 图源:Pixabay
图源:Pixabay
撰文 | 张天蓉
● ● ●
最近,人们对AI谈得最多的是deepseek(简称DS)。这匹来自中国本土的黑马,闯入全球视野,一度扰乱美国股市,在 AI 领域掀起了一场轩然大波。
不过,正如DS创始人梁文锋所言,DS的成功是因为站在了巨人的肩上,这个巨人,可以有不同的理解,最靠近的当然是Meta的开源代码(例如PyTorch和LLaMA)。说远一些,这个巨人是多年来科学家们推动发展的各种AI技术。然而最准确的说法,应该是两年之前OpenAI发布的聊天机器人ChatGPT,它是DS框架的技术基础。
ChatGPT的名字中,Chat的意思就是对话,这个词在AI中涉及的领域是NLP(自然语言处理);后面三个字母的意思:G生成型(generative)、P预训练(pre-training)、T变形金刚(Transformer)。其中最重要的是“变形金刚”,而变形金刚的关键是“注意力机制”(Attention)。下面简单介绍一下几个名词。
01
变形金刚
英语单词Transformer,可以指变压器或变换器。另外也可以翻译成变形金刚,那是一种孩子们喜欢的玩具,可以变换成各种角色,包括人类和机械。而这儿的transformer是谷歌大脑2017年推出的语言模型。如今,无论是自然语言的理解,还是视觉处理,都用变形金刚统一起来,用到哪儿都灵光,名副其实的变形金刚!所以,我们就用这个名字。
变形金刚最早是为了NLP[1]的机器翻译而开发的,NLP一般有两种目的:生成某种语言(比如按题作文),或者语言间的转换(比如翻译)。这两种情况,输入输出都是一串序列,此种神经网络模型称为“序列建模”。变形金刚的目的就是序列建模,它的结构可以分为“编码器”和“解码器”两大部分(图1)。序列建模是AI研究中的一项关键技术,它能够对序列数据中的每个元素进行建模和预测,在NLP中发挥着重要作用。
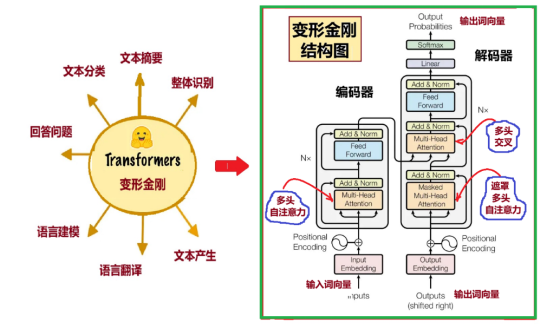
图1:Transformer模型及其中的注意力机制
图1右图显示了“编码器”和“解码器”的内部结构框图。它们都包含了多头注意力层(Multi-Head Attention)、前向传播层(Feed Foward)和残差归一化层(Add&Norm)。
神经网络模型的发展,从1958 年早期感知机的“机器”模型,到后来的算法模型,经历了漫长的过程。变形金刚的序列建模能力,超越了之前的循坏神经网络RNN,和卷积神经网络CNN,近几年,成为了新的序列建模大杀器,广泛应用于机器翻译、阅读理解和实体识别等任务中。
与变形金刚(Transformer)相关的论文,是Google机器翻译团队,在行业顶级会议NIPS上发表的。论文的题目是《Attention is all you need(你所需要的,就是注意力)》[2],一语道明了变形金刚的重点是“注意力”。图1右的Transformer模型中,红色曲线指出的,是3个主要的注意力机制框图。
因此,ChatGPT大获成功,凭借的是强调“注意力机制”的变形金刚;介绍注意力机制之前,首先简要介绍NLP的几个基本概念。例如,什么是“词向量”,什么是词崁入?有那些语言模型?
02
自然语言处理
实现人工智能有两个主要的方面,一是图像识别,二是理解人类的语言和文字,后者被称为自然语言处理,缩写成NLP(Natural Language Processing)。
2.1
什么是NLP?
