阅读:0
听报道
编者按:
当下人工智能应用于新药筛选进行得如火如荼。以至于很多制药领域的公司认为人工智能无所不能,但其中的虚虚实实,并非每个人都能真正看懂。前两周《知识分子》刊登了李伟和黄牛博士两篇文章,介绍了人工智能应用于新药研发领域的概况,同时指出人工智能用于新药研发的不足,如有效靶点太少,大数据训练出来的人工智能并不够“智能”。他们希望行业能将人工智能这把“好刀”用好,充分发挥它的优势,扬弃它的不足。近日,同济大学生物信息学教授刘琦对此提出自己的看法。他认为,人工智能用于新药研发的范式发生了转变:从以靶点为核心到综合表型的筛选,从大规模大样本训练到小样本的学习。人工智能这把“好刀”,其实非常锋利,但回归到从药物发现到疾病治疗,仍旧是漫长的路程,道路曲折,前途光明。
撰文 | 刘 琦(同济大学教授)
责编 | 叶水送
近日,笔者阅读了黄牛老师等人于《知识分子》公众号发表的两篇关于人工智能+新药研发的讨论,受益良多。黄牛老师是物理学背景,从“第一性原理”的角度,高屋建瓴地为我们展现了新药研发波澜壮阔的图景,以及应用人工智能可能存在的若干利与弊。笔者是计算机+生物信息学交叉背景,在这里也想从我的专业角度来谈谈对于人工智能+药物研发的粗浅认识,不求甚解,但求抛砖引玉。
药物研发的转变:从以靶点为核心到综合表型筛选
首先,正如黄牛老师所说,新药研发是一个系统工程,从靶点的发现、验证,到先导化合物的发现与优化,再到候选化合物的挑选及开发,最后进入到临床研究,可谓九死一生。传统药物研发的起点,在于发现疾病相关的有效靶点,靶点已知,后续的药物研发路径相对明确,可借助于各种计算机辅助虚拟筛选技术、高通量组学技术,综合计算化学、物理学以及结构生物学的相关知识,进行有效的小分子(或者大分子)的筛选与设计。
但药物靶点的发现,其本质上是由分子生物学和系统生物学学科驱动的。疾病的靶点、突变基因以及功能蛋白的鉴定是一个系统工程,在笔者的知识体系中,是和药物研发同等复杂的过程。换句话说,药物靶点的确实是联系分子生物学以及药物研发的一个桥梁,但其本身归属于分子生物学范畴。
从这个角度上说,我们谈人工智能是否可用于新靶点的发现,其实是一个伪命题。我们既可以说人工智能够应用于新靶点的发现:因为人工智能的相关技术已大量应用于疾病的靶点预测、高通量数据的分析以及系统生物学的建模过程中。同样,我们也可以说人工智能并不是新靶点发现的核心手段,因为靶点发现本身属于分子生物学的研究范畴,但我们并不能否认人工智能在靶点发现上,已产生以及将要产生的重要作用。
最近,Cell及其子刊同期发表的近20篇针对TCGA的Pan-cancer分析的系列论文,就是一个典型的案例,这些论文大量使用了高通量组学数据的分析技术以及人工智能的相关建模方法,来挖掘和分析肿瘤相关的突变位点,可以看到,人工智能技术已融合到复杂疾病靶标分析的方方面面。
