
少数派中的少数派
撰文丨程曼祺
当大部分人都相信一件事或趋势时,不同意的人可以选择沉默,也可以大声说出来。前者是少数派中的多数派,后者少数派中的少数派。
马毅就是一个少数派中的少数派。
自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算机系主任和数据科学研究院院长。
他最早将 “压缩感知” 技术应用于计算机视觉领域,在人脸识别、物体分类等任务上产生了巨大影响。
知名 AI 学者李飞飞是马毅在 UIUC 时参与招聘的第一个华人助理教授,ResNet 一作何恺明是马毅在微软亚研院负责视觉组时招的第一个新员工。
马毅公开表达时直言不讳。AI 业界惊叹于 GPT 等大模型的威力,担心 AI 可能毁灭人类,如图灵奖得主杰弗里·辛顿(Geoffrey Hinton) 和 OpenAI 发起者之一伊隆·马斯克(Elon Musk)就多次将 AI 类比为原子弹,呼吁监管。
“说现在的 AI 危险的人,要么是无知,要么是别有目的。” 马毅在 twitter 上回应 AI 威胁论。
强烈的观点来自他对当前 AI 系统的理解。不少人相信用更多数据、更大算力做更大参数的模型,就可以实现 AGI(通用人工智能),这就是大模型的 Scaling Laws(规模定律),它被一些人视为 “信仰”。
马毅则不相信这条路。他认为现在的深度学习网络本质上都在做压缩(compression):就是从图像、声音和语言等高维信号里,找到能表示数据间相关性和规律的低维结构。
2023 年底发表白盒大模型框架 CRATE 时,马毅在社交媒体上称压缩不会通向通用智能或意识。
“GPT 有很多知识,但知识不等于智能。”GPT 表现出来的数学推理等能力在马毅看来本质还是依靠记忆、统计,就像一个接受填鸭式教育的高分低能的学生,它并不能学到因果推理、逻辑等能力。
马毅理解的智能,是能自己纠正现存知识的不足并发现新知识的系统。
为解释深度学习网络到底在做什么,马毅团队最近几年的重点工作是白盒大模型,用数学来解释深度学习网络的压缩过程,以找到更高效的压缩方式。
他希望让更多人了解白盒,以对抗黑盒带来的误解,因为 “历史上,任何有用的黑盒都可能变成迷信和巫术”。他担心对 AI 的恐惧可能带来过度监管,遏制创新。
相比 Scaling Laws 追随者的人多势众和 AI 威胁论的直指人心,马毅等少数派影响力小得多。
今年 5 月与马毅在香港见面前,我们问身边的 AI 从业者:怎么看马毅团队的研究?
“不太关心”、“不看他的论文了”,大部分从业者更关注如何在现有路线下提高训练和推理效率。
就在前几天,马毅的多篇论文合作者,图灵奖得主杨立昆(Yann LeCun)公开抨击马斯克说 AI 可能毁灭人类是阴谋论。马斯克问杨立昆:“过去 5 年,你做了哪些 ‘科学’?”“你应该更努力一点。”
马毅团队的白盒大模型 CRATE 去年发布时,在同等参数下的指标不如已有的模型 ViT。一些从业者称这是 “负优化”,“魔改 Transformer,但效果还不如”。
秘塔科技创始人、马毅的学生闵可锐说:现在 AI 界的评价标准越来越偏向一个研究是否 work,而不是智识上的增长。
“你不在 1000 亿参数的模型上验证,大家就不太相信。” 他称学界与工业界的算力差距也拉大了不同模型的效果差距。
去年马毅创立了忆生科技:“如果产业界能接受这些东西,功成不必在我。但我们想加速这个过程,证明白盒路线可行。” 马毅说。
写完第三本书后发誓不再写书的马毅现在又开始写一本新书,针对高年级本科生。他将面向香港大学所有专业的学生设计 AI 通识课程,讲历史和计算思想,希望年轻一代有正确理解 AI 的基础。
忆生天使轮投资人,真格基金合伙人刘元认为,在主流方向上做到最好,或敢做、能做不一样方向的人,都是他们寻找的创始人:“马毅是我们见过的、少有的能做开创性工作的学者,我们很钦佩。”
真理不一定掌握在少数人手中,但少数派和观点竞争的存在增加了发现真知的概率。
“如果你相信只靠 Scaling Laws 就能实现 AGI,
我觉得你该改行了”
《晚点》:一些大模型从业者告诉我,他们现在已经不看您的论文了,因为可解释的白盒大模型对实践没什么指导,他们更关心如何找到更高效的训练和推理框架。
马毅:很正常,当你要做不太一样或比较基础理论的东西,大家不一定很容易接受。
但只有用理论框架解释已有的工作,把现在这些通过经验的神经网络搞明白了,你才知道它的局限在哪里。
《晚点》:你觉得主流方法的局限是什么呢?很多人相信用更多的数据、更大的算力搞更大参数的模型可以达到 AGI。
马毅:任何事情,用越大规模的资源就会得出越好的结果。但现在通过 Scaling Laws 看到的现象是不是智能本身?这是个 big question。
《晚点》:你认为现在大模型涌现的智能实际是什么?