自然语言处理,就是利用计算机为工具对人类自然语言的信息进行各种类型处理和加工的技术。NLP以文字为处理对象。
最早的计算机被发明出来,是作为理科生进行复杂计算的工具。而语言和文字是文科生玩的东西,如何将这两者联系起来呢?为了要让机器处理语言,首先需要建立语言的数学模型。称之为语言模型。ChatGPT就是一个语言模型。
语言模型最直接的任务就是处理一段输入的文字,不同的目的应该有不同的模型,才能得到不同的输出。例如,假设输入一段中文:“彼得想了解机器学习”,模型可能有不同的输出:
1,如果是中文到英文的机器翻译模型,输出可能是:“Peter wants to learn about machine learning”;
2,如果是聊天机器人,输出可能是:“他需要帮助吗?“;
3,如果是书店的推荐模型,输出可能是一系列书名:“《机器学习简介》、《机器学习入门》“;
4,如果是情感分析,输出可能是:“好“……
语言模型都有两大部分:编码器和解码器,分别处理输入和输出。
此外,对语言模型比较重要的一点是:它的输出不见得是固定的、一一对应的,这从我们平时人类的语言习惯很容易理解。对同样的输入,不同的人有不同的回答,在不同环境下的同一个人,也会有不同的回答。也就是说,语言模型是一个概率模型。
2001年,本吉奥等人将概率统计方法引入神经网络,并使用前馈神经网络进行语言建模,提出了第一个神经网络的语言概率模型,可以预测下一个单词可能的概率分布,为神经网络在NLP领域的应用奠定了基础。
2.2
词向量(Word Vectors)
语言模型中的编码器,首先就需要给语言中的单词编码。世界上的语言各种各样,它们也有其共性,都是由一个一个小部分(基本单元)组成的,有的基本单元是“词“,有的是”字“,有的可能是词的一部分,例如词根。我们给基本单元取个名字,叫”token“。例如,以后在解释语言处理过程时,我们就将中文中的“字”作为一个”token“,而将英文中的一个“word”,算一个”token“。
计算机只认数字,不识”token“。所以首先得将”token“用某种数学对象表示,学者们选中了“矢量”
最早期对词向量的设想,自然地联想到了“字典”。所以,最早给词汇编码采用的方法叫做One hot encoding(独热编码),若有个字典或字库里有N个单字,则每个单字可以被一个N维的独热向量代表。下面用具体例子说明这种方法。
例如,假设常用的英文单词大约1000个(实际上,英语有约1300万个单词),按照首个字母顺序排列起来,词典成为一个1000个词的长串序列。每个常用词在这个序列中都有一个位置。例如,假设“Apple”是第1个,“are” 是第2个,“bear” 是第3个,“cat” 第4个,“delicious” 第5个……等等。那么,这5个words,就分别可以被编码成5个1000维的独热矢量,每一个独热矢量对应于1000维空间的1个点:
“apple“: (1 0 0 0 0…………………..0)
“are” : (0 1 0 0 0…………………..0)
“bear” : (0 0 1 0 0 0…………..…..0)
“cat” : (0 0 0 1 0 0 0……………..0)
“delicious” : (0 0 0 0 1 0 0 0…………..0)
独热编码概念简单,不过,你很快就能发现这不是一个好的编码方法。它至少有如下几个缺点。
一是每个词向量都是独立的,互相无关,词和词之间没有关联,没有相似度。实际上,词和词之间关联程度不一样。既然我们将单词表示成矢量,而空间中的矢量互相是有关联的。有的靠的近,有的离得远。这种“远近”距离也许可以用来描述它们之间的相似度。比如说,bear和cat都是动物,相互比较靠近,而apple是植物,离他们更远一点。