其次,黄牛老师提到了利用人工智能技术进行海量文献挖掘来发现新靶点(如Benevolent AI公司的工作等)。正如黄牛老师所说:(1)自然语言处理技术(NLP)是人工智能技术的一个分支,人工智能技术在靶点挖掘领域的应用还有其他若干方向。面向海量文本的挖掘是人工智能比较容易落地的一个应用场景。但是如前所述,靶点发现其本身应该归属于分子生物学的研究范畴,所以仅仅分析文献数据,并不一定能够发现可靠的靶点;(2)我个人建议将靶点发现和后续的药物设计分开来讨论,相对于靶点发现,人工智能目前确实在药物设计层面有更好的应用和落地。
最后,当前药物研发的范式正在从单一的以靶点为核心(Target-centric)的模式向整合表型筛选(phenotypic-screening)的模式进行转换。传统的药物研发以靶点为核心,但是我们越来越认识到,复杂疾病是一个综合系统,单一或者若干个靶点的突变,可能并非是这个疾病发生发展的根本原因,癌症的靶向药会产生抗性,因为肿瘤系统不断地进化并且具有高度的异质性;老年痴呆症(AD)至今为止也没有发现较为明确的靶点。大多数复杂疾病的发病机制并不清晰,靶点也不明确。
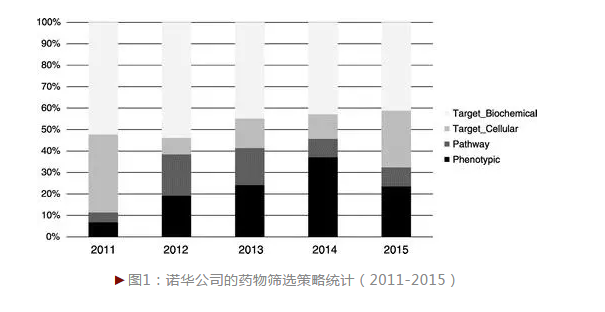
这种情况下,整合表型筛选进行药物研发越来越受到学术界和工业界的关注[1]。表型筛选系指在不明确疾病靶点以及相关的Mechanism of Action(MoA)的情况下,基于疾病的表型数据(Phenotype Data)进行药物的筛选和设计。直观的理解是,我们如果发现某种小分子可逆转疾病的表型,那么这个小分子针对于这个疾病即具有潜在成药性,可进行后续的进一步验证。同时,小分子的确定反过来也可以帮助疾病靶点的筛选。例如,我们可以通过反向对接技术(Inver-dock)以及网络药理学的方法(Network Pharmacology)来预测小分子的结合靶点。2011年至2015年,诺华公司的新药研发统计数据表明,其公司采用表型筛选策略进行药物筛选的增长率要远高于以靶点为核心的筛选模式(图1)。
在黄牛老师文中所提到的杨森公司等利用化合物的细胞图像数据,进行药物筛选的Imagenome概念,其本质即是表型筛选的一种体现,这里的表型即为图像。在新药研发领域,我们已经可以基于细胞系的转录组表型进行药物重定位(Drug Repositioning),其典型代表即为面向Broad Institute开发的Connective Map数据库的挖掘和应用[2]。2011年,美国《科学•转化医学》杂志发表了美国加州大学旧金山分校计算健康信息学研究所所长Atul Butte的工作, 成功地应用了表型筛选的方法,筛选出一种抗消化性溃疡药甲氰咪胍(Cimetidine),用于治疗非小细胞肺癌 [3],并进行了in-vitro和in-vivo的验证。综上所述,疾病的靶点发现,目前看并非是药物研发的唯一起点。
北京大学来鲁华教授等也在JACS撰文指出,药物研发的发展趋势之一是在传统基于结构的药物设计的基础上,走系统生物学的研发模式[4]。正如黄牛老师所说,未来的药物研发是一个综合多学科多手段的系统工程,“没有理由人工智能应该取代物理,也没有理由物理应该排斥人工智能”,我们需要整合大量的高通量组学数据,网络药理学数据乃至图像等高维表型数据,面对这些数据,人工智能技术可以大有作为。
大规模标记样本:是AI的阿基琉斯之踵?