马毅:大模型现在只实现了局部的记忆功能。
早期我们做分类和识别,让机器能认出什么是猫,是在模拟从物理视觉信号到我们大脑中的抽象概念的过程。生成则是一个反向过程,是从语义信号再生成物理信号。
这两个加起来才是完整的记忆系统,现在的模型,识别和生成是分开的,所以只是对这个完整系统的局部的模拟。记忆本身从生物智能的角度也只是一种低层次智能,不是逻辑、因果推理等人类的高级智能。
正因为它是局部的,它的实现也比较粗暴,对数据、模型和算力的要求都非常大。提升它的性能也很昂贵,现在要做 Backward Propagation(反向传播)——各种深度模型,不管多少层,都是几十亿、几百亿、几千亿的参数同时优化,这样算力要求就很大。
而且它是一个开环系统(即无反馈控制系统,指系统的输入量不受输出量影响的系统),没法知道自己学的东西是对还是错。所以现在训练大模型,第一步就要清洗好数据,如果你给它错的数据,它也会记下来。
《晚点》:即使有缺陷,但为什么现在追逐 Scaling Laws 是很多聪明人的共同选择?全世界在这个方向上的直接和间接投入达到了万亿美元量级。
马毅:因为它正反馈强。而且一个东西一旦变成主流,大家就会相互确认、强化认同。
一个领域里,大家都去认可一件事,往往会忽略掉其他可能更重要或至少跟现的想法互补的东西,这在历史上重复发生。
《晚点》:有什么例子吗?
马毅:深度网络本身就是例子。60、70 年代冷了以后,之后三四十年里只有寥寥无几的人在坚持。
现在有点矫枉过正,原来神经网络是一无是处,现在变成能解决所有问题。只要稍微有点常识是不是都会觉得这里边有问题?
《晚点》:矫枉过正会带来什么?
马毅:从众,什么东西热大家就做什么。这样同一个指标只会培养出同质化的人,能力、方向、研究水平都一样,没有独创性。
其实过去十年,国内对 AI 的投入绝对不比国外少,但整个人才培养和科研导向变得同质化,这会造成落后。
《晚点》:全球范围里指出现有方法局限的主要是杨立昆(Yann LeCun)、李飞飞和您这种学者。年轻的从业者是不是还是有更快拿出成果的压力?
马毅:作为年轻人,如果你的信仰就是 Scaling Laws,觉得把现在的系统做大就能实现 AGI ,我觉得你该改行了。因为你已经不可能有作为了,你就只能做一个螺丝钉。
去年多模态模型出来后,上上下下都说好,我跟杨立昆、谢赛宁,还有我们的学生就想:好吧,我们验证一下,如果确实如此,我们真可以改行了,就让 OpenAI 完成这个使命就好了,因为已经实现 AGI 了。
结果我们只做了尝试性的测试,就发现绝大部分多模态模型在很简单的任务上也会犯一些常识性错误。主流多模态大模型里,只有 Gemini 和 GPT-4V 高于随机猜测的水平。
但大家不愿意去谈这种事。现在社会各界为了推动 AI 只讲积极面,不去看局限。

马毅提及的研究见论文 Eyes wide shut? exploring the visual shortcomings of multimodal llms。该论文展示的一些多模态模型对图片的错误理解例子。
《晚点》:即使不能当最领先者,去优化现有方法是不是也有价值?