二是这种编码法中,每个词向量只有一个分量是1,其它全是0,这种表示方法太不经济,浪费很多空间。在1000维空间中,非常稀疏地散发着1000个点。这也使得空间维度太大,不利计算。
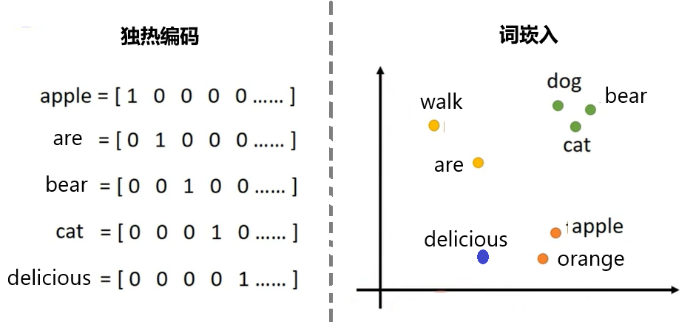
图2:词向量
目前NLP中使用比较多的是约书亚·本吉奥等人2000年在一系列论文中提出的技术,后来经过多次改进,如今被统称为“词嵌入”(Word embedding)。它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。例如,图2左图中的1000维词向量,被嵌入到一个2维空间(图2右图)中之后,将同类的词汇分类放到靠近的2维点,例如右上方靠近的3个点分别代表3个哺乳动物。
词嵌入中这个“维数低得多的向量空间”,到底是多少维呢?应该是取决于应用。直观来说,每一个维度可以编码一些意思,例如语义空间可以编码时态、单复数和性别等等。那么,我们利用“词嵌入”的目的是:希望找到一个N维的空间,足够而有效地编码我们所有的单词。
当然,词嵌入的具体实现方法很复杂,维数可以比1000小,但比2大多了,在此不表。
2.3
NLP和神经网络
在变形金刚之前的NLP,是用循环神经网络RNN、递归神经网络、双向和深度RNN、或基于RNN改进的LSTM等实现的。可以使用上述的同一种网络结构,复制并连接的链式结构来进行自然语言处理,每一个网络结构将自身提取的信息传递给下一个继承者。见图3。
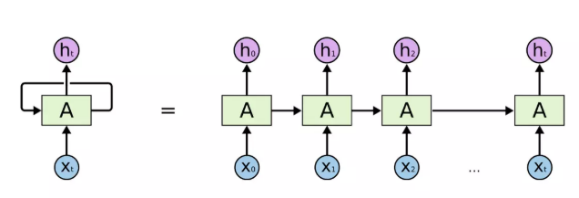
图3:RNN链接受上下文单词,预测目标单词
语言模型的目的就是通过句子中每个单词的概率,给这个句子一个概率值P。即通过计算机系统对人输入问题的理解,利用自动推理等手段,自动求解答案并做出相应的回答。
循环神经网络RNN是在时间维度展开,处理序列结构信息。递归神经网络在空间维度展开,处理树结构、图结构等复杂结构信息。
LSTM等模型和transformer的最大区别是:LSTM等的训练是迭代的,是一个一个字的来,当前这个字过完LSTM单元,才可以进行下一个字的输入。但transformer使用了注意力机制,可以并行计算,所有字同时训练,大大提高了效率。并行计算中,使用了位置嵌入(positional encoding)来标识这些字的先后顺序。那么,什么是“注意力机制”?
03
“注意力机制”
3.1
什么是注意力机制?
神经网络的思想最早是来源于生物学的神经网络,但是,现代的深度学习却早已脱离了对大脑的模仿。不过,人们在AI研究中碰到困难时,总免不了要去对比一下生物大脑的运行机制。这也是“注意力机制”这个概念的来源。
注意力机制是人类大脑的一种天生的能力。我们⼈类在处理信息时,显然会过滤掉不太关注的信息,着重于感兴趣的信息,于是,认知专家们将这种处理信息的机制称为注意⼒机制。
例如,我们在看亲友的照片时,先是快速扫过,然后通常更注意去识别其中的人脸,将更多的注意力放在照片呈现的人物、时间、和地点上。当我们阅读一篇新的文章时,注意力首先放在标题上,然后是开头的一段话,还有小标题等等。
人类的大脑经过长期的进化,类似于机器学习中应用了最优化的学习方法,形成了效率颇高的结构。试想,如果人脑对每个局部信息都不放过,那么必然耗费很多精力,把人累死。同样地,在人工智能的深度学习网络中,引进注意⼒机制,才能简化网络模型,以使用最少的计算量,有效地达到目的。大脑回路的结构方式,肯定影响着大脑的计算能力。但是,到目前为止,除了在一些非常简单的生物体中,我们仍然没有看到任何大脑的具体结构。不过,研究AI的专家们,有自己的办法来实现他们的目标,例如循环神经网络,长短期记忆,都解决了部分问题。
