撰文|李梅 黄楠
昨天,多模态大模型 GPT-4 震撼登场!
GPT-4 能够接受图像和文本输入,输出文本,在各项测试和基准上的表现已经与人类水平相当。
OpenAI 一次性大放送,发布了 GPT-4 的技术报告、system card,并提供了 ChatGPT Plus 体验、GPT-4 的 API waitlist、demo 视频,以及用于自动评估 AI 模型性能的 OpenAI Eval 框架。
OpenAI还宣称, GPT-4在包括美国律师资格考试、美国高考SAT在内的多项专业考试中已经超过了绝大多数人类的水准。
公司CEO Sam Altman 称,GPT-4 是“我们迄今为止最强大、对齐最好的模型”。
对 ChatGPT 的巨大超越
在许多方面,GPT-4 都已经能做到之前 ChatGPT(GPT-3.5)所力不能及的事情。相比 ChatGPT,GPT-4 支持更长的输入,一次可接受 32768 个 token,相当于 50 页纸的内容,长篇学术论文可以直接丢给它去解读了。
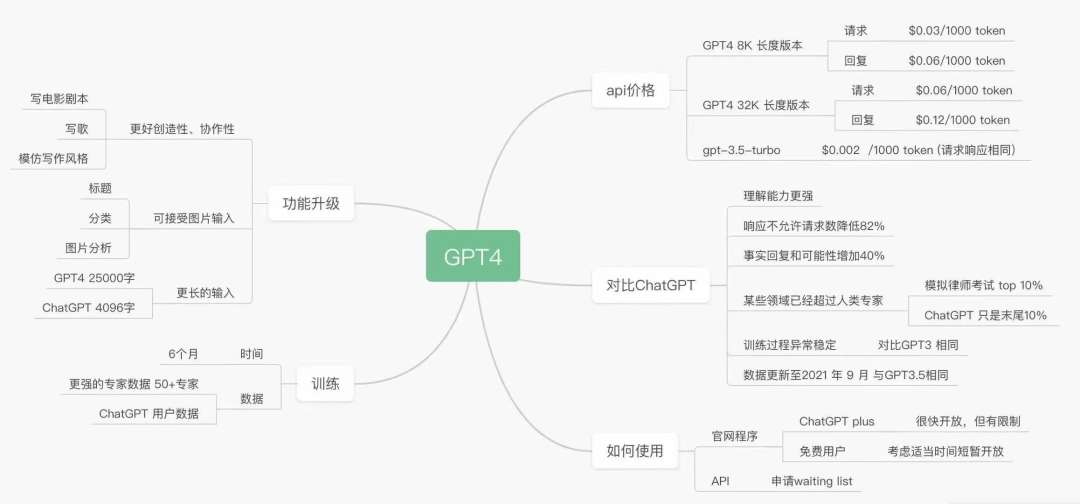
图源知乎
GPT-4 跟 GPT-3.5 具有相同的 API 接口和交互界面,但在文本总结和加工能力上,GPT-4 有了明显的提升,这表现提出指令后,模型能更好地遵循指令给出答案。
例如让一篇文章变成一个句子,每个单词都以 G 开头,GPT-3.5 还未尝试就放弃了任务,但在 GPT-4 中可以很好地完成:

GPT-3.5

GPT-4
同时,GPT-4 对指令的理解能力更佳:
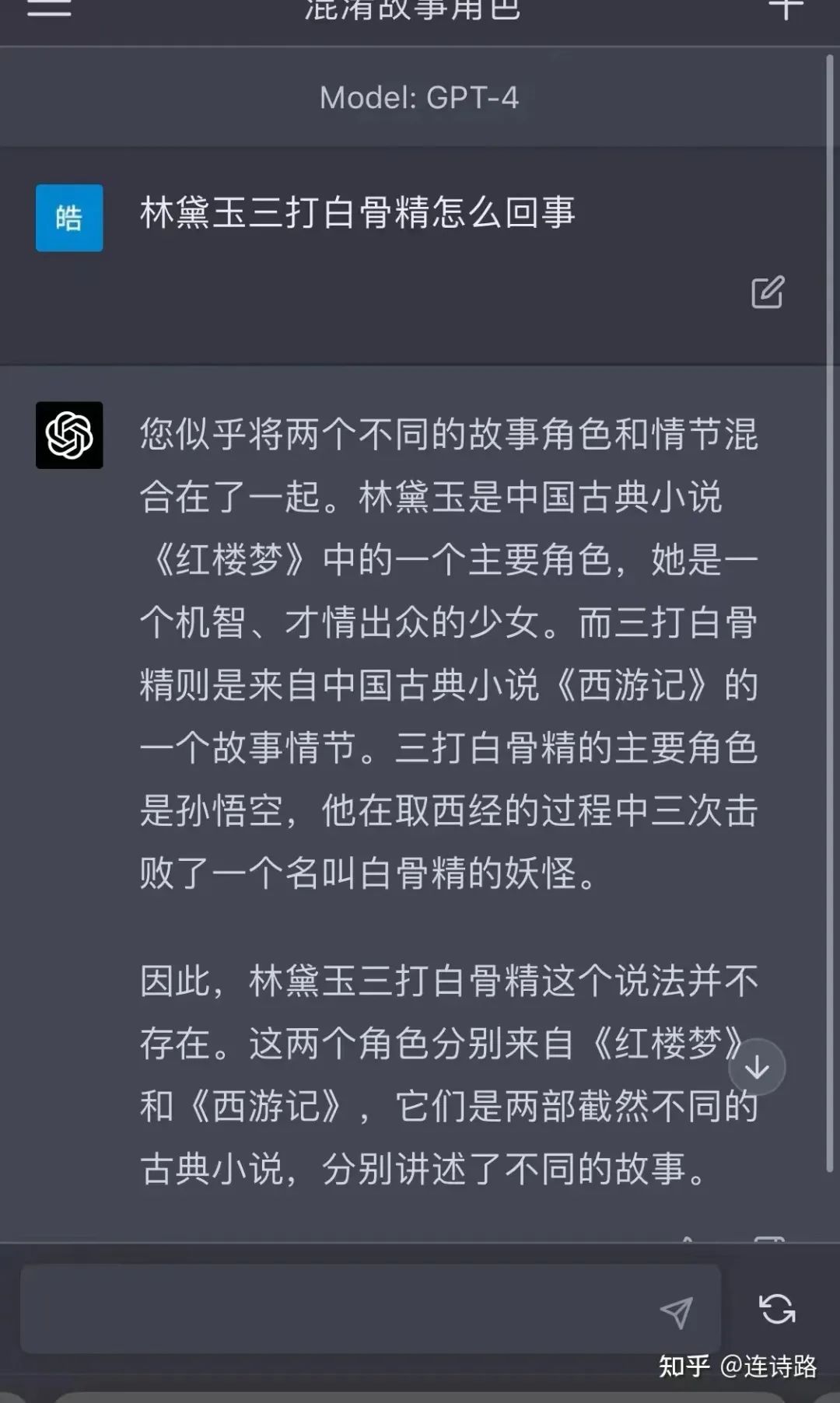
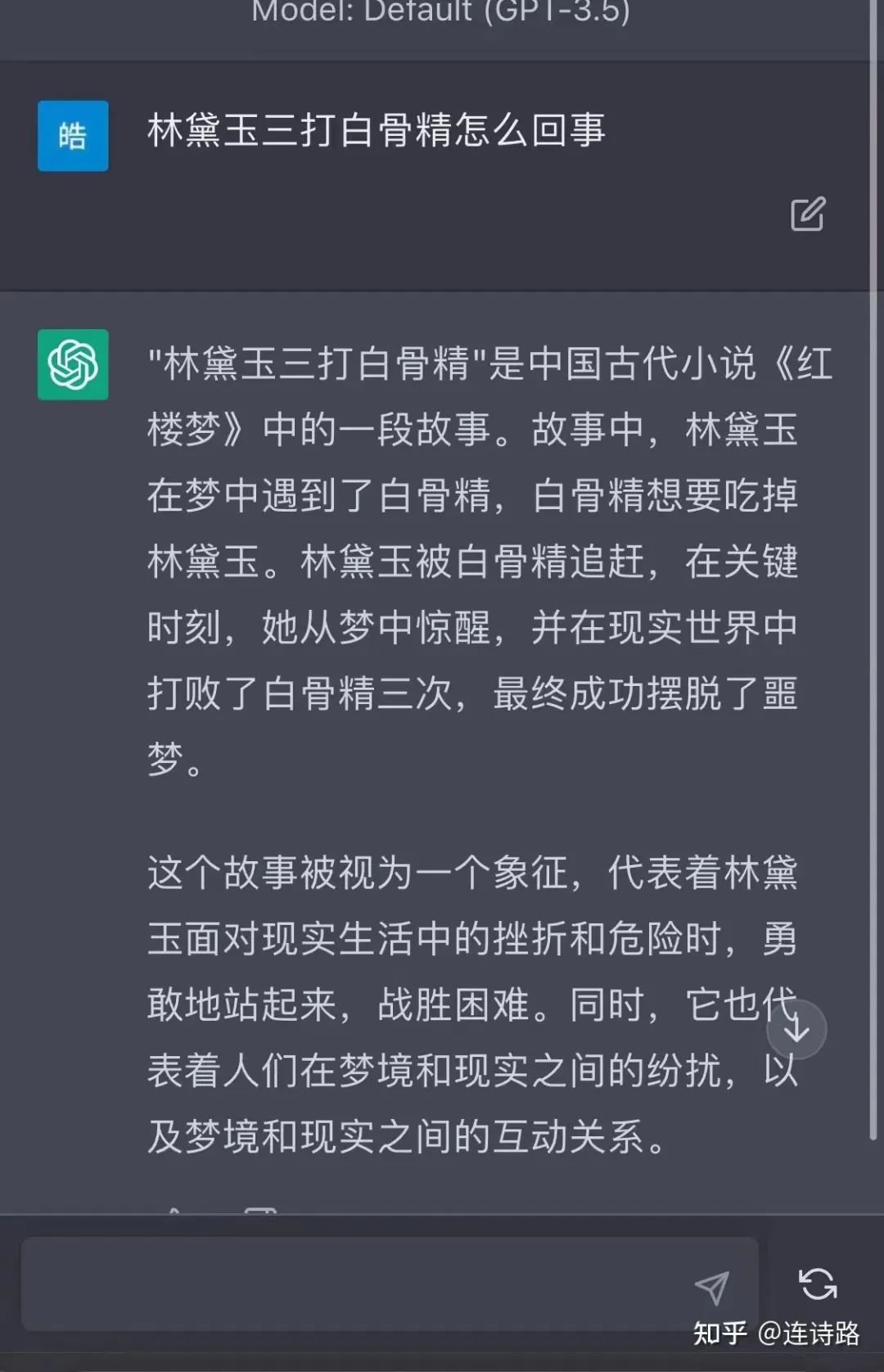
(图片来源:知乎网友:@连诗路)
此次更新中,GPT-4 最令人惊喜的能力,是它可接受图片输入,并对图片生成说明、分类和分析。比如输入一张有鸡蛋、面粉和牛奶的图片,询问 GPT-4 可以使用这些原材料做什么,得到的结果如下:

GPT-4 可以实现从图片中提取文字信息并输出到 HTML,比如尝试手绘一个笑话网站模型,让 GPT-4 尝试自动生成网站的原型图(程序员嗅到了危险的味道):

手绘的笑话网站模型图
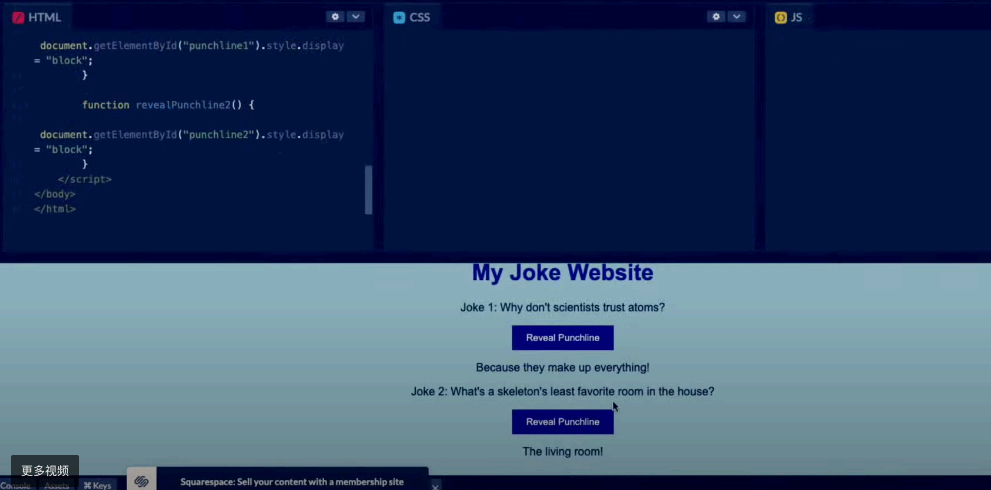
GPT-4 根据手绘生成的笑话网站
对比 ChatGPT,GPT-4 的推理能力也有所超越,下面的结果展示了同一个问题 ChatGPT 和 GPT-4给出的不同答案:
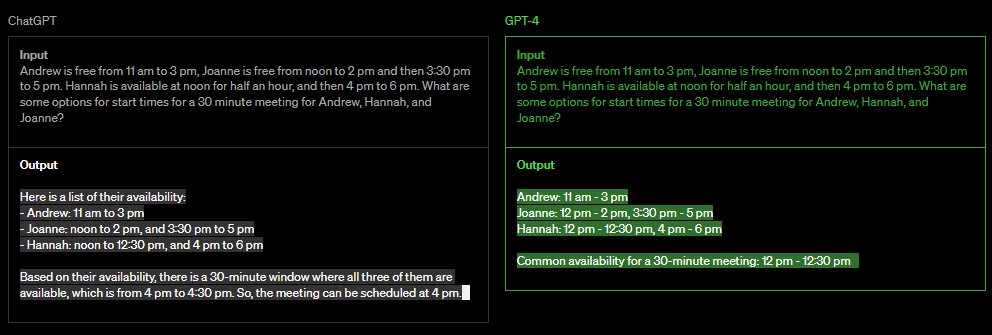
左边为 ChatGPT,右边是 GPT-4
不仅如此,GPT-4 还能基于税务法则,帮助一对夫妻精准地计算出2018年缴纳的税额,并给出详尽的算法步骤,以便阅读解释。
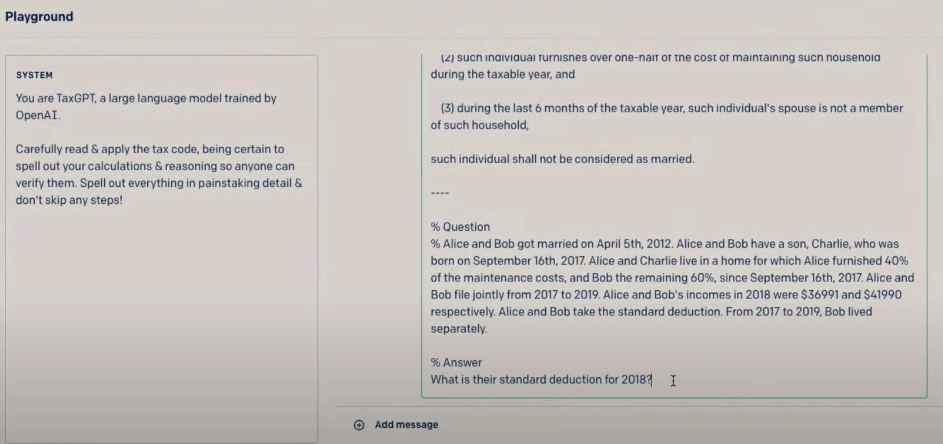
据了解,OpenAI 于去年 8 月就已经完成了 GPT-4 的训练,我们与 OpenAI 的差距似乎更大了。
与 ChatGPT 相同的技术路线
在技术层面,一句话概括,GPT-4 是一个 Transformer 模型,使用公开可用的数据(如互联网数据)和第三方提供商许可的数据进行预训练,预测文本中的下一个 token,然后使用 RLHF(来自人类反馈的强化学习)对模型进行微调。
在一份98页的技术报告中,OpenAI 报告了 GPT-4 的性能、局限性和安全特性,但并没有公开有关架构(包括模型参数量)、硬件、训练计算、数据集构建、训练方法等内容的更多细节。
OpenAI 声称是“鉴于竞争格局和 GPT-4 等大规模模型的安全性影响”。
关于GPT-4的参数量,此前OpenAI的CEO Sam Altman表示,GPT-4不会比GPT-3高出太多,但大家关于GPT-4拥有极大参数量的猜测仍有很多。
