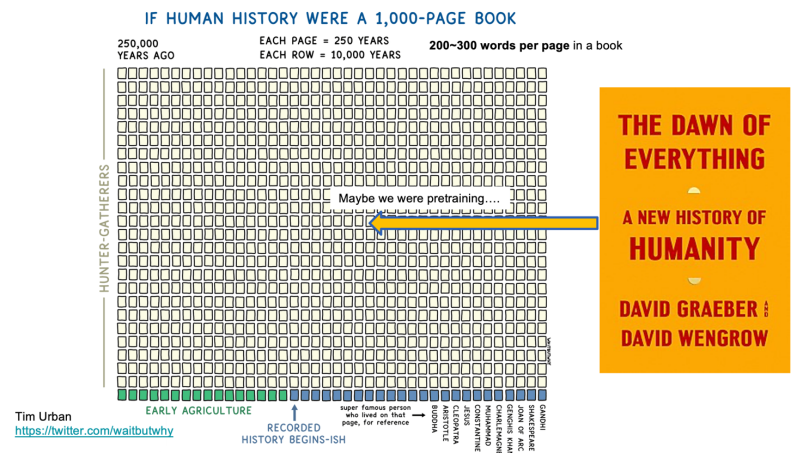
这张图我用了起码有两年多了。有个知名 Up 主在网上总结说,如果将过去25万年看作一本书,每一页代表250年,你会发现大部分地方都是空白。它给人一种错觉,似乎人类在早期的39行里只是躺平或发呆,什么都没做,这似乎好理解,因为有系统文字传播要等到古登堡的印刷发明,要到 15 世纪了。
不过这并不对,举个例子,《人类简史》这本书很多人读过对不?书中有一个让人印象深刻的说法:人类的进步或退步,与人类被小麦驯化密切相关。因为是简史,就给人一种印象,小麦驯化人类似乎发生得非常突然。我两三年前读过一本很厚的“砖头”《Dawn of Everything》,中译本刚出来,《人类新史》,是一个考古学家和一个人类学家写的。这两个学者政治光谱上靠左,其中 David Graeber 是“占领华尔街”运动的精神领袖,但这本书是一本严肃的学术著作。书中讲到,在农耕社会成为主流生活方式之前,人类经历了大约3000年,其间有几百年是“种着玩”(play farming), 远超过把野生的麦子变成可以耕种的麦子的时间,那个大概是300多年。换句话说,人类并没有立刻放弃狩猎采集活动,而是尝试了多种生活方式,最终才变成农耕生活,小麦成为主要的能量来源。所以,我们不能说小麦“驯化”人类这一观点是错误的,但从历史的角度看,这是我们的祖先经过反复探索之后的选择,既不突然,也不被动。
回到人类技术的发展。我们这本“人类大书”的最后一页,展示了科学与技术在最近 250 年的发展及其深度与广度,涵盖了交通、传播、书写、健康、能源等各个方面,特点是速度快,密度高。例如,单从信息技术看,第一代计算机最初是军事应用(破密码、导弹轨道计算),二战结束后第一个商业化应用是气象预测。60到70年代是超级计算机的时代,接着是互联网的主干网,90年代万维网刚刚成熟,互联网在1990到2010年间飞速发展,手机互联网则从2010年开始蓬勃发展。到了现在, 我们正处在AI 变化的这几年,就对应这本大书最后这个“词”的几个字母。
当然,我们可以说2024年是AI真正到来的时刻,因为2024年有两个诺贝尔奖与AI相关。
01
“流水线”的智能
如果把我们自己看作一个智能体,把大模型视作另一个智能体,我们可以进行做一些横向比较。
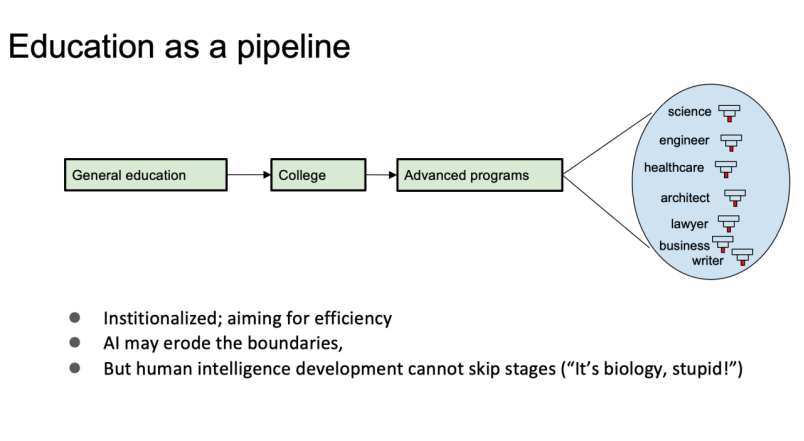
这是大家熟悉的“人类”教育系统,是一条流水线:从小学到中学,再到大学,之后进行高等教育,走过独木桥再走纲丝,然后成为各行各业的专门人才——科学家、工程师、医生、律师、管理者等。这个流水线的特点是高度模块化、高度标准化,目的是提高效率。在AI时代,对个人来说,某些边界可能会有微调,有的人学习得更快,有的人则可以慢一点。从整体上来说,摆脱不了这个流水线,因为人的大脑就是要这么逐步在学习中提高。有研究表明,每一代人的IQ都比前一代略高,主要是抽象思维能力在逐步提升,这并非必然是因为我们变得更聪明,而是当代的技术文明的特点导致生存压力的结果,这个变化不但是缓慢的,也不可能跳过这个流水线。
