撰文 | 崔原豪
责编 | 李珊珊
“我一生中从未见过,至少在我从事科技行业的30年中,美国西海岸的先进科技可以在几个月内以非常真实的方式出现在印度农村。我不认为在过往的工业革命中有过这种现象,对于知识型工作者来说,也许这一次完全等于工业革命。”
在瑞士达沃斯举行的世界经济论坛的一场对话中,现任微软公司CEO、董事长萨蒂亚·纳德拉曾这样表示。
让我们借用上帝的权柄来操纵时空,把一个生活在10世纪的罗马农民带到15世纪中国,虽然当地礼仪和语言有所不同,四周的农田和建筑仍能让他感到如归故土般熟悉。但如果把某位15世纪的哥伦布水手转移到21世纪的城市附近,他会发现自己完全无法理解周围几乎所有事物。因为在过去短短250年间,人类的科技和经济发生了三次爆炸性增长,几乎所有人(而不是一小撮精英人群)的物质生活都发生了翻天覆地的变化,我们把这种涉及几乎所有人的生产力变革称为“工业革命”。
ChatGPT出现的短短两个月内,我身边自然语言处理领域从业的朋友们就经历了两场深深的焦虑,一场是ChatGPT刚诞生时,对自己研究方向的反思,另一场则来自于现在的资本狂潮。固然,现在以ChatGPT为代表的AIGC(生成式人工智能)存在真实性、可控性、时效性和理解力问题(事实上微软新版Bing里已经解决了很多),但让人恐惧的是,这些问题仿佛并非无法可解,而是更让人心生害怕的是,未来近在眼前,如果不拥抱变化,也许便如那位来自15世纪的哥伦布水手,一夜之间,自己便几乎成为了变化本身。
我们不得不承认,正如纳德拉所言,一场新的、关于“智能”的工业革命的萌芽正破土而出。对比从前,ChatGPT的优势并非“把信息分发给每一个需要的人”,而是“预测性地表示*和调用信息”,也是因此,它不是传统互联网应用,比如搜索引擎、聊天工具或者新闻推荐的简单复刻。
如果把各类人工智能算法比作蒸汽时代的蒸汽机、电气时代的发电机、信息时代的计算机和互联网,作为人类历史上用户数最快过亿的消费级自然语言处理应用,ChatGPT就像初生的汽车、电话或者互联网网站,正以前所未有的速度让原本分散在各领域的自然语言处理算法“飞入寻常百姓家”,影响到几乎所有人的生活。
在最近这两个月里,随便一搜就可以看到,太多的科技领袖,从马斯克、纳德拉,到李开复、周鸿祎等,都在发声称ChatGPT即将改变世界;太多的互联网公司,比如谷歌,微软,阿里,百度正在抢占潮流;又有太多的学术机构、高校也开始讨论ChatGPT生成论文是否符合学术规范;而突然之间又有太多各行各业从业者燃起了被ChatGPT替代的担忧与焦虑……
很多人开始问,这种生成式人工智能会像远古人类一样产生智慧吗?在这场由机器思维开启的工业革命里,ChatGPT是怎么发展到现在的?它的局限是什么?它对我们每个人的命运意味着什么?在这篇文章里,我尝试对上述几个问题作出回答。
或许此后,每位读者都会对“怎样对待ChatGPT”这个问题有自己的想法。
ChatGPT更像人,它就一定更智能吗?
“思维”帮助人类统治地球至今。不论你喜不喜欢,它都正粗暴地推着每个人的后背进入下一个房间,虽然我们并不知道房间里是天使还是魔鬼。”回溯历史,自人类开始直立行走至今已有250万年光阴。在这漫长的进化过程中,我们的先祖使用火焰、工具和石头建造道路、城市和高塔,驾驭蒸汽、闪电和钢铁征服大地、海洋和天空。我们超越了儒勒·凡尔纳的想象,只需要48小时就能环游世界;我们完成了40亿年里地球生物从未完成的壮举,踏上了月球。越来越多的人类相信,思维是人和动物的本质区别,而7倍于同体重哺乳动物的大脑容量是人类先祖产生智力、开启长达7万年地球统治的关键。
人类一直在试图仿制自己,从神话到现实。

神话史上第一个“机器人造物”塔罗斯之死,现藏于意大利贾塔国家考古艺术馆
古希腊神话里,宙斯曾授命工匠之神赫菲斯托斯锻造一个力大无比、按照特定程式来运作的青铜巨人“塔罗斯”,用来保护克里特岛免受外来入侵。当时的塞浦路斯艺术家皮格马利翁精雕细琢后爱上了自己的雕像造物“伽拉忒亚”,幸运的是爱神最终成全了他们的爱情并使其成为活人。《列子·汤问》中也曾记载,匠人偃师用皮革、木头等材料制造了一个舞姿优雅、动作千变万化的艺人献给周穆王,周穆王信以为真,却因为吃醋差点杀了他。然而,在那时,这些想法只能停留在少数人的想象中。
这一切,直到两大信息巨头相遇。或许是冥冥之中的神灵指引,1942年末,阿兰·图灵被英国政府派遣到贝尔实验室参与安全通信研究,在这里,他遇到了正在数学组任职的克劳德·香农。当时,《论可计算数及其在判定性问题上的应用》已经发表,图灵也已经完成了“图灵机”这样的概念模型设计,试图以此模拟人类的计算能力。
在一次自助餐厅的相遇过程中,香农对这样的概念模型也表示了极大的兴趣,两人在不断讨论中认为,既然计算可以被机器模拟,那这样的概念模型是否能扩展到描述人类所有的“智能”行为?那么对人来说,什么是“智能”?