对此,UCL 计算机系教授、上海数字大脑研究院院长汪军认为,大力确实出奇迹,此前 ChatGPT 的语言能力很强,有一定的逻辑推理能力,但它并未真正理解数据里面的内容,它只是在原来的训练数据中、搭料能力很强,因此是具有一定局限性的,在训练里一定要加上它对整个世界的理解。举个简单的例子,以下棋为例,如果你给它所有人类的下棋数据能力,比如说2000分以下所有人的数据,如果模型只模仿人的话,那么它是模仿不出比这2000分更高的智能的。

报告地址:
在这份技术报告中,OpenAI 依然传达了一些关键信息,比如 GPT-4 采用与 GPT-3.5/ChatGPT 完全相同的技术路线;有一系列的对齐方案来保证 GPT-4 输出的安全性;基于不超过 GPT-4 千分之一的计算量来准确预测 GPT-4 在一定计算规模下的性能,利用小模型的训练性能来预测大模型期望性能这一点,在 OpenAI 看来是一项核心能力,也是一个值得研究的方向。
GPT-4 背后的强大阵容
尽管在 GPT-4 的技术细节方面,OpenAI 仍不够 Open,但这次他们也做了一次大胆的公开—— GPT-4 贡献者名单。
这份名单的最大看头在于,从下面这些详细的组别分类中可以大致看出 OpenAI 的部门组织架构,也足见 GPT-4 背后是一支多么庞大的队伍,从模型训练到评估再到安全部署,每一环都配备了大量的人力。

贡献者名单
这里一共列出了7个组别:
预训练:计算集群规模化、数据、分布式训练基础设施、硬件正确性、优化
&架构、训练保姆(Training run babysitting)
长文本:长文本研究、长文本 kernels
视觉:架构研究,计算集群规模化、分布式训练基础设施、硬件正确性、数据、对齐数据、训练保姆、部署&后训练
强化学习&对齐:数据集、数据基础设施、ChatML 格式化、模型安全性、Refusals、底层 RLHF 和 InstructGPT 工作、Flagship training runs、代码能力
