
图源:pixabay
撰文 | 孙睿晨
今天,ChatGPT等大型语言预训练神经网络模型已经成为广为人知的名字,GPT背后的算法内核——人工神经网络算法,在此之前,却曾经历了跌宕沉浮的80年,这80年间,除了少数的几个爆发时刻,大部分时候,这个理论处于沉寂、无人问津,甚至经费“毒药”的状态。
人工神经网络的诞生,来自不羁天才皮特斯与当时已功成名就的神经生理学专家麦卡洛克的黄金组合,然而,他们的理论超越了他们那个时代的技术水平,因而没能获得广泛关注与实证验证。
幸而,在诞生之初的二十多年里,不停地有研究者进来添砖加瓦,人工神经网络领域从最初最简单的神经元数学模型和学习算法进化到了具有学习能力的感知机模型,然而,来自其他研究者的质疑与“感知机”创始人之一罗森布拉特在航行中陨难共同袭来,在那之后,这个领域陷入了二十多年的寒冬,直到反向传播算法被引入人工神经网络的训练过程中。
在那之后,经历了沉寂的20年,人工神经网络方面的研究才终于又获得重启,蓄力的近20年中,卷积神经网络与递归神经网络依次登场。
但该领域在学术界与产业界的飞速发展还是要等到17年前,硬件方面的突破——通用计算GPU芯片的出现,于是,才有了今天,随着ChatGPT等大型语言预训练神经网络模型,成为广为人知的名字。
从一定意义上,人工神经网络的成功是一种幸运,因为,不是所有的研究,都能等到核心的关键突破,等到万事齐备。在更多的领域,技术的突破出现得太早或是太晚,导致只能慢慢消亡。然而,这幸运中,不能被忽略地是那些身处其中的研究者们的坚定与执着,靠着这些研究者们的理想主义,人工神经网络才走过了它跌宕沉浮的80年,终得正果。
麦卡洛克-皮特斯神经元
1941年,沃伦·斯特吉斯·麦卡洛克(Warren Sturgis McCulloch)跳槽到美国芝加哥大学医学院,担任神经生理学教授。搬到芝加哥后不久,一位朋友介绍他认识了沃尔特·皮特斯(Walter Pitts)。正在芝加哥大学攻读博士的皮特斯与麦卡洛克对神经科学与逻辑学有共同的兴趣,于是二人一拍即合,成为了科研上志同道合的好友和伙伴。皮特斯生性好学,12岁时便在图书馆读完了罗素与怀特黑德所著的《数学原理》,并致信罗素,指出书中的几处错误。罗素很欣赏这位小读者的来信,回信邀请他到剑桥大学读书(尽管皮特斯只有12岁)。然而,皮特斯的家人受教育程度低,无法理解皮特斯的求知欲、反而时常恶语相向。皮特斯与原生家庭关系逐渐恶化,他15岁便离家出走。自那之后,皮特斯成为了芝加哥大学校园里的一名流浪汉,白天选择喜欢的大学课程旁听,晚上随便找个课室睡觉。在皮特斯认识麦卡洛克时,他虽然已是学校在册博士生,但仍没有固定住处。麦卡洛克了解到这个情况后,便邀请皮特斯到自家居住。
二人认识的时候,麦卡洛克已经发表了多篇关于神经系统的论文,是该领域有名的专家。而皮特斯虽然还是一名博士生,但他已经在数理逻辑领域有所建树,并获得包括冯诺依曼等领域大牛们的赏识。尽管二人专业领域非常不同,但他们都对人脑的工作原理深感兴趣,并坚信数学模型可以描述、模拟大脑的功能。在这个共同的信念的驱使下,二人合作发表了多篇论文。他们建立了第一个人工神经网络模型。他们的工作为现代人工智能与机器学习领域奠定了基础,而他们二人也因此被公认为神经科学与人工智能领域的开创者。