马毅:我是说不适合再做研究了。研究要有创新,不应该从众,要去找现有方法里不足的地方,改进现有知识,发现新知识。如果你找不到现有方法的不足,肯定得改行。
“任何有用的黑盒
都可能变成迷信和巫术”
《晚点》:你们团队这几年花了很大功夫研究白盒大模型,用白盒打开黑盒与更安全、可控的 AI 有关吗?一般人们会把可解释性和可控联系起来。
马毅:黑盒的最大问题还不是你怎么去控制它,而是历史上,只要什么东西是黑盒,而且比较有用,就会产生迷信和巫术。
现在很多人想当巫师、国师,制造恐惧、利用恐惧,想垄断这个技术。
《晚点》:你是指马斯克吗?
马毅:还有几位,都是一帮掌握这个技术的百万富翁,说大模型是原子弹,可能把人类毁灭了。
我们就觉得很可笑。我很清楚你在干什么,你在做数据压缩,做一个简单的、局部的记忆功能,自主学习的能力都没有,这有什么可怕的?
如果这个东西真危险,为什么说它危险的高科技公司的 CTO、CEO 自己也在做,Hinton(图灵奖得主 Geoffrey Hinton) 自己都在创业。你做的就不危险,别人的就危险?
去年我在 twitter 上发过一个很得罪的人话:现在说 AI 危险的人,要么是无知,要么是别有目的。
《晚点》:就算现在的大模型还不是高级智能,但是不是需要提前防范它的潜在危害?
马毅:任何技术都可能是双刃剑。照这个逻辑,互联网太危险了,可以传递各种错误信息,炼钢也危险,可以做刀、做炮。
科研领域应该是开放的。如果政府去监管一个技术,应该规范它的用途和最终产品,不能连芯片、软件,甚至算法开源都要规范。最后只能是既得利益者的垄断。
《晚点》:所以白盒的一个意义是给大模型祛魅?
马毅:我们想让大家明白大模型本质上在做什么。
它现在做的是非常简单,甚至机械的事。有些结果看起来蛮神奇,但这些网络的框架和对数据的处理都可以 100% 用数学解释清楚。
这也是为什么我们花了大量工夫去做实验,其实作为研究完全不必要。你看最近那篇文章,有 6、7 个学校的团队一起。我们谁都没那么多资源,就得团结起来,把不同应用场景都做出可信赖的成果。
(注:马毅提到的研究见 White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is?)
“白盒是对数据压缩过程的数学解释,
当知道了数学原理,就可以省去很多试错成本”
《晚点》:实际上你们现在研究的白盒大模型,具体是在做什么呢?
马毅:现有的深度学习模型,例如 Transformer(主流大语言模型架构)、Denoising Diffusion (去噪扩散模型,主流文生图模型)本质都在做一样的事:压缩数据——就是从高维的图像、声音、语言等信号里,找到可以表示数据间相关性的低维结构,这些低维结构就可以帮助预测高维信号——只是压缩的算子和优化策略不太一样。
过去大家是通过经验和尝试,不断找到更简约、更精准的近似压缩方式,但很多人不一定意识到了自己在做这件事。
白盒就是对这个压缩过程的数学解释,搞清它每一层要实现什么统计或几何功能。
一旦清楚意识到了优化的本质,你就能把这件事做得很高效,而且会发现历史上有比现在基于经验试出来的更高效的方法。
《晚点》:追求对数据压缩过程的数学解释,除了学术意义,有什么应用价值吗?
马毅:现在大家买那么多芯片,大部分都是在试错。可能一个模型只需要一千张卡,实际却用了一万张,因为靠经验设计的网络可能有 10 个版本,要一个个去试哪一个更好。
依靠经验的黑盒模型虽然有效,但不清楚到底是哪些部分有效,经常是 “三分之一的人在干,三分之一的人看,还有三分之一的人在捣乱”。这就增加了很多试错成本,也会带来训练中的不稳定性。
而如果知道了数学原理,就相当于把搭建筑的砖头搞明白了,以后就可以换更便宜、更好的材料,重新设计它。
《晚点》:听起来就是从业者在追求的东西。但他们好像又不是很关注白盒的进展?