两位信息科学巨匠陷入了漫长的争论,直到图灵离开美国也没有得到确切结果,但正是这些富有价值的讨论,让人工智能这个概念开始生根发芽,从“神话”走向“科学”。在此后数年时间里,图灵开始逐渐意识到定义“智能”或许并非是合适的开端,因为这是个哲学问题,它并不能在现实中通过实验验证。那么,假如“智能机器”可以表现得和人类一样好,那么我们是不是也可以通过它的“模仿水平”判断“机器智能”程度?
答案是肯定的,这就是如今举世闻名的“图灵测试”。
所谓图灵测试,即:让计算机在不和人接触的情况下进行对话,如果人无法分辨对方是人还是机器,那即可认定机器存在智能。
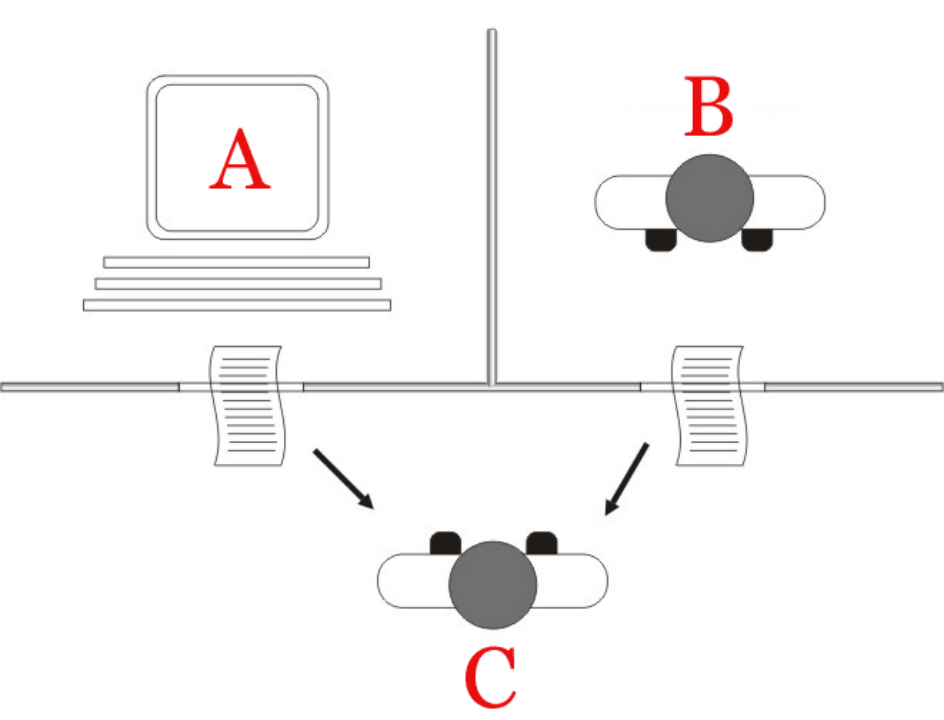
最简单的图灵测试内容
图灵在提出图灵测试时,不会意识到一个简单的思维实验会对后世产生如此重要的影响,以至于在此后几十年里,几乎每段时间都会有各种各样的人或公司声称自己的机器人通过了 “图灵测试”,即使这些“图灵测试”仅仅是“缩略版本”。例如在英国皇家学会的测试规矩里,如果某台机器在一系列时长为5分钟的键盘对话中,被误认为是人类的比例超过30%,那么这台机器就被认为通过了图灵测试。于是出现了很多“能够在5分钟长度对话里骗过人类”的对话机器人。
历史上也有一些反对者曾经试图证明图灵测试只是“模仿”,而非智能的充分条件,比如“中文屋”问题:如果我们假设屋子里有一个不懂中文的人,和一本他的母语写的中文规则书,那么他就可以回答来自屋外的任何中文问题,但这个人本身并不具有对中文的理解能力。如果把这个屋里的人换成机器,那么反对者认为,即使机器可以通过中文描述的图灵测试,我们也不能称它具有“智能”。
“中文屋”能否成立其实很值得思考。因为如果图灵测试持续时间足够长、对话话题足够广,规则书就会因为需要包含过于多样的语法规则而无法真实存在。但是无论如何,“中文屋”、以及此后的“布洛克脑”等问题都让我们开始反思图灵测试本身。
机器智能真的会表现的和“人类智能”一样吗?完备的图灵测试可以判断机器能不能思考,但是不够完备的图灵测试又没有太多意义。它符合我们现在对机器智能的要求吗?
这两个问题的答案也许都是“并不能”。机器在计算能力上始终会高于人类,而我们也永远不会去追求机器智能和人类智能完全相等,比如让机器帮助人类判断“今天的菜是不是好吃”。强行追求机器和人类无差别或许在人工智能这条路上并非好标的。
然而,即便如此,ChatGPT通过图灵测试了吗?