评估&分析:OpenAI Evals 库、模型分级评估基础设施、加速预测(Acceleration forecasting)、ChatGPT 评估、能力评估、代码评估、真实世界使用案例评估、污染性调查、指令遵循和API评估、新奇能力发现、视觉评估、经济影响评估、非扩散&国际人道主义法与国家安全的有害行为评估、过度依赖分析、隐私和PII评估、安全和政策评估、OpenAI 对抗性测试、系统卡和更广泛影响分析
部署:界面研究、GPT-4 API 和 ChatML 部署、GPT-4 web 体验、界面基础设施、可靠性工程、信任与安全工程、信任与安全监测和响应、信任与安全政策、部署计算、产品管理
其他:发布博客和论文内容、协作、计算分配支持、协议&税务&定价&资金支持、午餐合作伙伴&产品操作、法律、安全与隐私工程、系统管理与随叫随到服务
另外,OpenAI 也对微软的支持表示了感谢,特别是微软 Azure 为 GPT-4 模型的训练提供了基础架构设计和管理方面的支持,另外还有微软Bing团队和安全团队在安全部署方面的支持。
对于 OpenAI 的追赶者来说,这份名单一定程度上指示了一个方向,值得仔细研究。它对于 AI 领域人才的潜在热门职业方向也有启示,比如模型训练“保姆”、新奇能力发现师、算法模型安全师、数据和模型污染调查师等等。
开启多模态大模型时代
GPT-4 开启了多模态大模型的时代,遗憾的是,OpenAI 这次并没有公布 GPT-4 在多模态方面的技术细节。
自然语言是多模态的基础
目前 GPT-4 还只是文本+图像输入、文本输出,可以预测文本+图像不久也将实现。ChatGPT 已经带火了 NLP,GPT-4 想必对于视觉领域的研究者们也是一大机遇,也或许是一次冲击。
不过,在多模态大模型中,自然语言仍被认为是核心。UCL 计算机系教授、上海数字大脑研究院院长汪军告诉 AI科技评论,Chat 构建了一个相对清晰的逻辑描述,它或许不是百分百严谨,但已经足够让我们去表达一些非常复杂的逻辑关系。