马毅:2021 年的 ReduNet 是一个白盒神经网络的理论框架,但未必就找到了最佳的工程实践,当时学校也没太多算力,我们只能在小规模的数据上做实验,效果没那么直观。
过去一年我们突破很快,真的发现在这个框架下可以设计出能被解释的网络,网络性能也接近甚至超过了现在一些基于经验的网络,而且我们的模型更简洁、更可解释。
其实白盒大模型在工业界的关注度也蛮高的。去年底发的 CRATE,可能论文引用次数少一些,但它在 Github 上已经有上千颗星了。这对于一篇理论性的文章来说还是非常罕见的。
(注:ReduNet 是马毅团队 2022 年发布的白盒大模型理论框架,CRATE 是马毅团队 2023 年提出的更新的白盒大模型。)
《晚点》:不过在相似参数下,CRATE 在一些任务上的指标仍低于现有模型如 ViT。有人说白盒大模型反而是对现有系统的 “负优化”,你怎么看?
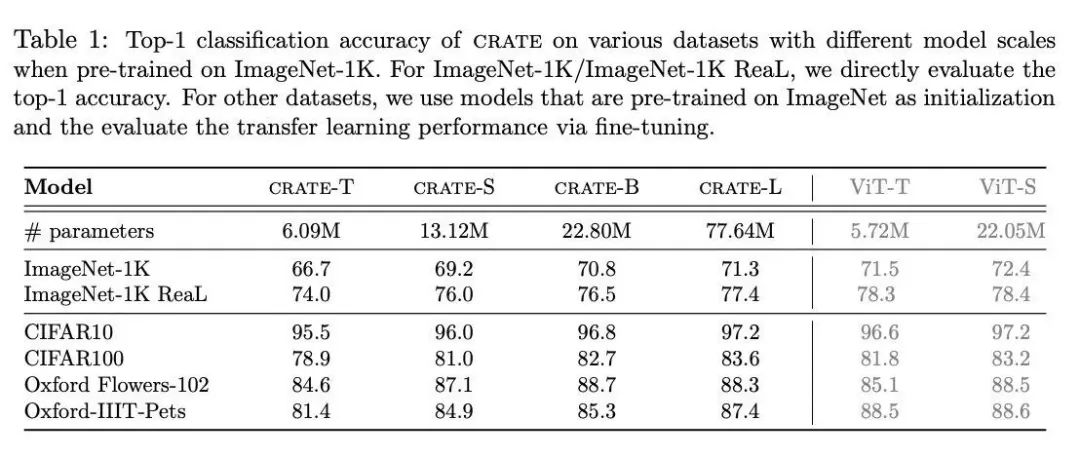
2023 年底发表的论文 White-Box Transformers via Sparse Rate Reduction 中,不同版本的 CRATE 和 ViT 在 ImageNet-1K 数据集上的图像分类任务准确率比较。
马毅:这个工作的目的是验证依据原理设计的、可解释的架构是有效的。但工程带来的额外提升是后续的事。
比如我们最近就有新成果,前几天刚发布了 CRATE-α。简单调整一些编码方式后,CRATE-α 的性能已经可以与 ViT 媲美。
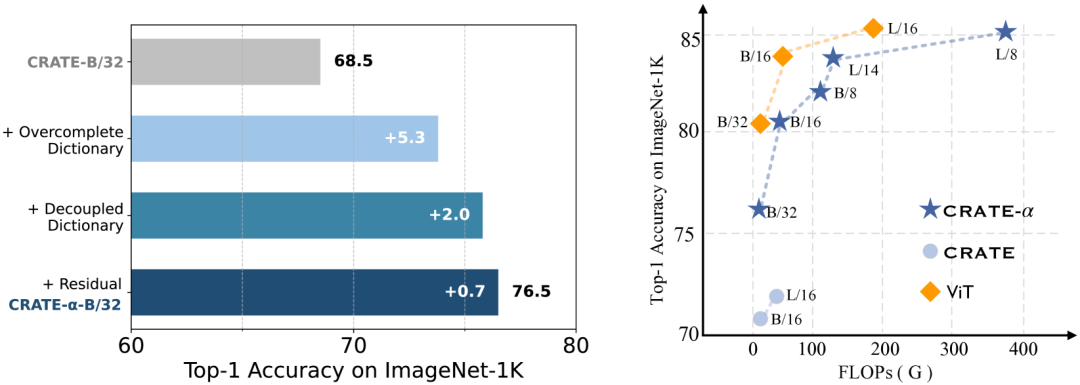
CRATE-α、CRATE 和 ViT 在 ImageNet-1K 数据集上的图像分类指标比较。见论文 Scaling White-Box Transformers for Vision。
《晚点》:介绍 CRATE 的论文称它是 “白盒 Transformer”。白盒模型和 Transformer 是什么关系呢?它仍是一种 Transformer 架构的模型吗?