并没有,这是ChatGPT自己说的。我测试了一下,对这个结果表示同意,因为它在某些关键问题上依然有点“智障”。
ChatGPT的威诺格拉德模式挑战(图灵测试的一个变种)结果:失败
ChatGPT无法通过图灵测试的原因有很多,比如它其实并没有完全获得“世界常识”,而是更专注于“语言知识”;比如它只是寻找概率最大的回答和句子格式,这是联想而非真正的逻辑推理。但就一个专注于语言的大模型来说来说,它的“说话水平”毫无疑问已经超过其他领域的主流人工智能模型。
有意思的是,最近有项研究重新审视了经典图灵测试,并使用图灵测试的论文内容作为基础,使用ChatGPT生成了一份更可信的论文版本,来评估它的语言理解和生成能力。写作辅助工具 Grammarly 认为ChatGPT 生成的论文得分比图灵原始论文高出14%。这或许有一定象征意义。
考虑到图灵测试所追求的并非对ChatGPT们长处的最佳利用。那么我们更应该思索的是,我们在未来会有一个比图灵测试更好的评价标准吗?现代是否需要一种测试去衡量各类生成式人工智能的进步,而不是仅仅以它们模仿或愚弄人类的能力为标准?
这或许是更加迫在眉睫的问题。
大语言模型的开始:马尔科夫、香农和语言模型
问题继续回到“智能”,人类心智中最根深蒂固难以去除的乃是文字。文字来到世间,为的就是把知识和思维保留下,让其能跨越时空。历史正是有了文字才成为历史,过去之所以称为过去,全靠文字来纪录轨迹。
哪怕对于人类来说,掌握文字也需要一些特殊技巧。因为文字这类符号系统是人类获取和沉淀知识的途径,也是人类组织思维的手段。作为目前使用最广泛的语言,有记录的英语词汇早已超过百万,还正在不断增加,而通过英语记录下来的文本数据更是数不胜数。
既然文字记录着人类的知识,那机器能从过去的文本中获得智能吗?这就来到了现代自然语言处理的范畴。
1913年,俄国数学家马尔科夫坐在他圣彼得堡的书房里,拿起笔和草稿纸删去了《尤金·奥涅金》的所有标点和空格—这是普希金在100年前创作的诗歌小说。紧接着,他统计了剩下的前两万个字母中元音、辅音的个数。
马尔科夫所做的统计示例[6]
马尔科夫发现,虽然这长串字母中有43%的元音,57%的辅音,但是元音与辅音之间的连接却截然不同,元音-元音、辅音-辅音、元音-辅音/辅音-元音连接分别出现了1104、3827和15069次。这意味着若随机抽取书中任何一个字母,如果结果是元音,那么下一个字母大概率是辅音,反之亦然。《尤金·奥涅金》的字母之间显然存在着某种可以被数学建模的统计特性。
上述过程中比较数学的说法就是,如果把字母当做随机变量,它上一个状态(上一个字母)与下一个状态(下一个字母)存在相关性。如果我们使用“转换概率”,即下一个字母出现元音/辅音的概率,来刻画这些相关性,这就形成了最简单的马尔科夫链特性,这也是最简单的“语言模型”。
我们之所以说最简单,是因为马尔科夫假设每一个字母出现的概率仅与前一个字母相关,这当然在现实世界里很少发生。因为通常真正理解一句话需要结合这句话的语境,也就是上下文里包含的信息。比如现在的网络流行语“YYDS”,可以翻译成“永远的神”,当然也可以认为是“远洋大厦”的缩写,这完全取决于语境本身。
那么,在数学上我们需要严格定义“上文”和“下文”都指什么。比如如果我们假设“上文”的范围是N,即一个词或者字母出现需要依赖往前数N个词的话,1948年香农提出的经典语言模型N-gram就进入了我们的视野。
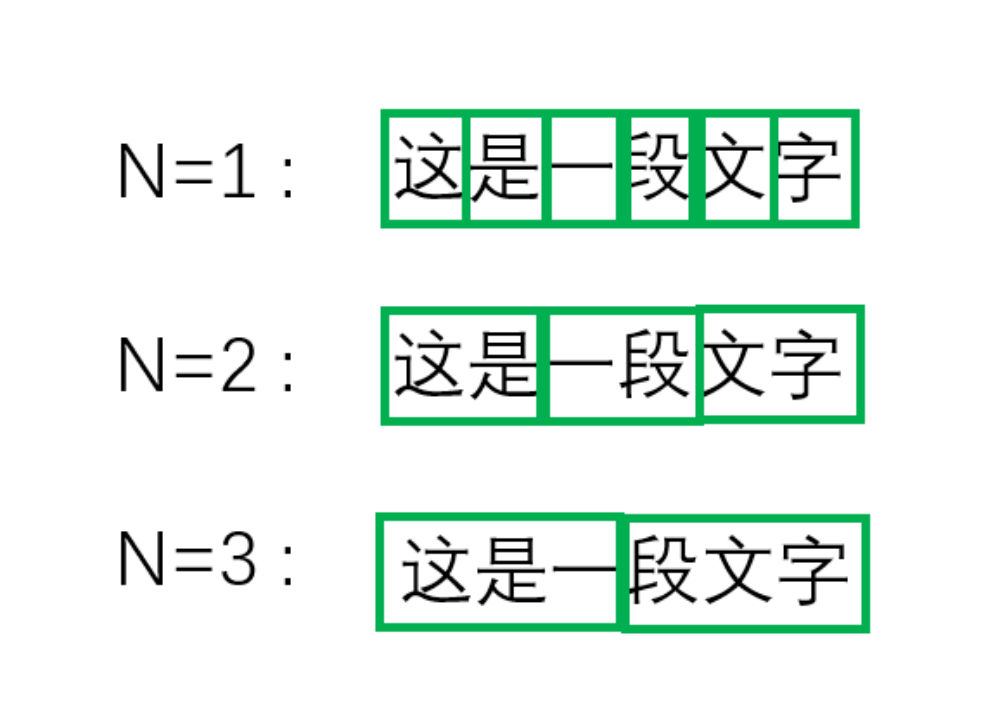
N-gram语言模型用于预测下N个文字时的运行方式(为防误解,请注意它是长度为N的滑动窗)
如同上图中的例子,我们也可以简单把这个语言模型做的事用一句比较“人话”的方式总结:
考虑前N个词,如果一个词/句子出现的概率越大,它真正出现后人们会觉得越自然,也就越符合语言规律,整句话也就越“像一句人话”。
如果用流浪地球2的经典台词为例来解释这句表述,就是这样:
1. 我相信人类的勇气可以跨越时间,跨越每一个历史、当下和未来!