当科学家们利用循环神经网络,处理NLP 任务时,长距离“记忆”能力一直是个瓶颈,而现在引入的“注意力机制”,有效地缓解了这一难题。此外,从节约算力的角度考虑,也有必要用“注意力机制”,从大量信息中,筛选出少量重要信息,并聚焦到这些重要信息上,忽略大多不重要的信息。
3.2
注意力机制的种类
注意力机制可以按照不同的需要来分类,这儿我们只解释与Transformer相关的几种结构。
1,硬注意力机制:选择输入序列某一个位置上的信息,直接舍弃掉不相关项。换言之,决定哪些区域被关注,哪些区域不被关注,是一个“是”或“不是”的问题,某信息或“删”,或“留”,取其一。例如,将图像裁剪,文章一段全部删去,属于此类。
2,软注意力机制,即通常所说的“注意力机制”:选择输入序列中的所有信息,但用0到1之间的概率值,来表示关注程度的高低。也就是说,不丢弃任何信息,只是给他们赋予不同的权重,表达不同的影响力。
3,“软”vs“硬”:硬注意力机制,只考虑是和不是,就像2进制的离散变量;优势在于会节省一定的时间和计算成本,但是有可能会丢失重要信息。离散变量不可微分,很难通过反向传播的方法参与训练。而软注意力机制,因为对每部分信息都考虑,所以计算量比较大。但概率是连续变量,因此软注意力是一个可微过程,可以通过前向和后向反馈学习的训练过程得到。变形金刚中使用的是“软注意力机制”,见图4a。图中输入是Q、K、V,分别代表Query(查询)、Key(关键)、Value(数值)。
4,自注意力机制:如果图4a中的Q、K、V都从一个输入X产生出来,便是“自注意力机制” (图4b)。它的意思是:对每个输入赋予的权重取决于输入数据之间的关系,即通过输入项内部之间的相互博弈决定每个输入项的权重。因为考虑的是输入数据中每个输入项互相之间的关联,因此,对输入数据而言,即考虑“自己”与“自己”的关联,故称“自”注意力机制。自注意力机制在计算时,具有并行计算的优势。使输入序列中的每个元素能够关注并加权整个序列中的其他元素,生成新的输出表示,不依赖外部信息或历史状态。自注意力通过计算每个元素对其他所有元素的注意力权值,然后应用这些权值于对应元素本身,得到一个加权平均的输出表示。
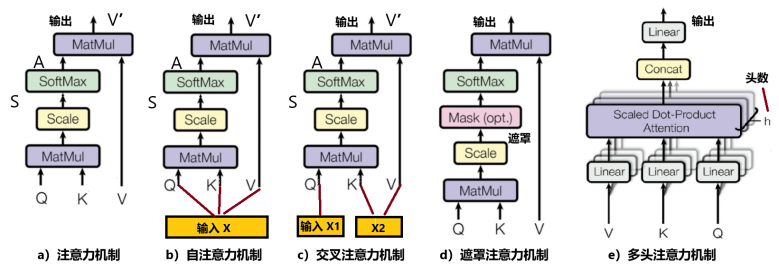
图4:各种注意力机制
5,注意力机制与自注意力机制的区别:注意力机制的权重参数是一个全局可学习参数,对于模型来说是固定的;而自注意力机制的权重参数是由输入决定的,即使是同一个模型,对于不同的输入也会有不同的权重参数。注意力机制的输出与输入的序列长度可以不同;而自注意力机制的的输出输入序列长度是相同的。注意力机制在一个模型中通常只使用一次,作为编码器和解码器之间的连接部分;而自注意力机制在同一个模型中可以使用很多次,作为网络结构的一部分。注意力机制将一个序列映射为另一个序列;而自注意力机制捕捉单个序列内部的关系。
6,交叉注意力机制:考虑两个输入序列(X1、X2)内部变量之间的关联,见图4c。
7,遮罩(Masked)注意力机制:在计算通道中,加入一个遮罩,遮挡住当前元素看不见(关联不到)的部分,见图4d。
8,多头自注意力机制:由多个平行的自注意力机制层组成。每个“头”都独立地学习不同的注意力权重,最后综合合并这些“头”的输出结果,产生最终的输出表示。多头机制能够同时捕捉输入序列在不同子空间中的信息,从而增强模型的表达能力,见图4e。
3.3
注意力机制如何工作?