马毅:准确来说,白盒是一种架构实现方式,它也可以不是 Transformer。只是 Transformer 先发现了现有方法,在最初那篇论文里,我们是从原理上去解释 Transformer 里经验发现的东西到底在干什么,哪部分有用,为什么有用。所以我们完全可以不相似,因为压缩过程也可以被推导出来,可以被简化。
接下来我们一定要超越现有的网络,我们正在做。CRATE 还可以更简洁和高效。
《晚点》:怎样算超越?比如你们的新模型和 GPT-4 比如何,和 GPT-4o 比呢?
马毅:同样性能下,计算效率高十倍、百倍;同样算力规模做训练,模型性能更高。而且我的算子、系统更稳定。
《晚点》:实际上白盒模型现在能提升多少训练效率?
马毅:目前所用的资源只有经验做法的的三分之一或四分之一。
实际上可能省得更多,因为我们人很少。原来 ReduNet 是光有理论和概念,还不知道实现路径。去年年中,我们开始看到白盒框架可以做出不输经验方法的模型,就更有信心了,我们的学生也更兴奋了。这之后光靠我们一个团队,网络版本已经迭代了好几次,因为我们不是瞎猜,不需要试 10 个、100 个。
“Everything should be made as simple as possible, but not simpler”
《晚点》:你认为现在的大模型只是对记忆功能的局部的模拟,那么真正的智能是什么?
马毅:现在的一个混淆是把知识当成智能。它们相关,但不同。知识是存量,智能是增量。
GPT-4 和一个初生的婴儿,哪个更有知识?GPT-4。哪一个更智能?婴儿。婴儿可以自学,他可能变成下一个爱因斯坦。
知识很多时,看起来好像有智能。GPT 看似能解决一些数学推理,但它本质还是在靠记忆和统计,类似生物的 “反射”,它并没有学到因果、逻辑,就像一个刷题考试的高分低能的学生。能使用知识都不是智能最本质的特征。智能最本质的特征是能纠正自己现存知识的不足,能增加新的知识。
《晚点》:你两年前和计算机科学家沈向洋、神经科学家曹颖提出了智能的两个原则是简约和自洽,这怎么理解?
马毅:疫情期间我开始思考,为什么会有智能?我们——我指生物——为什么要学?要学什么?
当你开始思考这个问题,问题本身就会给你想法:
这个世界上肯定是有值得学的东西,有一定的规律,可以帮你预测将来会发生什么,这样学习才有用,才能帮你生存。
而且这些规律一定会以最简约的方式被表达出来,因为生物不可能消耗大量能量记录每个 case。
(注:相关论文为 《关于形成智能的简约和自洽原则》On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence。)
《晚点》:这就是简约的意思?
马毅:就像爱因斯坦讲的:Everything should be made as simple as possible, but not simpler.(凡事力求简洁,但不能过于简化)。简约和自洽就是从这句话来的。
简约有两个意思:学到的规律要被简约地表达,学到规律的方法也要是最省力和简洁的。
但为什么又要 “but not simpler?” 因为如果只是简约,没法预测也不行。所以它不能太简化,而应简化到你刚刚好能做对预测。当预测和外部世界是一致的,这就是自洽。
人的自洽过程有两个特点,一是它是有损的但能保持一致性。比如我告诉你桌上有两个苹果,让你画出来,你可能画得细节不一样,但你不可能画出 3 个苹果。
人的预测的一致性很好,每个人都是牛顿,我一松手(马毅拿起一只笔),你马上知道会发生什么,比博士生按方程写的还准,我们大脑里早就对引力建模了。
二是人的自洽过程全部是在大脑内部完成的,当你做了一个预测后,你不需要到物理世界去测量真实的长宽高,你就是通过不断预测下一秒会发生什么,在生活中不断改进,不断对外部世界的形状、大小、距离、速度和加速度建模。
《晚点》:这好像有悖于直觉。难道我们不是在和物理世界的真实互动中学习的吗?
马毅:实际上大脑是通过对比内部信号学习的,模型就在大脑里,大脑不断比较内部生成的预测信号和世界是否一致,不断预测、不断纠正,而不需要去外部世界对比物理信号。
更准确说,是生物没有这个选项。老虎朝你跑过来,你说别别别,我测一下速度和距离。这就是自主地达成了自洽,它要通过能自己纠错的闭环系统来实现。
现在大模型也可以自洽,但需要人去帮它对齐输入和输出,既给图像,又给对应的文本标签,因为大模型自己无法知道学的东西是对是错。
《晚点》:简约和自洽是两个智能的原则或特征,怎么达到这种智能呢?