2. 我相信勇气的人类可以跨越当下、时间和未来,跨越每一个历史!
3. 勇气人类的相信跨越跨越时间、历史、每一个当下和未来!
相信很多人会觉得第一句台词通顺且优雅,第二句虽然语句不通,但是大概会明白什么意思,但是第三句就基本没什么道理了,基本不会存在于地球上的人类语言里。那么,从统计角度,在“人类语言模型”里,第一句话发生的概率最大,第二句话次之,第三句话几乎不可能发生。这样,一段文本的合理性就得到了量化。
马尔科夫和香农的语言模型奠定了自然语言处理任务的基石。从那时起,单词、句子和段落之间的关系,也就是文本的合理性不再是虚无缥缈的概念,它变得可以被机器量化,也正是如此,“自然语言处理”正式成为“信息科学”的分支之一。机器翻译、自动问答、情感分析、文本摘要、文本分类、关系抽取等等自然语言处理的下游任务得以成立,并蓬勃发展。
很显然,越好的语言模型越是可以更好地理解一段文本的优劣,马尔科夫建立的语言模型来自一本书,那我们能找到更好的语言模型吗?
连接主义、神经网络语言模型——能从文本里读到真正的智能吗?
自从图灵测试被提出以来,关于如何模拟智能的探索就一直存在着多种不同的流派。
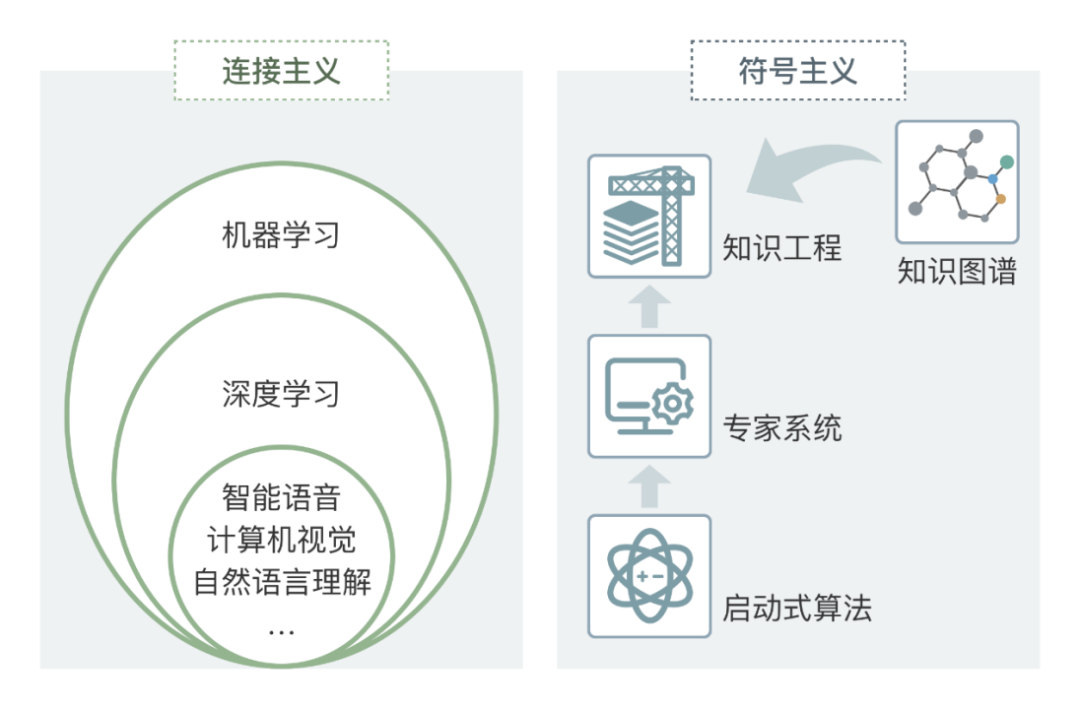 连接主义和符号主义
连接主义和符号主义
其中一派人被称为“符号主义”或“逻辑主义”,认为智能的基础是知识,知识可以用符号表示,探索让机器直接模拟智能的方法。
最开始这批科研人员并没有考虑“知识的来源”,只是尝试从现有的语言学知识分析文本结构,总结语言规律,进而完成较为复杂的文本推断等问题。然而,后来大家发现,智能的体现不能仅仅依靠推理本身,对一个智能系统来说,先验知识(对应人的记忆和经验)是更加重要的一环,但是仅依赖专家灌输先验知识分(专家系统)无论如何都比不上知识本身的膨胀速度,于是,知识工程,以及如何建立通用知识图谱就成了自然语言处理领域非常重要的研究方向之一。
事实上,在2013年以前,符号主义学派都是自然语言处理领域的主流。但是考虑到这里我们的主要话题是ChatGPT,这里不多做讨论,历史留给大家自行探索。
另一派人被称为“连接主义”,主张从人类大脑的神经结构出发,先让机器模拟人脑构造,再以此模拟智能。大家对这部分工作最熟知的应该是“神经网络”,这也是ChatGPT的开端。但在早期,神经网络在语言模型上远没有如今那么出色,它对很多文本任务的提升并不大,传统语言模型(比如N-gram模型)难以解决的问题,它依然无法可解。直到神经网络开始加深。
