撰文 | 邸利会(《知识分子》主笔)
责编 | 陈晓雪
Rolf Pfeifer稳稳地站在台上,做着演讲。他一边用遥控器控制着PPT翻页,一边踱步,从一头走到另一头,照顾处在不同位置的观众。当他走动时,眼中看到的听众图像是稳定的,不会起伏和晃动。当然,Rolf Pfeifer不是机器人,他做到这一切易如反掌。

这是在今年CCF-GAIR全球人工智能与机器人峰会上。作为机器人专家,苏黎世大学信息学系计算机科学教授以及人工智能实验室的主任,Pfeifer的心情显得有点复杂,一方面行业的火热吸引了大量资金,自然是好事;可另一方面,催生出的机器人产品却大同小异,在外形上像小孩的玩具,而功能上——不过相当于一只iPhone。
“本质上,这些机器人就是桶子里的iPhone,轮子上的iPhone。” 在谈到充斥市面上的社交机器人时,他不无感叹地说。

这多少反应了有点尴尬的现实:我们可以建造复杂的机器人,在工厂里精准地装配汽车,飞到火星上探测新世界,却无法造一个普通人一样的机器人,完成一些基本的简单任务:比如像Rolf Pfeifer这样,稳稳地站在台上,从容地边走边翻PPT,而不用担心突然摔倒。
如今,一些机器人的比赛,比如亚马逊的机器人大赛,所完成的任务也不过是识别物体,抓取,从一头移动到另一头。看起来很小儿科,不过,对于机器人来说,“抓取” 的确是个难题,当然也与亚马逊的业务密切相关:或许有一天技术突破了,就可以部分代替仓库里的理货员了。
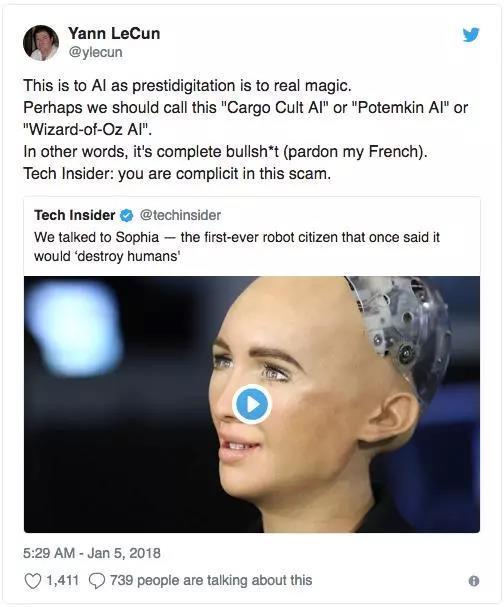
不过,至少现在还不用担心!这波AI热潮涌来后,我们受到的惊吓已经太多了。当AlphaGo战胜李世石的那一刻,几乎所有人都在惊呼,哎呀嘛,人类完了!简单回复一句,根本不是那么回事。还记得Sophia么,它似乎能与人交流,做出各种表情,表演的视频席卷网络,但已经被研究神经网络的专家Yann Lecun打了假,没错,他实在看不过去,脏话都差点骂出了口。
回到这次的大会,Rolf Pfeifer的担忧代表了业内很多专家的意见,这从他演讲的题目也可以看出来—— “我们如何应对机器人、AI技术过热的时代”。
在另一个与人工智能紧密相关的领域,计算机视觉,专家们也觉得有必要告诉大家,你们眼中的“重大突破”、“吓X了”的黑科技,还远没有到,诸如AI统治人类的“世界末日”的时候。
“你也可以说它很蠢”
在大会的计算机视觉专场,来自香港科技大学的权龙教授做了“计算机视觉,识别与三维重建” 的演讲。
“人工智能的目的是让计算机去看、去听和去读。图像、语音和文字的理解,这三部分基本构成了我们现在的人工智能。而在人工智能的这些领域中,视觉又是核心,视觉占人类所有感官输入的80%,也是最困难的一部分感知,如果说人工智能是一场革命,那么它将发轫于计算机视觉,而非别的领域。” 他说。
而当下的这场人工智能的热潮,也发轫于计算机视觉领域。如今,人工智能似乎要几乎等同于机器学习,等同于深度学习,等同于更专门一点的卷积神经网络(简称CNN)。与大众的普遍印象不同,在学者的眼中,引爆人工智能的不是AlphaGo,而是2012年的Alex Net,卷积神经网络卷土重来。Alex Net更早的版本要追溯到1998年由Yann LeCun建立的LeNet。卷积神经网络可以认为是改进了的神经网络,一种据说是受人脑神经元的连接启发而设计的计算模型。
不过,和今天的受追捧不可,之前的神经网络属于几乎无人问津的“冷门”。“那个时代,如果你在论文中提到CNN,估计会直接被拒;但今天你的论文如果不提CNN,就非常难入围(计算机视觉会议)。” 权龙说。
利用CNN,研究者不断改进模型设计,在一些识别任务,如图片识别上的错误率,在特定数据集上,已经超过了人类。这种成绩的取得,除了算法层面,权龙认为还要归功于算力的提升(如英伟达GPU的更新迭代)以及大量的标准数据(如李飞飞创建的Image Net)。“如果你能清晰地定义问题,做好数据标定,这个问题基本就解决了。”权龙说。
不过,他提醒说,这种东西还有很大局限,并不是真的聪明,只是记住了很多样本。“你也可以说它很蠢,因为它根本不知道自己在做什么。一切取决于你的标准,如果你把一个东西标注成猫,它就认为这是一只猫,明天你再把它标注成狗,它就认为这是一条狗。” 他说。
CNN的优势,在权龙看来,在于端到端,把数据丢给模型就可以了,而且无需像之前需要人工定义,就能学到维数动辄上百万的有结构的视觉特征。他认为,下一步计算机视觉要在识别的基础上,走向三维重建。“我们是活在三维空间里,要做到交互和感知,就必须将世界恢复到三维。” 他说。
“人眼基本不会犯这样的低级错误”
确实,除了物体识别(recognition)外,计算机视觉研究还包括了三维重建(reconstruction),图像重组织(reorganization)。在这次大会上,同为计算机视觉专家、加州大学伯克利分校的马毅则对深度学习进行了更深刻的反思。
“视觉并不仅仅是找任意一个算法或系统,能对一个数据库中对图像分类、恢复三维几何,或者分割就可以了。而这样的算法和系统的重要性能必须要有保障。首先是对噪声不敏感(insensitive),数字图片识别对小的噪声和扰动稳定(stable);此外要保证对干扰要稳健或鲁棒(robust),例如戴眼镜,化浓妆也能人脸识别;还有对姿态不变性(invariant),物体姿态变化、图片变形也不会影响结果。” 他说。
如果从这三个要求衡量,他说,现在的物体(人脸)检测以及识别技术并不能在这几方面提供严格的保障,经验验证尚且不充分,更谈不上理论上的严格保障。他在现场展示了最近的两项研究,给听众留下了深刻印象。
其中一项研究[1]涉及人脸的检测,在图片上加了一个很小的噪声后,用当前最好的卷积神经网络看,就已经检测不出是人脸了,更不用说识别出是谁。