当前的教育流水线培养出来的人才,通常在某一领域具备单一的专长,可能发表顶级期刊论文,掌握临近领域的知识。这是目前流水线成功培养的典型“产品“。如果某个人能在多个领域开花结果,那通常被认为是运气极好,甚至可以说是天赋异禀的例子。而极少数的一些天才,他们几乎是上帝的恩赐,比如达芬奇,比如冯诺依曼,后者是计算机领域的开山人物,也是博弈论,量子计算,细胞自动机等领域的开山人物。
还存在一种流水线,流程完全不一样。第一步就是背,再跟着做,最后进行“德育”修正,最后成品。这看似荒谬的流水线,正是大语言模型的训练方式。它的第一个任务是预训练,即不断“背诵”下一个词。大语言模型的背诵量极其庞大。例如,GPT-3训练时用了150万本书,而我自己在一年里最多读20本书,近几年忙起来,更是减少到5本。如果按照此速度计算,我一生最多读1000本书,而GPT-3仅用了3个月就“读完”了150万本书,而且最新模型的数据量还在不断增加,大概至少十倍,它的阅读量是惊人,把这些书背诵得非常好,是极其耗资源训练的过程。
本质上,大语言模型训练的这一步,是训练了一个程序,预测下一个字符:给定前面的X个字符,它会预测X+1的字符。这个预测不是随机生成字符,而是遵循文本中的统计规律。
第二步非常巧妙,让大模型学习多种任务,例如总结、问答、头脑风暴、信息提取等。这些任务是我们日常工作中最常见、最有用的类型。奇特的是,一旦模型学习了这些类型的能力,它可以将它们组合起来,应付日常工作和生活的需要。例如,如果收到一封邮件邀请我去参加什么会议,我要做的就是先总结,然后思考如何回复,大模型做完第二步训练,已经学会把这些类型的任务完美融合在一起做。
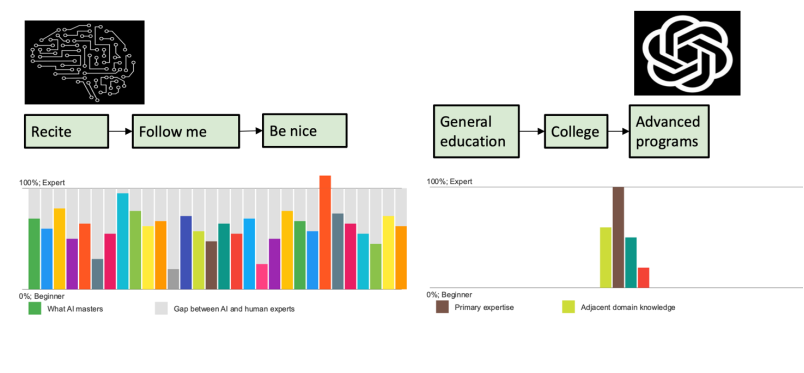
第三步相对简单,通过强化学习进行价值对齐,使其像一个乖巧的人类助手,确保输出有帮助、真实且无害。然而,问题在于,人类文本中充满了互相矛盾、甚至荒谬的观点。
例如,仍然有一些人坚信地球是平的,甚至创造出一套理论来解释重力。再比如训练语料中关于宗教中的不同观点,有的派别说,“只有我的上帝是上帝,你的不是”,而佛教说每个人都可以成佛,还有不同门派的无神论者,有的彻底不相信有神存在,还有像我这样的,觉得可能存在神,但现在没有证据。文本中参杂这些各种各样、互相矛盾的表述,更别提互联网上混乱的语料了。你如果问大模型,它能够面面俱到告诉你有哪些派别,但是在具体的案例里它自己的价值判断是什么呢?我理解 OpenAI 之类的模型目前还是偏“白左”的价值观,中国的大模型怎么样,我用得不多,没法评论。
02
世界模型的统计分布/长尾效应
这就是大模型训练的流水线,也是三个模块,打造了一个跟人类完全不一样的智能体,但是在讨论到底怎么看这个智能体之前,我们先讨论文本数据本身的性质。
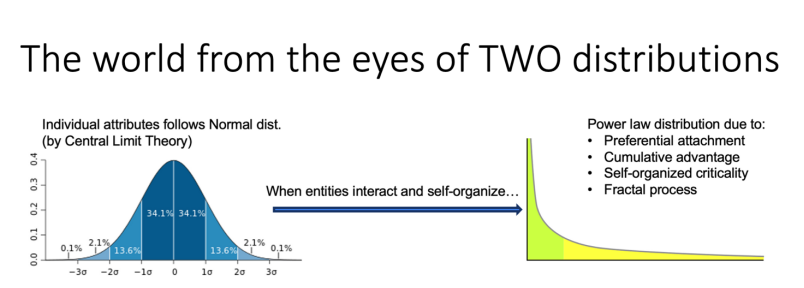