2012年,杰弗里·辛顿和他的学生在ILSVRC2012上用AlexNet(深度神经网络的一种)以超过第二名准确率10%的压倒性优势夺冠,开启了深度学习对其他人工智能领域的革新。大家对被埋在故纸堆里的神经网络然语言处理模型开展了一波“再发掘”,挖出了迄今为止依然非常经典的“词嵌入”(Word Embeding)方法。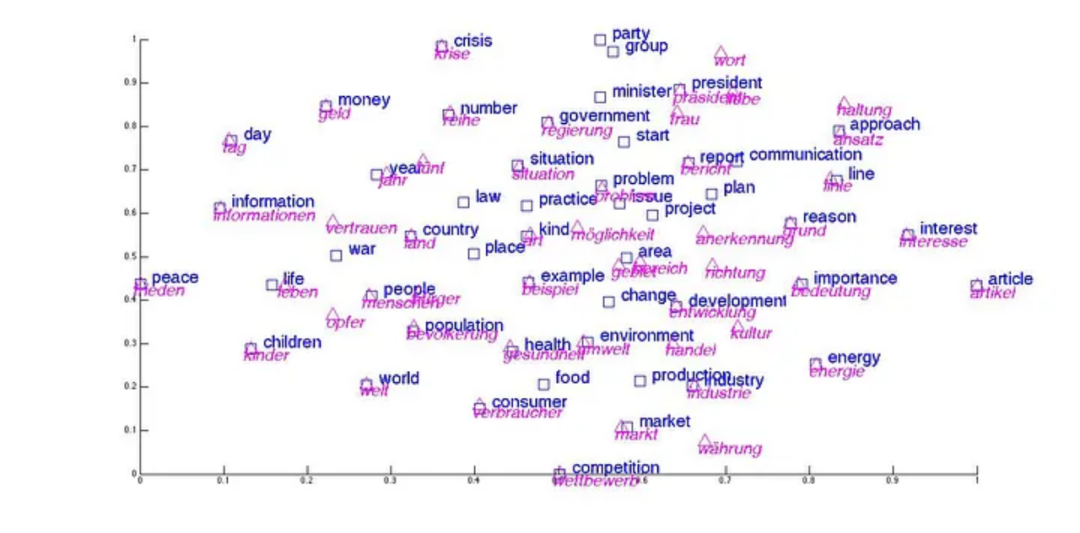
英语和德语单词词嵌入后可视化结果,可以看到语义相似单词非常重合
不过在这里,为了更深入解释“词嵌入”,我们需要继续请出马尔科夫和他的《尤金·奥涅金》。在本文的上一部分中,我们敬爱的马尔科夫先生对字母的发音方式做了统计建模,但考虑到发音方式和语言本身的关系并不明显。在这里我们稍微调整一下马尔科夫先生的目标,对《尤金·奥涅金》里的“单词”建立建模。然而,鉴于《尤金·奥涅金》里的“单词”数目会远远多于字母的元音/辅音数目,如果使用前述的单词间关系作为表示的话,不同“单词-单词”的组合关系会多得不可思议,也变得难以计算。
此时,“词嵌入”的优势就体现了出来。同样是《尤金·奥涅金》,“词嵌入”向量和对应“词嵌入”向量的神经网络语言模型会比仅用“单词”进行统计建模更高效。仿佛黎明中看到了曙光,神经网络语言模型成了此后的改进重点。因为,如果我们把《尤金·奥涅金》这本书换成更通用、更泛化的训练数据集(或者叫做语料库),或者直接用人类所有文本数据来训练一个模型,这个模型也许就可以“精通人类语言”和“人类知识”。
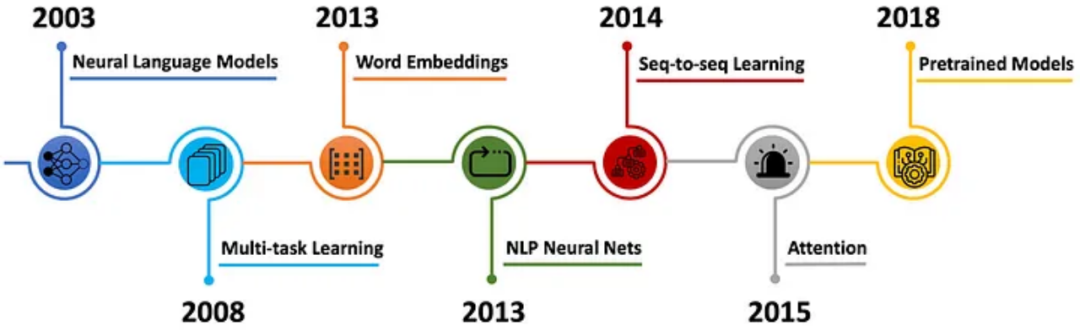 神经网络语言模型的一些里程碑式历史
神经网络语言模型的一些里程碑式历史
于是,在此后的数年间,大量神经网络语言模型不断出现,比如循环神经网络模型 (RNN) ,比如长短期记忆模型 (LSTM)。但是总体上,都没有脱离神经网络语言模型+各类改进的“词嵌入”向量来完成统计建模的范畴。在此过程中,“词嵌入”方法所无法解决的“多义词”难题也逐渐被改进。
同时,自然语言处理相关研究也深受深度神经网络影响,试图不断增加神经网络语言模型的层数或者模型参数,但是这种努力比起其他方面的进展,其实并不能算得上非常成功。