当前流行的人工智能模型,特别是深度学习模型(Deep Learning)往往需要大量的标记样本进行训练,所以对标记样本的需求很高。在生物医学以及药物研发的应用场景下,标记样本的获取依赖于领域专家知识和实验验证,故成本比较高。我们看到深度学习在生物医学领域最先落地的应用场景是病理切片的图像读取,相关的人工智能公司如雨后春笋,一片红海。究其原因,是因为深度学习这种layer-wise的学习模式,天然适合对图像这种low-level feature的样本进行表征学习(Representation Learning)。通过逐层的网络学习,深度学习可自动学习图像的High-level feature,一定程度上避免了人工进行特征工程(Feature Engineering)的繁琐过程。同时ImageNet等大规模标注的图像数据库也为深度学习模型的快速发展提供了可靠的训练数据来源。
深度学习模型可以很自然的应用于病理图像分析,门槛相对较低,但是正如黄牛老师所说,我们同样应该认识到目前病理图像的深度学习远未达到临床可以替代病理医生的水平,主要原因在于:(1)高质量可靠的病理图像标记样本仍然缺乏,模型的泛化能力差;(2)各个公司或者论文发表的预测结果,缺乏统一的独立测试数据集以及有效的评价标准进行评估;(3)在模型的方法学设计上,还需要更加深入的考虑病理图像的特点,并且引入先验的领域知识。

药物研发领域的标记样本问题同样存在,但是笔者认为和病理图像领域有很大差别:(1)如前所述,药物研发领域所积累的数据十分多样化,我们既有各种高通量的组学数据,同时又有各种表型数据(如Image)及文本数据,整合分析多源高维的异质数据,可以一定程度上弥补了我们在单一数据源小样本层面存在的问题;(2)人工智能的发展趋势,也正在从传统的大样本训练向小样本学习及反馈学习的模式转变。Yann LeCun形象地比喻利用非监督学习对大量的无标记样本进行分析是人工智能这块“蛋糕的主体”,而强化学习是“蛋糕中美味的樱桃”(图2)。
中国科学院上海生命科学研究院陈洛南教授等建立了一套完整有效的基于高维数据小样本(甚至是单样本)的疾病靶点标志物筛选的方法;而近年来发展的弱监督学习(如迁移学习,多任务学习,半监督学习等)、小样本学习(one/few-shot learning)乃至零样本学习(zero-shot learning)也逐渐在药物研发领域应用。笔者团队在基于迁移学习、多任务学习、半监督学习等小样本/弱监督学习方法学进行药物虚拟筛选及组合用药预测领域进行了一定的探索和尝试;斯坦福大学的Vijay Pande教授等近期也尝试用one-shot learning来进行low data drug discovery[5];而强化学习已被应用于小分子的生成设计[6];这些工作均是药物研发领域面向小样本进行的有益尝试。
人脑对于客观事物的理解,并不一定需要大量样本的训练,很多时候基于简单的类比既可以进行学习。DeepMind公司最近在Nature Neuroscience杂志发表论文探讨大脑如何在少量的经验下进行学习,即“元学习”(meta-learning)或“学习如何学习”(Learning to learn),而对于元学习模式的理解,是我们达到通用智能的重要途径之一[7]。3月底,Nature杂志发表了基于人工智能进行药物逆合成路线设计的工作,完全借鉴了AlphaGO的思想[化学界诞生了一个“AlphaGo”],而AlphaGO之后的AlphaGO Zero版本则实现了不需要依赖训练样本的对弈模式,药物研发领域这样的模式会不会出现?我们拭目以待。
总结来说,对于大规模标记样本的依赖,到底是不是药物研发中应用AI的阿喀琉斯之踵(The Achilles' heel of AI)?笔者个人认为不是。其原因如下:(1)药物研发是一个大量多源多层面数据共存的场景,多源数据的整合分析非常重要,同时也可以弥补单一样本源的小样本问题;(2)小样本学习的发展是人工智能发展的重要方向,我们期待也相信新的学习范式能够在药物研发领域落地。
药物研发+人工智能:从数据到治疗,还有多远?