1943年,麦卡洛克和皮特斯提出了最早的人工神经网络模型:麦卡洛克-皮特斯神经元(McCulloch-Pitts Neuron)模型[1]。该模型旨在用二进制开关的“开”与“关”的机制来模拟神经元的工作原理。该模型的主要组成部分为:接收信号的输入节点,通过预设阈值处理输入信号的中间节点,以及生成输出信号的输出节点。在论文中,麦卡洛克与皮特斯证明了该简化模型可以用于实现基础逻辑(如“与”、“或”、“非”)运算。除此以外,该模型还可以用于解决简单问题,如模式识别与图像处理。
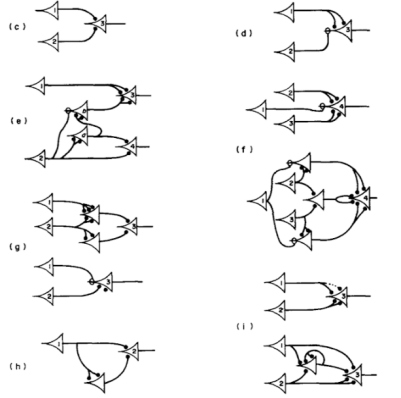
麦卡洛克-皮特斯神经元图源:~./epxing/Class/10715/reading/McCulloch.and.Pitts.pdf
赫布式学习(Hebbian Learning)
1949年,加拿大心理学家唐纳德·赫布(Donald Hebb)出版了一本题为《行为的组织(The Organization of Behavior)》,并在书中提出了著名的赫布式学习(Hebbian Learning)理论[2]。该理论认为“共同激活的神经元往往是相互连接的(Cells that fire together, wire together)”,也就是神经元具有突触可塑性(synaptic plasticity, 突触是神经元之间相互连接进行信息传递的关键部位),并认为突触可塑性是大脑学习与记忆功能的基础。
机器学习理论中的关键步骤是如何使用不同的更新算法(update rule)来更新模型。使用神经网络模型进行机器学习时,需设定初始模型的架构与参数。在模型训练过程中,每一个来自训练数据集中的输入数据都会导致模型更新各项参数。这个过程,就需要使用到更新算法。赫布式学习理论为机器学习提供了最初更新算法:Δw = η x xpre x xpost。Δw为突触模型的参数的变化大小, η为学习速率,xpre 为突触前神经元活动值大小,xpost为突触后神经元活动值大小。
赫布更新算法为利用人工神经网络来模仿大脑神经网络的行为提供了理论基础。赫布式学习模型是一种无监督学习模型——该模型通过调节其感知到的输入数据之间联系程度的强弱来实现学习目的。也正因为如此,赫布式学习模型在对输入数据中的子类别聚类分析尤其擅长。随着神经网络的研究逐渐加深,赫布式学习模型后来也被发现适用于强化学习等其他多个细分领域。
感知机 (Perceptron)
1957年,美国心理学家弗兰克·罗森布拉特(Frank Rosenblatt)首次提出感知机(Perceptron)模型,并且首次使用了感知机更新算法[3]。感知机更新算法延伸了赫布更新算法的基础,通过利用迭代、试错过程来进行模型训练。在模型训练时,感知机模型对于每一个新的数据,计算出模型预测的该数据输出值与实际测得的该数据输出值的差值,然后使用该差值更新模型中的系数。具体方程如下:Δw = η x (t - y) x x。在提出最初的感知机模型后,罗森布拉特继续深入探讨、发展感知机相关理论。1959年,罗森布拉特成功研发出一台使用感知机模型识别英文字母的神经计算机Mark1。