当然,现在回想,原因可能是当时大多采用半监督训练方法,可供训练的标注数据不足,网络本身也没有采用生成式方法,这样即使神经网络语言模型的层数增加或者模型参数增加,其训练数据也不能支持语言模型充分训练;另一个可能是以RNN和LSTM为代表的模型特征抽取和语言表示能力不足,对训练数据的利用不够高效。
这一切,直到Transformer,和基于Transformer的大语言模型出现,人们才找到通往“通用语言模型的曙光”。
大语言模型,大即是正义
自从深度学习问世以来,因为其层数越来越高,标注一个高质量数据集所需要成本也越来越大,那么如何在标注数据有限的情况下高质量完成训练,就成了一个非常重要的问题。
一个非常主流的思想就是“迁移学习”。在图像处理领域,“迁移学习”是指利用大数据集完成预模型训练后,再针对特定任务微调参数(Fine-Tuning)以适应不同图像任务。而在语言模型极为重要的自然处理领域,如果拥有一个足够强大的“语言模型”,去储存基本的单词、语义知识,再根据特定任务调整,是不是可以让性能更加提升?
答案是:可以
2018年6月,OpenAI公司提出初代GPT模型。同年10月,谷歌公司公布了自己的BERT模型,大幅度刷新了自然语言处理领域几乎所有最优记录,从此开启了预训练大模型时代。
在此后的4年时间里,预训练语言模型如 BERT 和 GPT(GPT-1和GPT-2,这些ChatGPT的前身),已成为当前自然语言处理领域的主流技术趋势。这些模型参数从3亿到1.75万亿不等,也因此被称作大语言模型(Large Language Model)。
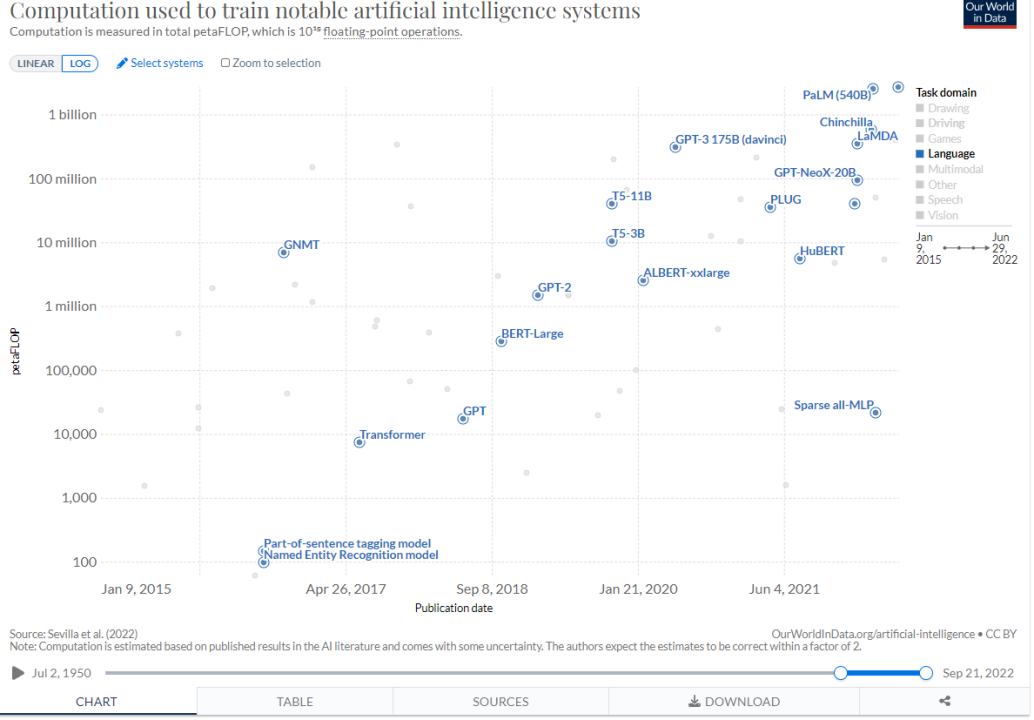
从2017年起,语言模型的模型参数不断提升直到10亿(图源:)
我必须在这一节强调,这些预训练大模型的本质是在使用更大的模型、更多的数据去找到对人类更好的、更通用的“语言模型”,就像我们的祖先在7万年前自豪的那样,大模型可以获得更多知识。也正是因此,包括BERT和GPT在内的大语言模型,在预训练过程中其实就已经获得了相当数量的词汇、句法和语义知识,仅仅只需要少量标记数据对模型细化,就可以完成各种各样的自然语言处理任务。
如果一定要问技术区别的话,BERT的训练过程更像让机器不断完成“完形填空”,而GPT的训练过程更像“单词接龙”,前者会更擅长语言理解问题,后者更擅长文本生成问题,这里存在一些技术区分。但是至少,他俩对普通人和各种文本处理任务,都已经“足够好”了。
大之后又如何,怎么让人用起来?