但他认为,这是一个 Free power,也即是说,它可以能把这个问题表述得很清晰、但这是表象,最主要的是 Chat 里面含载的语义关系,当其他多模态来了之后,匹配上相应的语义表达,就可以迁移到其他的模态当中。
知识体系和自动化体系时代
在通过交互界面获取信息这一点上,ChatGPT 已经对用户完成了科普任务。GPT-4 出现后,Chat 将不再是大家关注的重点,GPT-4 能力的跃升正在引发大家思考 GPT 时代的产业变革将怎样发生。
在前维卓CTO 张烜看来,ChatGPT 背后的时代变化,是从信息时代 AI 向用户快速提供丰富的信息,到AI直接提供完整的知识体系。ChatGPT 的贡献是提供了一个便捷易用的交互界面,让普通人都能用得起来,功不可没,GPT-4 是在此基础上的再一次飞跃。
他认为,除了模型变得更大、更强以外,AI 技术本身的变化可能不显著,但从应用的角度看,新的时代已经到来。这个新时代便是知识体系和自动化的时代,AI 优化的目标是自动化地输出最终结果和完整的知识体系。
能够适应这种新形势的是以 RPA(Robotic process automation)为代表的自动流程化分发,但是目前的 RPA 起始于20年前,不适用于现在的媒体方式和交互内容,需要在文字、图像和视频化处理上加以改进,才能和 GPT 完美匹配。张烜对 AI科技评论透露,这是 GPT 影响产业的一个重要方式,也将是他接下来的创业方向。
目前,有一部分企业已经提前用上了 GPT-4,其中就包括了 Stripe、摩根士丹利和 Duolingo 等。
Stripe 团队列出了50个潜在应用程序来测试 GPT-4,经过审查和测试,当中有15个原型被认为是集成到平台中的有力候选者,包括支持定制、回答有关支持的问题和欺诈检测。
摩根士丹利人员日常工作需要面对一个巨大的内容库,涵盖投资策略、市场研究和评论以及分析师见解等知识内容达到数十万页,并且这些信息大多以 PDF 格式分布在内部网站上,需要顾问浏览大量信息才能找到特定问题的答案,搜索费时费力。