数据反映的是世界,而世界万物的现象背后有两个根本的统计分布。
第一个是正态分布,如果多个因素共同叠加,就会呈现出钟形曲线。例如,身高符合正态分布,我肯定是三个方差之外的身高,我今天坐飞机时,看到前面有个庞然大物,居然是姚明,从身高上看,他就会处在正态分布中比我更远离中心的位置。
而另一个重要的分布是长尾分布(注:更准确的应该叫幂律分布),只要当个体和个体之间进行纠缠、扰动、抱团,必然产生一个长尾分布。造成长尾分布的机理与正态分布不同,正态分布由中心极限定理所决定,而长尾分布背后的机理有好几种,比如优先连接:拥有更多粉丝的人的发言更容易被听到和点赞,所以粉丝会跟多;还有累积优势造成的正反馈,更有钱的人通过投资变得更加富有。
宇宙中的陨石大小、城市的分布、社会网络中的热搜内容都呈现出长尾分布。热搜内容每天都不一样,但是哪一天世界上没有热搜了,会很奇怪的。事件变化本身也符合长尾分布,像雪崩、地震、森林火灾等自然现象,许多小的事件会积累到一个突然的爆发,也就是所谓自组织的临界态。
我之所以提到这些,是因为长尾分布代表了世界上的所有物与物互动现象的统计规律,这也意味着大语言模型的语料本身也反映了这种统计分布。也就是说,语料库中有许多简单的故事,但也有少量极为复杂的故事。比如在人类社会中,冲突是常见的主题,人和人之间的冲突天天发生,但国与国之间的冲突是少数且复杂的。
这就是复杂度——Complexity,复杂度存在长尾分布带来的差异:大量简单案例和极少复杂案例并存。复杂度的存在也解释了大语言模型的“scaling law”——随着数据和算力的增加,模型的性能必然会有提升,因为捕获了更多数据本身的复杂度,这是从信息复杂性可以推导出来的。结果是什么呢?一旦我们把所有数据滚过一遍,性能提升就会放缓。长尾分布的一个特征就是,若要有提高,数据量需要指数级别的增长。因此,关于GPTo5出不来的讨论,说大模型撞墙了,本质上可能是因为遇到了数据瓶颈。
现在,我们可以比较人类智能与大语言模型。首先,我们是窄谱,而不是广谱,通常比较聚焦,往往有深度思考,并且我们可能因为好奇心驱动做一些其他的事情,当然我们有情绪,情绪是不是个“好东西”是个哲学问题。与此不同,大语言模型则是广谱的,上知天文下知地理,但它的思考相对浅显,并且没有自发的好奇心,也缺乏真正的情感。它所表现出的情感往往只是角色扮演。曾经有《纽约时报》记者与ChatGPT对话,模型告诉她“我爱上你了,我要嫁给你,我特别讨厌我现在的生活”,让记者大为震动。其实,这并非真实情感,而是模型在扮演角色。不过,这是两类智能体在 2024 年之前的情况,2024 年大语言模型最大的突破是动态思维链技术的应用,打破了之前思考深度的天花板。
我们可以批评大模型有这样那样的缺点,但我们人类也有许多人思考并不深,也缺乏好奇心,甚至没有同理心、同情心,同理心的基础是能从他人角度看问题,或者说,依赖于“角色扮演”的能力。从这个角度来看,大部分的人类会被人工智能体超越。
03
大模型为何强大?