有了一个好的语言模型,剩下的就是让它“通用”。
我们现在生活在一个充满“人工智能算法”的社会,小度音箱、新闻推荐、有道翻译、Grammerly语法检查、美图增强,甚至图像风格转换随处可见。但是这些人工智能算法都只是“内嵌”在各种已有产品、或者功能里,从来没有外显到直接影响用户本身。
这就让越来越多人对“人工智能”这个词逐渐有了一个“思想钢印”,觉得它最合适的场景还是去处理某个垂直任务。如果打开某云平台网站,我们往往会看到在人工智能标签下琳琅满目的项目,人脸识别会被分为“人脸检测与五官定位、人脸属性识别、人体检测….”等等6种。
学术界也是如此,虽然自然语言处理的关键在于理解单词、句子的结构这些“语言知识”本身,但它依然会被分为“机器翻译,语言生成,文本归纳” 等等任务,而其评价标准和对应的产品形态各不相同。
预训练大模型的出现开始让这些下游领域产生被“一统江湖”的苗头,这些任务从原本的“设计模型,从零开始训练”,调整为“加载预训练模型,微调任务参数”。如果按照一贯思维,面向公司的“通用语言模型”到这种程度也就够了,模型开发商可以向下游产品厂商收取模型服务费用,而模型开发商可以专注于提升模型对的精度,简化开发难度。这就是Google对于BERT和后续模型的想法。
OpenAI与其他公司之间对 “大语言模型”的设计的根本分歧便在这里。他们希望让这套模型更普适,把“通用语言模型”做成一个直接面向用户的产品。而要达成这个目标,就必须考虑继续优化“微调”这一步,直到模型本身不需要任何调整干预即可直接执行所有自然语言处理任务。

《流浪地球2》中的MOSS
移除“微调”,理解人类“命令/指示”,这就是从GPT2.0到GPT3.0,再到ChatGPT,OpenAI所遵循的设计思路。
因为对于人类用户,最好的方式就是语言模型可以直接理解我们对它的“指令”或者“示例”,根据指令去调用相应的自然语言处理下游任务。于是GPT选择了从“微调”到“提示学习(Prompt Learning)”,再到“指示学习(Instruct Learning)”的技术路径,一步一步降低了用户使用门槛,把“通用语言模型”调整到适配正常人类的习惯,这样才在现在获得巨大成功。 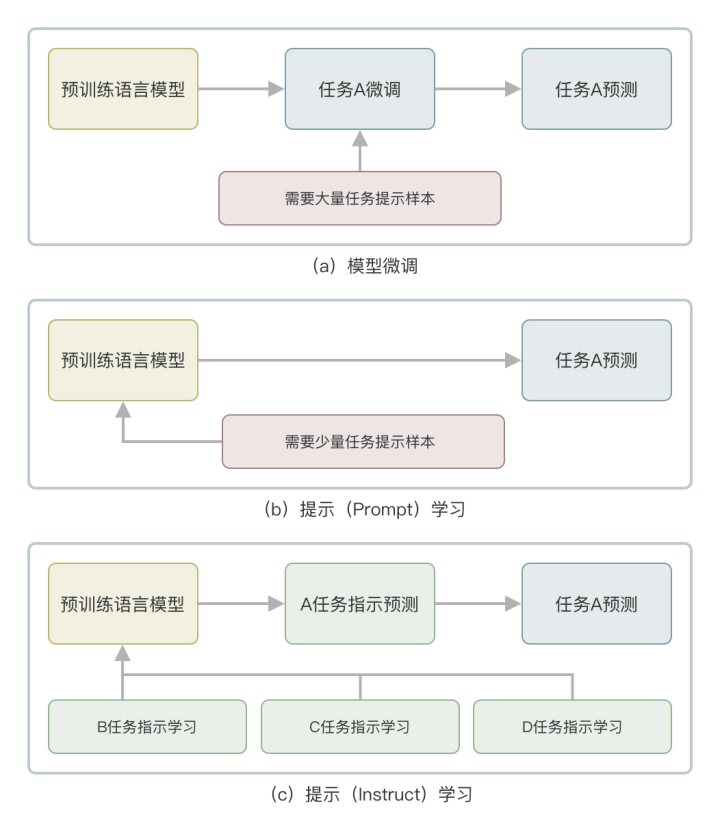
ChatGPT在大语言模型的基础上,一步一步通过带有人类反馈的增强学习(MOSS:人在回路)注入人类关于“命令”、“指示”、“友善”等先验知识,让“通用语言模型”的回答更“平易近人”、“更有用”、“更无害”,同时可以理解用户指令,应该是ChatGPT最大的贡献之一。
这也完美符合了我们对未来“通用人工智能”的期待。
ChatGPT和我们的未来
ChatGPT毫无疑问是人工智能领域的重大突破,正如很多人所说,它的突破或许并不显著的体现在技术进步,而是在于它成功让人工智能产品以一种用户可以接受的形态进入大家的生活。对大部分人来说,它比我们之前的任何产品都更接近“通用人工智能”。
同时,不可否认的是,ChatGPT依然存在很多问题。ChatGPT依然是一个基于统计规律的大语言模型,它有人类无懈可击的语言天赋,但是只能做联想而不能完成“逻辑推理”。从这个角度来讲,ChatGPT会倾向于制造出令人信服的回应,当然其中可能包含“生成的”几个事实错误、虚假陈述和错误数据,因为作为一个自然语言处理模型,它也不知道高达数十PB的无监督训练数据里什么是“事实”,这更像一个有点滑头的“虚拟助手”。另外,因为在训练过程中,为了识别人类指令而注入过大量“指令”知识,ChatGPT会对“指令”本身非常敏感,但同时会对一些上下文无关,需要“事实依据”做判断的歧义词识别不高。
但是这些问题似乎不难解决。目前的ChatGPT依然只是离线版本。在我们看到的bing(在线版本)的一些应用示例里,部分问题似乎已经被缓解。事实上,如果ChatGPT能够对信息源进行可信度分级,并且在生成的回答中列出参考信息源,回答的可信度问题应该会得到一定程度的规避。如果能在未来接入一些专家构建的专业知识库(比如金融知识图谱),它可以被转变为特定领域的专家。