马毅:第一是理解整个压缩过程,从外部世界的高维物理数据里高效地找出能表达规律的低维数据。从黑盒到白盒就是在做这件事。
第二是通过双向 mapping(映射) 保证模型学到的内在结构能很好地预测外界,保持一致性。
三是通过闭环系统来保证这个学习过程是自主的。
我们认为至少这三件事是必要的。学习的本质就是:这个世界是可测的,是有规律能学到的,而且不需要花太大代价。
《晚点》:在实现后两件事上,现在你们有什么进展吗?
马毅:前两年,我们在闭环系统和自主上有一些预测性的结构,比如增量学习(incremental learning)和持续学习(continuous learning),有完整的科学性验证,不过还没找到像自然界这么高效的优化方式。
不过即使仍然使用现在的全局优化方式,也可以看到闭环网络的优势,它可以自主学到数据里的结构。
(注:相关研究见 Unsupervised Learning of Structured Representations via Closed-Loop Transcription。)
《晚点》:闭环系统在实际应用中的好处是什么?
马毅:大家都知道开环网络重新训练的话会 “灾难性遗忘”,稍微一调,原来的东西就被洗掉了。
闭环系统不会忘,而且学得越久记忆越强。自然界的记忆都是闭环的,它有天然的稳定性。
《晚点》:以上推演都基于机器智能和动物智能有相似的结构,这一定成立吗?其实机器已经可以做到很多人做不到的事。
马毅:现在我们追求类似生物的智能,一个很重要的原因是,基于自然进化出的智能机制对能源的利用效率是其他机制没法比的。现在生物智能的能效比就是最优的,高等如人类,低等如蚂蚁都是这样的。人的大脑才二十瓦,比现在机器的能耗效率高 7、8 个数量级。
“你新想到的东西,往往历史上早有了,甚至更好、更完整”
《晚点》:你是怎么形成关于智能的这些想法的?
马毅:我们几年前开始梳理人工智能的历史,发现很多重复的思想,同一个东西取不同的名字,很多变形。我们想尽量看清哪些是必要的、哪些是相似的、哪些是独特的。
简约和自洽就是对林林总总各种变形的一个统一、简洁的解释。
《晚点》:同一个理论有很多变形,有什么例子吗?
马毅:比如做文生图的 denoising diffusion(去噪扩散模型),看起来很厉害。其实数学家 250 多年前就知道了,叫拉普拉斯方法,物理学家 100 多年前又重新发明了一遍,就是朗格文动力学。只是现在通过计算机把它大规模、高效地实现了。
科学史的规律是,好的想法总会被翻新,这也有价值。但只要梳理一下历史就会发现,现在你想到的东西往往早就有了,甚至历史上还有更好、更完整的理论,而现在通过经验试出来的东西很多还不到位。
《晚点》:你们还从其它科学里获得了哪些启发?
马毅:主要是神经科学。我们为什么跟 Doris(曹颖,神经科学家)合作?因为他们发现猴子对某些物体的编码跟我们发现的一些压缩数据的数学结构很相似。猴子大脑里也有子空间机制,它会用非常低维的子空间来表达脸或一类物体,每个神经元代表一个坐标,编码得简洁、紧凑。
我们的白盒当时也是想把低维子空间当作基本元素,去近似高维数据的结构。
我们提出的闭环、反馈、纠错,他们也在猴子大脑里看到了。比如猴子眼睛看到一个东西时,大脑就开始预测它下一步会到哪里,如果判断错了,它就会紧张,会开始纠错和重新判断。
我们想对深度神经网络的理论做统一、简约解释的想法也和他们不约而同。科学家本来就追求简约性,面对任何事情,他们都要判断什么必要、什么不必要,找到那些最基本的机制。
《晚点》:你称他们为科学家,那 AI 研究者是什么?
马毅:AI 现在大部分是在做工程。工程师的思维是,这件事能做出来就行,有冗余也无所谓,比如这个事可能用 10 块钱就能完成,但没关系,我先找一个 1 万块的方案,只要充分就够了。
科学家不一样,他们问得最多的是这个事有没有必要,是不是一定非此不可,他们更追求必要性。
《晚点》:缺乏科学解释的工程奇观能持续吗?你之前总结过,历史上神经网络的两次危机都是因为缺少数学解释,这会再次发生吗?