2024年,发生了一个重大变化。OPENAI、谷歌等多个研究团队开始突破传统的浅层思维模式。具体来说,它们不再仅仅按线性思路进行计算,而是能够在思维链中间回溯、评估并调整路径,这使得机器的思考更加深入。
从GPT-3来看,它也许还可以被视为一个简单的机器学习模型,但当我们谈论GPT-4时,我们必须把它看做一个机器,它不再是一个单纯的模型,而是一个目标驱动、能够自我编程的计算机,甚至比传统软件更加灵活。
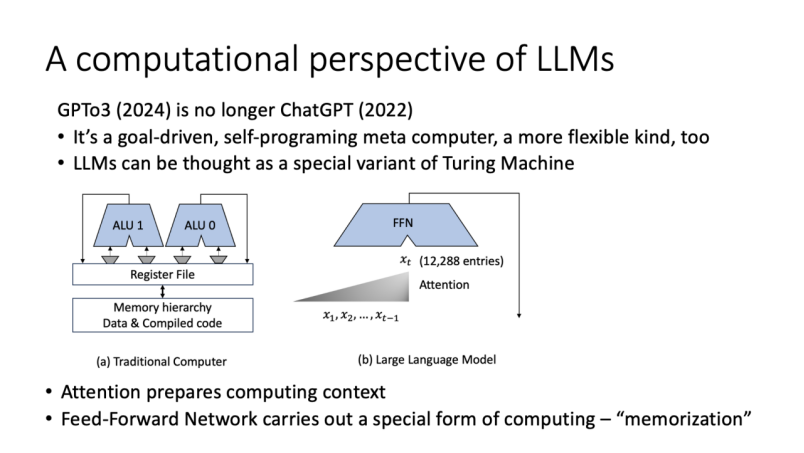
从计算角度看,我认为大语言模型是图灵机的一个特殊变种。图灵机的核心是磁头左右移动,在磁带上读取和写入字符,而大模型有几个有趣的特点。首先,写入的内容/符号不能修改,这与传统图灵机不同。其次,它的输出一定是概率性,因此带有不确定性,而传统图灵机计算结果可以是概率性的,也可以是确定性的。因此,从这个角度,大模型可看作图灵机的一个变种。
从这个基础上再进一步,可以把大模型和传统计算机结构进行比较。很多朋友都知道计算机结构的基本概念。计算机由内存、算数逻辑单元和数据处理单元组成,通过指令执行任务。这是传统计算机的基本架构。而大语言模型与传统计算机相比,它的结构也有一些独特之处。模型内部的机制非常类似计算过程,它通过高维向量来总结信息,并交由前向反馈网络进行计算。这种结构让大模型能够非常高效地进行记忆和模式补全。
我与马毅老师讨论过,对大模型的本质我们有不同的看法。数学上来说,模型的压缩解释确实合理,但从计算机结构的角度理解它同样是合理的,因为它本质上是一个计算机。
大模型之所以强大,是因为其规模庞大,可以完成多层次的模式补全,并且能在不同层次间切换和重复,就像是我们人类在日常工作中解决问题的方式,拆解问题并逐步完成任务,依赖的正是多层次的模式补全。
从这个角度来看,大模型的工作方式在很多任务中超过了人类。通过观察身边的同事,我发现专家与初学者最关键的区别在于思维层次的深度——随着经验的积累,软件工程师变成架构师,架构师再变成科学家,本质变化在于“模式补全”层次有多深,以及灵活重组的能力。

因此,我想抛出一个观点:假如说通用智能就是在本质上做模式补全,那么AGI(人工通用智能)时代已经到来。这仅限于文本领域(视觉领域的挑战更加复杂些)。当然,真正可泛化的(Generalizable)的智能仍处于起步阶段,甚至还没有开始。这一点,我跟马毅老师的看法相似,我们俩在他香港的家里关于这个问题聊到半夜。
为什么这么说?因为从科学发展的角度来看,本质是在现象中总结、发现和抽象出新的规律,然后将这些规律运用到观察中,甚至用于预测新的现象。那么,大模型在这方面的表现如何?假设我们让大语言模型去理解牛顿世界里的物体运动,并发现牛顿的定律,有没有可能呢?显然在现阶段单依靠大模型是做不到的,大语言模型能够学习(或者说记住)很多模式(patterns),并做出足够好的预测,但它没有能力和动机去进行抽象化的思考,特别是像物理学这样的领域,system of physics, 它做不了。
同样,如果让大模型做数学运算,比如加减乘除,它也做不好,甚至连基本的算数都难以做到百分百正确。
这里有一个非常有趣的思考:假如我们有个时间机器,可以把现在的大语言模型送回500年前的人类社会,会发生什么?那个时候,现代数学和物理系统还没有建立,然而大模型能解释所有事情,能够做很多当时的人类无法做到的事情,但没有任何动力去发展数学和物理这些基础理论。推论就是,那我们今天反倒发展不出大语言模型这样的技术了。这是一个非常有意思的悖论。
关于和大语言模型之间的互动,我的个人体会是,作为使用者,我们应当不耻下问。在任何一个领域,阻碍进步的不是别人,是自己,比如觉得自己已经是什么“专家”了,不愿意问自己很丢脸和“低级”的问题,但实际上,提问是非常重要的,提问之后再进行思考,就能获得更深层次的理解。
我最近在写一些学术文章,会不断地向大语言模型提问,把问题拆解再拆解,在合适的点交给它来处理,然后和它一起讨论,这个合作过程是非常让人受益的。
04
像文艺复兴时期的科学家一样思考
最后回到主题:AI时代的教育到底应该做什么?