最基本的注意力机制如图5a所示,它的输入是Q、K、V,分别代表Query(查询)、Key(关键)、Value(数值)。具体而言,Q、K、V都可以用矩阵表示。计算的步骤如下:算出Q和K的点积,得到他们的相似度,经过softmax函数作用归一化之后,得到相互影响的概率A,然后,将A作用到V上,最后得到的V‘即为注意力。
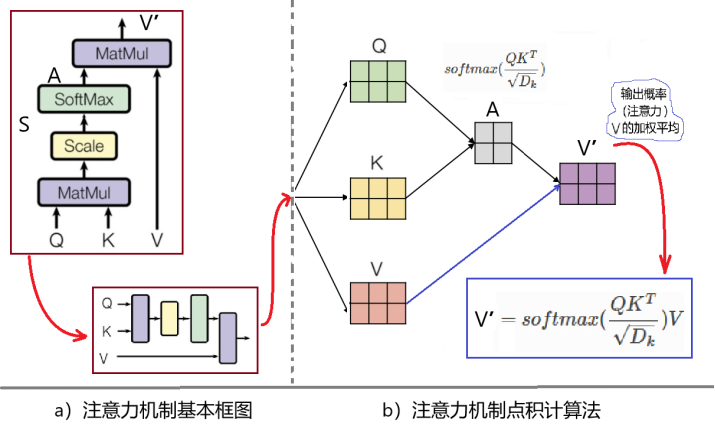
图5:注意力机制的计算
乍一看上面的叙述有点莫名其妙,这几个Q、K、V是何方神圣?从哪里钻出来的?
首先,我们举一个自注意力机制的例子,用一个通俗的比喻解释一下。自注意力机制中的Q、K、V,都是由输入的词向量产生出来的。比如,老师去图书馆想给班上学生找“猫、狗、兔子”等的书,老师可能会与管理员交谈,说:“请帮忙找关于养猫狗兔的书”。那么,老师的查询之一可能是,Query:养猫书、管理员给老师几个书名Key:《猫》、《如何养猫》……,还从图书馆的计算机资料库中得到相关信息Value:这几本书的作者、出版社、分类编号等等。
上面例子中,输入的序列词向量是老师说的那句话的编码矩阵,即图4b中的输入X。然后,从如下计算得到矩阵Q、K、V:
Q = X Wq,
K = X Wk,
V = X Wv。
这儿的Wq 、Wk 、Wv 是将在训练中确定的网络参数。
图5是注意力机制计算过程的示意图。右下角的方框里,是注意力机制的计算公式。公式中有一个乘积项:QKT,意思是Q和K的内积。两个向量的内积,等于它们的模相乘,再乘以它们之间夹角的cosine函数,因此可以描述两个向量接近的程度。内积越大,表示越接近。计算公式括号内的分母:Dk开方,代表注意力机制框图中的“Scale” (进行缩放)部分。这儿Dk是KT的维数,除上维数开方的目的是稳定学习过程,防止维度太大时“梯度消失”的问题。然后,点积加缩放后的结果,经softmax归一化后得到相互影响概率A。最后,再将结果A乘以V,得到输出V',这个输出矢量描述了输入矢量X中各个token之间的自注意力。
综上所述,从自注意力机制,可以得到输入词序列中词与词之间的关联概率。比如说,假设输入的文字是:“他是学校足球队的主力所以没有去上英语课”,训练后可以得到每个字之间相关情况的一种概率分布。但是,字之间的相关情况是很复杂的,有可能这次训练得到一种概率分布(“他”和“球”有最大概率),下次得到另外一种完全不同的概率分布(“他”和“课”有最大概率)。为了解决这种问题,就采取多算几次的办法,被称为“多头注意力机制”。就是将输入矢量分成了几个子空间的矢量,一个子空间叫一个“头”。
也可以使用上面所举老师去图书馆找书的例子,除了“猫“和”书“关联之外,狗、兔子……等都可能和”书“关联起来,也可以使用“多头注意力机制”来探索。
参考资料略

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}