感知机模型与麦卡洛克-皮特斯神经元类似,也是基于神经元的生物学模型,以接收输入信号,处理输入信号,生成输出信号为基本运作机理。感知机模型与麦卡洛克-皮特斯神经元模型的区别在于后者的输出信号只能为0或1——超过预设阈值为1,否则为零——而感知机模型则使用了线性激活函数,使得模型的输出值可以与输入信号一样为连续变化值。另外,感知机对每一条输入信号都设置了系数,该系数能影响每条输入信号对于输出信号的作用程度。最后,感知机是学习算法,因为其各输入信号的系数可以根据所看到的数据进行调整;而麦卡洛克-皮特斯神经元模型因没有设置系数,所以其行为无法根据数据反馈进行动态更新。
1962年,罗森布拉特将多年关于感知机模型的研究集结成《神经动力学原理:感知机与大脑原理(Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms)》一书。感知机模型在人工智能领域是一项重大的进步,因为它是第一种具有学习能力的算法模型,能自主学习接收到的数据中的规律与特点。并且,它具有模式分类的能力,可以将数据根据其特点自动分为不同的类别。另外,感知机模型相对简单,所需计算资源也较少。
尽管感知机具有种种优点与潜力,但它毕竟是一个相对简化的模型,存在许多局限性。1969年,计算机科学家马文·明斯基(Marvin Minsky)与西摩尔·派普特(Seymour Papert)合作出版了《感知机(Perceptron)》一书[5]。在书中,两位作者对感知机模型进行了深入的批判,分析了以感知机为代表的单层神经网络的局限,包括但不限于“异或”逻辑的实现以及线性不可分问题。但是,二位作者与罗森布拉特都已经意识到,多层神经网络可以解决这些单层神经网络不能解决的问题。可惜的是,《感知机》一书对感知机模型的负面评价影响巨大,使得公众与政府机构对于感知机研究一下子失去了兴趣。1971年,感知机理论的提出者兼头号支持者罗森布拉特不幸在一次出海航行中遇难,享年43岁。在《感知机》一书与罗森布拉特之死的双重打击下,与感知机相关的论文发表数目逐年迅速减少。人工神经网络的发展进入了“寒冬”。
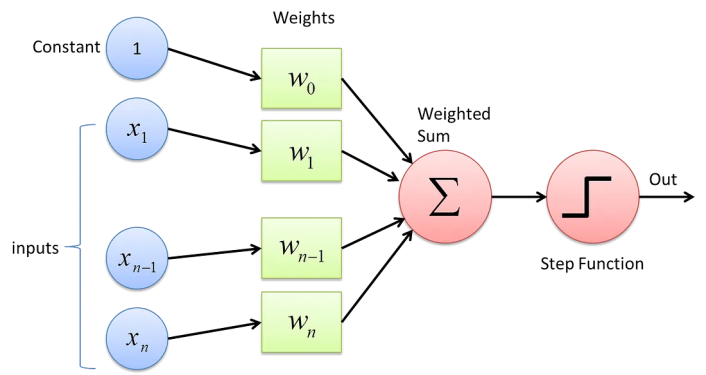
感知机模型
图源:
反向传播算法
多层神经网络能够解决单层神经网络无法解决的问题,但它带来了新的问题:更新多层神经网络模型的每一层神经元的权重涉及到大量精确计算,而普通的计算方法费时费力,使得神经网络学习过程变得非常缓慢,实用性很差。