马毅:人类历史本来就是归纳法和演绎法两条腿走路。
当实验条件很充分时,大家会做更多尝试,比如当年用对撞机撞出一个粒子就能得诺贝尔奖,后来有了标准模型以后就不发奖了。大模型也一样,当搞清楚背后的机制,会发现单个模型、论文都是同一现象的特例。
冬天会不会再来?未必。过去有危机,是因为那时基于经验归纳的东西也不够有用。现在通过这几年这么多资源、全世界几千个团队试错,找到了还挺有用的方案,它可能不会再冷下去。
但它是不是最高效的?到底还能做多少事?这是需要搞清楚的。
《晚点》:你还从历史里看到了什么有意思的事?
马毅:大家想过没有,为什么 50 年代达特茅斯那帮人(指在 1956 年的达特茅斯会议上提出人工智能概念的明斯基等人)要在 intelligence 前面加上 artificial。直接讲智能不就完了吗?为什么要加这个形容词?
《晚点》:Artificial 不是指人工的,而是指人类的?
马毅:对了。它就是为了把人和动物的智能分开。
人工智能的发展是好几条线交织在一起的。最早大家对神经网络的灵感来自心理学和神经科学,看大脑神经元在做什么;也有一批做计算的人,如图灵,思考智能在做什么,如何通过机器模拟人的能力。
1956 年的达特茅斯会议更加侧重人的高级智能,比如因果推理、符号运算和逻辑推理,而不是对图像或声音信号的提取、记录和生成。谁在研究这些问题?是更早时 40 年代的信息论、博弈论和控制论,它们研究信息的编码、解码,反馈和纠错机制,这都是底层智能,是动物也有的特点。
你看维纳的《控制论》的副标题(“或关于在动物和机器中控制和通信的科学”),他没有把机器和动物分开。香农(信息论的提出者)和他老婆最喜欢玩的游戏就是给你上半句、预测下半句,这就是 GPT。
所以 50 年代的那批年轻人也是想和前面的人不一样。我们过去十年用了他们提的 artificial intelligence,但实际在做另一层的事。那时大家关心智能的机制,到后面就忘掉了。现在很奇怪,很多年轻人从来不想这些问题了。
《晚点》:你觉得为什么年轻人不喜欢看历史了?
马毅:氛围变了,文化变了。过去十多年,每年那么多论文,大家就看看今年、去年开源了什么东西,拿来用一用、拼一拼、改一改。他不再去看以前的原理了,因为有些理论可能还没有被新的论文实现。
拿来主义对品味,对文化都有很大影响。
《晚点》:计算机学科的本科或研究生教育不教这些吗?
马毅:我觉得现在更多是讲单一的算法和工具,没有一个完整系统。所以我们希望本科教育要重新更完整地介绍这些东西。
我之前写完第三本书发誓再也不写书了,写书很痛苦,但后来觉得还是要写,我正在写的书就是针对高年级本科生的。
大家对 AI 都很热衷,但对很多概念和历史都有误解,再加上企业和媒体炒作,很多说法不完整,甚至不客观。
我们现在从研究生教育到本科教育,到在港大成立新的计算和数据科学学院(School of Computing and Data Science),就是要推动更正确的 AI 认知。我们也会承接港大的 AI 通识教育。
《晚点》:那港大的文科、社科学生也要学 AI 课?
马毅:对,所有专业都要上两门 AI 或计算思想的课程。我们把它的重要性等同于中文和英文。因为以后世界上肯定会有 AI 系统,你得学会正确理解机器,跟它交流,机器会是人类社会的一个新群体。
学校做验证,公司做放大
《晚点》:去年你创立了忆生科技,为什么也加入了创业大潮?
马毅:以前做研究,把自己搞懂就完了,但去年很多人开始说 AI 很危险,所以这已经不是我们的科研兴趣问题了,不是我们等 3、5 年让别人搞明白,这变成责任了,必须把原理打开。
去年之前,我们对白盒框架也没那么自信,因为之前验证得不够。但后来我们发现白盒模型实际上可以规模化,性能能上去。
第二也是发现现有神经网络只实现了记忆的一部分,也希望能把记忆实现得更完整、更自主。所以公司叫忆生,就是能获得记忆,又能再生成记忆,达到自己纠错、自己学习的闭环系统。
总结来讲,我们公司想打造下一代智能系统,它基于白盒框架,具有完整的记忆,也就是世界模型结构,能实现自主学习、自我纠错的机制。
《晚点》:在学校做这件事和创立一个公司来做这件事的区别是什么?