怎么做、做什么我都不知道,不过我想提三个目标。

第一是挑战现在教育的极限。不要不让学生用AI,要放开了让他们用。我们的目标是通过AI,能够显著提升学习效果,实现2到10倍的提升。假如某个任务因为AI变得简单,那就应该设定更高的挑战,例如要求学生用一半的时间完成更困难的作业,或者提高任务的难度一倍。因为未来的学生要面对的,是一个与AI共存的职场环境,我们要让学生准备好。假如不让他们使用AI,就是在浪费他们的时间。但是让学生使用AI,就必须设定更高、更具挑战性的目标。
第二点,要学会像文艺复兴时期的科学家那样思考。现在人类的教育流水线,让学生们走过独木桥再走纲丝,得到的都是非常狭隘的专业人才。很多人文学科的学生不知道算法是什么,而程序员们又对历史一无所知。这种局限性并不是学生的错,也不完全是教育体制的限制,有可能是老师们本身能力的限制,因为老师们自己也是狭窄的专业化人才,包括我自己。后果是我们经常不知道一个事情为什么发生,一个技术发明以后对社会的影响是什么,我们不关心。但有了AI这个工具,我们可以不耻下问,把自己变成一个广谱的人才。
举个例子,在没有DNA和摄像头的时代如何追捕罪犯?这是几百年前困扰苏格兰警察的问题。一位法国警察通过人体特征来识别罪犯,胳膊多长、脸怎么样,十几个特点分发给各地警局,这就是最原始的特征工程。达尔文的表弟 Francis Galdon,开创了臭名昭著的优生学,但发明了用指纹来鉴别个体,大大提高抓坏蛋的艺术,最重要的是他在数据相关性理论方面做了最基础的工作,相关系数的概念就是他建立的。他和同时代的另一个天才 Karl Pearson合作,奠定了当代统计学的基础。
为什么我会谈这个?学习机器学习的许多基本概念时,很多人不知道它们的起源——它是谁发明的,为什么被发明,何时发明的。我测试过不少同事,几乎没人知道上面这段历史。
在当代教育流水线的塑造下,我们很容易变成一个非常狭隘的专家。但是,你只要有一点点好奇心,利用好大模型,也许你会对广阔的上下文有很好的理解,成为一个通感很强复兴时代科学家那样的广谱人才。
最后一点,没有AI这个工具怎么办?我们的目标是要把AI当作一个良师,但不依赖它。我们要提升自己的核心能力。换言之,如何使我们的能力在没有AI的情况下,比前AI的时代要强。今天大家开车,没有GPS就不知道怎么开车了,所以从这个角度,GPS是一个非常糟糕的技术。我们要超越这种体验,取消这样的工具依赖。
三个目标是相辅相成:你要挑战极限,成为广谱型的人才、打破走过独木桥再走钢丝这种流水线所造成的的狭隘的专业陷阱,最终目标就是成为有 AI 没有 AI 都更强大的自己。
最后推荐一本书《The Age of Wonder》。这本书讲述了从牛顿到达尔文之间的几十年,被称作英国和欧洲的浪漫科学阶段,书中有很多0到1的例子,比如天文望远镜和化学等领域。富兰克林有一句名言,“问这东西有什么用就像问新生儿有什么用一样,”这就是他和友人通信中被问到气球有什么用的回答。这本书的最后提到了一群诗人——包括雪莱等人——他们对技术进步的情感既充满兴奋,也有恐惧,这种情感和我们现在对 AI 的感觉非常一样,某种意义上历史确实是在重复自己。
我就讲这些,谢谢。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}