为了解决这个问题,美国社会学家、机器学习工程师保罗·韦伯(Paul Werbos)在1974年的哈佛大学的博士论文《Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences》中提出了反向传播算法(backpropagation)[6]。该算法的基本思想是通过将预测到的输出值与实际输出值之间的误差从输出层反向传播,从而调整神经网络各个神经元的权重。这个算法的本质是根据微积分中常用的链式法则从输出层到输入层反向(沿着负梯度方向)实现对由多层感知机组成的神经网络的训练。
令人感到遗憾的是,韦伯的论文在发表后很长一段时间内都没有得到足够的关注。直到1985年,加州大学圣地亚哥分校的心理学家大卫·鲁梅尔哈特(David Rumelhart)、认知心理学家与计算机学家杰弗里·辛顿(Geoffrey Hinton),以及计算机学家罗纳德·威廉姆斯(Ronald Williams)合作发表了一篇关于反向传播算法在神经网络中的应用的论文[7]。这篇论文在人工智能领域获得了很大的反响。鲁梅尔哈特等人的想法与韦伯的想法本质上是相似的,但鲁梅尔哈特他们没有引用韦伯的论文,这一点近来常常为人诟病。
反向传播算法在人工神经网络的发展中起着关键作用,并使得深度学习模型的训练成为可能。自从反向传播算法于八十年代重新受到人们的重视以来,它被广泛应用于训练多种神经网络网络。除了最初的多层感知机神经网络以外,反向传播算法还适用于卷积神经网络、循环神经网络等。由于反向传播算法的重要地位,韦伯与鲁梅尔哈特等人被认为是神经网络领域的先驱之一。
事实上,反向传播算法是人工智能领域的“文艺复兴”时代(20世纪80年代和90年代期间)的重要成果。并行分布式处理(Parallel Distributed Processing)是这段时间的主要方法论。该方法论关注多层神经网络,并推崇通过并行处理计算来加速神经网络的训练过程与应用。这与先前的人工智能领域的主流思想背道而驰,因而具有划时代的意义。另外,该方法论受到了计算机科学以外,包括心理学、认知科学,以及神经科学等不同领域的学者的欢迎。因此,这段历史常常被后人认为是人工智能领域的文艺复兴。
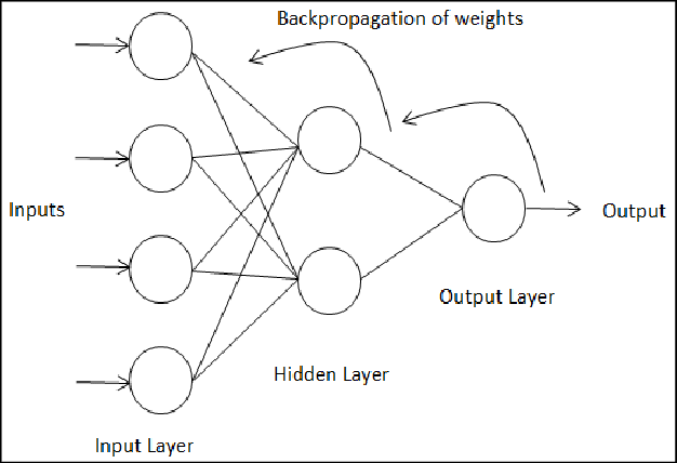
反向传播算法原理
图源:
卷积神经网络(Convolutional Neural Network, CNN)
如果把麦卡洛克·皮特斯神经元作为人工智能诞生的标志,那么美国可以说是人工神经网络的发源地。人工神经网络诞生后的三十年里,美国在人工智能领域一直扮演着主角,孕育了感知机、反向传播算法等关键技术。但在第一个人工智能的"寒冬"中,包括政府、学术界在内的美国各方人士对人工神经网络的潜能失去了信心,大大放缓了对神经网络技术迭代的支持与投入。也因为如此,在这个席卷美国的”寒冬“中,其他国家的人工神经网络的研究走到了历史发展的聚光灯之下。卷积神经网络与递归神经网络就是在这样的背景下出场的。
卷积神经网络是一种包含了卷积层,池化层,以及全连接层等多种独特结构的多层神经网络模型。该模型利用卷积层提取出输入信号的局部特征,然后通过池化层降低数据的维度与复杂性,最后通过全连接层将数据转化为一维的特征向量并生成输出信号(一般为预测或分类结果)。卷积神经网络的独特结构使得它在处理具有网格结构属性的数据(图像,时间序列等)时尤有优势。