马毅:学校该做两件事。一是搞清楚已有的知识,做传承。我们做白盒就是在研究深度神经网络到底在干什么,为了教书也要搞清楚。
第二,研究性的大学还要发现现有知识的不足,改进知识,做 idea 的验证。去年我们的验证已经非常充分了,在学校做的事已经做到了。而且学校资源有限,不光是算力,还有时间。
公司要做的是放大。如果产业界能接受这些东西,功成不必在我,我费这个劲干什么?但现在很多人在推动一些我们认为不太正确的方法,仍是那些基于经验的东西。
《晚点》:和别的 AI 公司合作不能有效推进你的想法吗?
马毅:我们也在合作。但让大家认识还需要过程,做公司的目的也是加速这个过程,把现有的深度学习机制做得更正确,做规模化;把我们的框架、算法、算子工具化,让更多人用起来,看到这个路线是可行的。
《晚点》:你觉得做到什么才能向更多人证明这个路线可行?GPT 路线是在 ChatGPT 爆火后才成为共识的。
马毅:要么是量,要么是质。如果我们的方法能让大家看到可以十倍、百倍地提高现有计算的效率,降低开发成本,这肯定会引起关注。
第二是,你真的能做到自主学习,本质上改变现有的系统,带来完全不同的能力。
《晚点》:你怎么看一些其它的主流路线之外的探索,比如杨立昆提出了世界模型和 JEPA 框架;李飞飞,当年你在 UIUC 招的第一个老师,她最近也创业了,要探索空间智能。
马毅:飞飞是关注具身智能和三维重建这些东西的应用。LeCun 的 JEPA 跟我们想法很一致,现在大家不都说 AI 2.0 吗?我们不认同。2.0 一定要有本质的不一样,我们认为 2.0 应该有自主学习能力。
现在还有一些公司也在探索一些新构架。是不是有道理?我并不能评论,但至少在寻找更与众不同的东西,我觉得这要鼓励。
《晚点》:十几年前你关于 “压缩感知” 的研究在视觉领域影响力很大,那时你就追求数学可解释性,和现在思路一致。你怎么看你们的新成果被接受的速度变慢了?
马毅:那时大家还比较希望把机制搞明白,最近十几年,经验确实变得越来越重要了。算力和数据的发展也促进了通过归纳法去提升表现的这条路。
但现在大家慢慢有些违背传统的科学方法了,过分强调通过资源或经验试错就能解决所有问题,甚至认为理解不重要。
《晚点》:你会怎么描述自己的角色?你是大模型路线的反对者吗?
马毅:我是希望正本清源。但我们做的事和大模型完全不矛盾。我们第一步是解释现有的东西,这样才知道至少下面一两步要如何完善、提高。
《晚点》:你觉得要让 AI 研究环境变得更好,最关键的是什么?
马毅:科学研究说白了就一条,人。投钱、买机器都是小钱。有图灵这样的人,没东西他也给造出来。
关键是,正确的人能不能获得资源?去年 ChatGPT 出来后,很多人讨论为什么我们没有 OpenAI?我说请问大家,OpenAI 做出 GPT 的团队,平均年龄不到 30 岁,我们有没有机制能把数十亿美元对接到一群没有资历的年轻人?
当然,这是一个非常大的系统。我能做的是尽量影响自己周围的小系统,把资源分配到有创造力的年轻人身上。
《晚点》:研究和创业上你都选了更少人走的路,你担心走错路和失败吗?
马毅:不会,首先我比较认可这个东西对产业的价值,白盒至少可以提高现有方法的效率。
这件事也不可能等,不能老是去做重复性的跟踪和小改进。中国这么大,大家不要都去做同质化的东西,应该有一些人和公司做比较使命驱动的事。
做小改进去挣点钱,不是我们的技术优势所在,也不是团队或我个人的诉求。
题图来源:马毅
文中提到的论文的汇总
Scaling White-Box Transformers for Vision, 2024/5
Eyes wide shut? exploring the visual shortcomings of multimodal llms, 2024/4
White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is? 2023/11
Unsupervised Learning of Structured Representations via Closed-Loop Transcription, 2022/10

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}