另外的一项研究[2]则表明,对图片中物体的姿态(位置、大小,方向)做很小的改动,现代的深度卷积神经网络的识别就变的很差,可人眼却基本不会犯这样的低级错误。
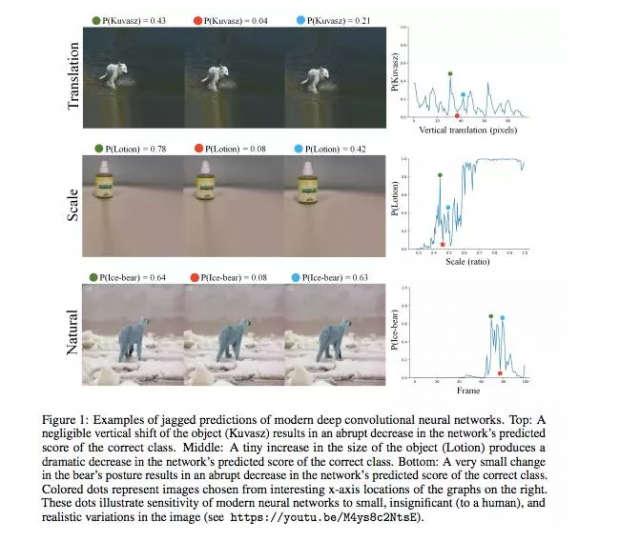
他提到,神经网络在数学本质上是在学习高维数据中稀疏的低维结构,“从有限的观测样本中稳健地学习到一个低维的模型” 是机器学习一个普遍性的问题,是无论如何绕不开的核心挑战。
他还认为,利用反传算法(back propagation)加上足够的计算力、数据等资源,深度模型可以拟合或过度拟合任意有限的样本,所以在有限样本能够覆盖所有感兴趣或重要的例子的应用场景是有很用的。但(机器或者人的)学习最终目的终究是从有限的样本发现最简单的通用的数据生成的机理模型,以对付无限可能的变化情况。从有限到无限,这是学习以及科学研究的根本目的。另外,从工程实现来讲,没有这样一个参考模型和标准,学习算法系统的稳定性,稳健性和不变性,是无从谈起的。
“我们解决了计算机视觉的三个核心问题了么?严格来讲还没有。我们在物体识别、几何重建、图像分割这些问题上,都还没有找到能够严格保证稳定,稳健和不变性的算法和系统。计算机视觉,以及人工智能还有很长的路要走。” 马毅总结说。
担心AI的过热问题
由深度学习所带动的这波人工智能的热潮,究竟会持续多久,目前还不好确定。但从这次大会上传递出的信息看,专家们已经在担心AI的过热问题,这包括媒体的炒作、民众的过高期待,投资界的胡乱撒钱,而这些并不会立竿见影的带来技术的突破。
在去年的大概这个时候,当我去北京西南部的亦庄参加一个机器人展览时,我其实就只有一个简单目的:找一个可以自主充电、帮我吸尘的机器,我并不敢奢望找一个叠衣服,洗碗做饭的机器人。记得当时,我问过很多展台的接待人员同一个问题,有什么事是你的机器人能做,而iPhone或者智能音响不能做的?没有一个回答能让我感到满意。
直到今天,我略有惊讶地看到,作为专家,Rolf Pfeifer也有和我这样的普通用户一样的感受,很多的机器人不管外形多么美,多么酷,多么可爱,都不过是装了轮子的iPhone——它们既不会主动的感知,也不会与真实的物理世界发生交互。它们连刚出生几个月大的婴儿都比不过。唯一的区别是,iPhone可以装在口袋里,这些却带不走,也许只会在一阵喧嚣和热闹的Show过后,被人遗忘在某个蒙满灰尘的角落。
参考文献:
1. Adversarial Attacks on Face Detectors using Neural Net based Constrained Optimization, Avishek Bose and Parham Aarabi, arXiv:1805.12302v1, May 31, 2018
2. Why do deep convolutional networks generalize so poorly to small image transformations? Aharon Azulay and Yair Weiss, arXiv:1805.12177v1, May 30, 2018


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}