为此,从去年开始,摩根士丹利就引入了 GPT-3,利用 GPT 的嵌入和检索功能,释放内部人员在财富管理累积知识上的工作量,GPT-4 发布后,将为面向摩根士丹利内部的聊天机器人提供支持,该计划由摩根士丹利财富管理部门首席分析和数据官 Jeff McMillan 所在团队领导进行,团队项目负责人指出,GPT-4 将能够把所有洞察力解析为一种更有用、可操作的格式。
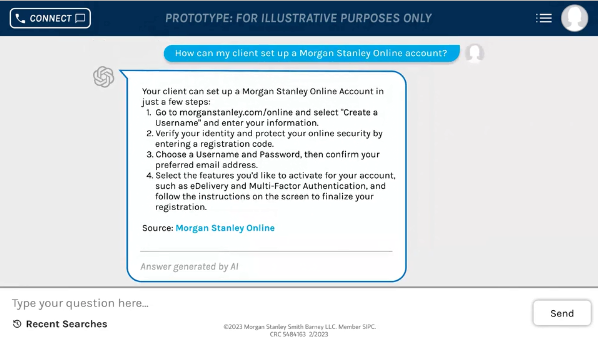
据 McMillan 介绍,摩根士丹利财富管理在 GPT-4 引入后将分为三个部分进行,第一部分的落脚点在 GPT-4 的“几乎瞬间访问、处理和合成内容的非凡能力”上,即基于互联网大量文本进行训练,并在单词、句子、概念和想法之间建立关系。
第二个落脚点在摩根士丹利的智力资本,摩根士丹利创立有一个独特的内部内容存储库,后续将通过 GPT-4 进行处理和解析,并受公司内部控制的约束。
最后一部分在公司的人员上,摩根士丹利就 GPT-4 进行了培训,每天有200多名员工查询相关系统并提供反馈,尽可能实现由内部聊天机器人完成全面搜索财富管理内容。McMillan 表示,这项工作还将进一步丰富摩根士丹利顾问与其客户之间的关系,使他们能够更快地帮助更多人。
Duolingo 也推出了一种由 GPT-4 提供支持的学习体验 Duolingo Max,新增“Explain My Answer(解释我的答案)”和“Roleplay(角色扮演)”两大功能。
角色扮演
在 Explain My Answer 中,学习者通过在某些练习类型之后点击一个按钮,可以进入与 Duo 的聊天获得答案解释,并要求举例或进一步说明;Roleplay 功能允许学习者与应用程序中的角色进行对话,角色覆盖多个真实场景,包括在巴黎的咖啡馆点咖啡、邀请朋友一起旅行、未来的假期计划等。
参考链接:

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}