正如黄牛老师所说,药物研发的每一个阶段都有多种可用的方法和技术,各自优缺并存,“择其善者而用之”。而人工智能技术,可应用于药物研发的各个层面(这里特指靶点筛选,小分子筛选、设计、合成,成药性评估等实验验证前阶段。大分子药物设计较为复杂,不在此次讨论范畴)。在这里,有必要说明一下笔者对于现代人工智能技术和传统计算机辅助药物设计(CADD)之间区别的理解。我所理解的传统CADD技术,更偏向于以靶点和结构信息为核心的计算机辅助设计,如传统的定量构效模型的构建(QSAR),基于结构的虚拟筛选(Virtual Screening)等,而现代的人工智能技术应用已逐渐跳出以靶点和为核心的传统研发模式,面对的是海量的、多源的、异质性的数据,可以说现代的人工智能技术在药物研发中的应用,是以数据为核心驱动的。黄牛老师在第二篇讨论中介绍了人工智能在药物研发中的若干应用,在这里,我进一步用图三进行一个小结。(见图3)
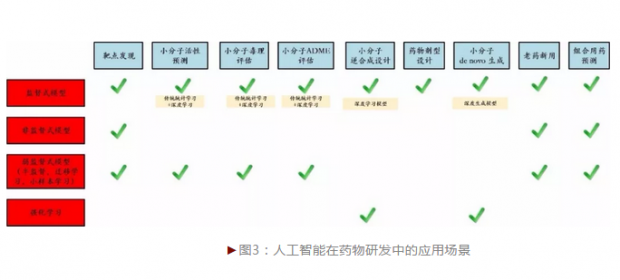
由上可见,人工智能技术几乎涵盖药物研发实验前所有的步骤。药明康德公司曾经提出药物研发的VIC模式,即“VC(风险投资)+IP(知识产权)+CRO(研发外包)”。在这里,笔者对于VIC提供另外一种解读,即“Virtual(虚拟)+IP(知识产权)+Capital(资本)”。我个人认为,未来的药物研发,可在资本的介入和知识产权的保护下,在实验验证前最大程度的虚拟化、人工智能化,由计算机来评估药物成药的各个指标,最大程度的降低失败率,通过选取最可能成药的小分子进入后续的实验和临床验证,来节省药物研发成本,缩短药物研发时间,而后续的实验和临床验证,又可外包至CRO公司批量化完成。
当然,这种想法只是笔者个人的理想,可能不甚成熟。对于人工智能在药物研发领域的应用,正如黄牛老师所说,我们既不能过度解读,也不能固步自封,道路是曲折的,前途是光明的:From data to therapy, a long but prospective way to go。
参考文献:
[1] Dorothea Haasen et al, How Phenotypic Screening Influenced Drug Discovery: Lessons from Five Years of Practice, ASSAY and Drug Development Technologies, 2017, DOI: 10.1089/adt.2017.796.
[2] Lamb J et al, The Connectivity Map: using gene-expression signatures to connect small molecules, genes, and disease, Science, 2006, Sep 29;313(5795):1929-35.
[3] Sirota M et al, Discovery and preclinical validation of drug indications using compendia of public gene expression data. Science Translational Medicine, 2011 Aug 17;3(96):96ra77.
[4] Jianfeng Pei et al, Systems Biology Brings New Dimensions for Structure-Based Drug Design, J. Am. Chem. Soc. , 2014, 136, 11556−11565.
[5] Han Altae-Tran et al, Low Data Drug Discovery with One-Shot Learning, ACS Cent. Sci. , 2017, DOI: 10.1021/acscentsci.6b00367
[6] Marcus Olivecrona et al, Molecular De Novo Design through Deep Reinforcement Learning. 2017, arXiv preprint arXiv:1704.07555.
[7] Jane X. Wang, et al, Prefrontal cortex as a meta-reinforcement learning system, Nature neuroscience,2018,doi:10.1038/s41593-018-0147-8.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}