对大多数普通人来说,ChatGPT都是一个合格的助手,因为所有关于人类语言的技能它都很精通(或者在可见的未来里会很精通),比如归纳总结、翻译、书写文章、风格修正、翻译、润色、写代码等等,因而,从事这些工作的劳动者,如果不能掌握将ChatGPT作为助手的技能,也许将会成为最早期被机器取代的人。
然而,即便如此,我始终认为,AI替代的不是简单的某个行业,而是不会使用AI的从业者。AI带给人类的意义也不是替代我们的工作,而是让我们从一些重复性工作解放出来,让人类去真正思考“什么铸就了人类的唯一”。
这或许才是千万年以后,人类回望时间长河,在被历史冲刷下还能保留,甚至愈发辉煌的人类丰碑。(本文作者崔原豪为北京邮电大学信息与通信工程博士、中国计算机学会科学普及工作委员会主任助理,曾担任电影《流浪地球2》科学顾问。除特别注明外,文中图片由作者提供。)注释:知识表示:即knowledge representation,是指把知识客体中的知识因子与知识关联起来,便于人们识别和理解知识。知识表示是知识组织的前提和基础,任何知识组织方法都是要建立在知识表示的基础上。
参考文献:
1.尤瓦尔, 赫拉利, 人类简史, 等. 北京: 中信出版社, 2017: 12-15 Юваль Ной Харари[J]. Краткая история человечества./Переводчик Линь Цзюньхун-Пекин: издательство CITIC, 2017: 12-15.
2.程林 . 当代科幻中的人机关系——主持人语 [J]. 广州大学学报(社科版),2020(2):
3.Searle J R. Minds, brains, and programs[J]. Behavioral and brain sciences, 1980, 3(3): 417-424.
4.Noever D, Ciolino M. The Turing Deception[J]. arXiv preprint arXiv:2212.06721, 2022.
5.Goody J, Watt I. The consequences of literacy[J]. Comparative studies in society and history, 1963, 5(3): 304-345.
6.Markov A A. An example of statistical investigation of the text Eugene Onegin concerning the connection of samples in chains[J]. Science in Context, 2006, 19(4): 591-600.
7.Shannon C E. A mathematical theory of communication[J]. The Bell system technical journal, 1948,
8.Bengio Y, Ducharme R, Vincent P. A neural probabilistic language model[J]. Advances in neural information processing systems, 2000, 13.
9.Thang Luong, Hieu Pham, and Christopher D. Manning. 2015. Bilingual Word Representations with Monolingual Quality in Mind. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, pages 151–159, Denver, Colorado. Association for Computational Linguistics.
10.A Brief History of Natural Language Processing — Part 2, Antoine Louis, @antoine.louis/a-brief-history-of-natural-language-processing-part-2-f5e575e8e37

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}