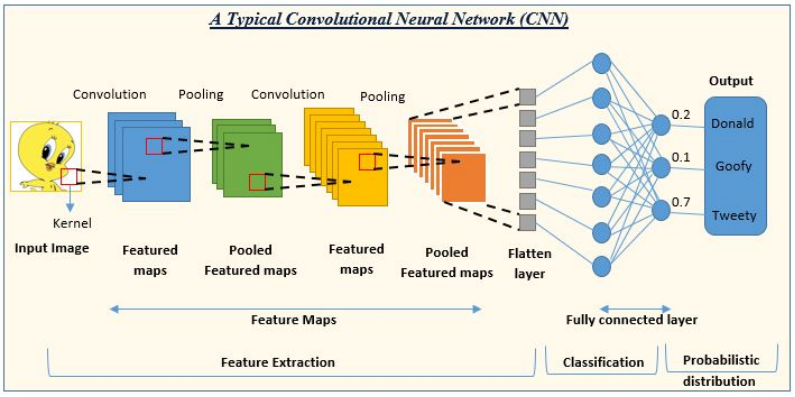
卷积神经网络
图源:
最早的卷积神经网络是日本计算机科学家福岛邦彦(Kunihiko Fukushima)于1980年提出[8]。福岛所提出的模型包含卷积层与下采样层,是当今主流卷积神经网络结构仍然一直沿用的结构。福岛的模型与今日的卷积神经网络唯一不同之处在于前者没有使用反向传播算法——如前文所叙,反向传播算法要等到1986年才受到关注。由于福岛的卷积神经网络模型没有该算法的助力,该模型与当时的其他多层神经网络一样存在训练时间长、计算复杂的问题。
1989年,任职于美国贝尔实验室法国计算机科学家杨·立昆(Yann LeCun)及其团队提出了名为LeNet-5的卷积神经网络模型,并在该模型中使用了反向传播算法进行训练[9]。立昆证明了该神经网络可以用于识别手写数字与字符。这标志着卷积神经网络在图像识别中的广泛应用的开始。
递归神经网络(Recursive Neural Network, RNN)
与卷积神经网络一样,递归神经网络也是一类具有独特结构特征的神经网络。该类神经网络的主要结构特征在于各层级间具有递归关系,而不是顺序关系。由于以上这些特殊结构特征,递归神经网络特别适于处理自然语言以及其他文本类的数据。
1990年,美国认知科学家、心理语言学家杰弗里·艾尔曼(Jeffrey Elman)提出了艾尔曼网络模型(又称为简化递归网络)[10]。艾尔曼网络模型是首个递归神经网络。艾尔曼利用该模型证明了递归神经网络能够在训练时维持数据本身的先后顺序性质,为日后该类模型在自然语言处理领域的应用奠定了基础。
递归神经网络存在梯度消失现象。在使用反向传播算法训练神经网络时,离输入近的层级的权重更新梯度逐渐变得近似于零,使得这些权重变化很慢,导致训练效果变差。为了解决这个问题,1997年,德国计算机科学家瑟普·霍克赖特(Sepp Hochreiter)及其博士导师于尔根·施密德胡伯(Jürgen Schmidhuber)提出了长短期记忆网络[11]。该模型为一种特殊的递归神经网络模型。它引入了记忆节点,使得模型具有更好的长期记忆存留的能力,从而化解了梯度消失现象。该模型目前仍是使用最普遍的递归神经网络模型之一。
通用计算GPU芯片
2006年,美国英伟达公司(NVIDIA)推出了第一款通用计算GPU(图形处理单元)芯片并将其命名为CUDA(Compute Unified Device Architecture)。在此之前,GPU本是专门用于图形渲染与计算的芯片处理器,常用于计算机图形学相关的应用(如图像处理,游戏场景实时计算渲染,视频播放与处理等)。CUDA允许通用目的的并行计算,使原本仅能调用CPU(中央处理单元)的任务可以通过GPU来完成计算。GPU的强大的并行计算能力使其能够同时执行多个计算任务,并且计算速度比CPU更快,适合矩阵运算。神经网络的训练往往需要进行大规模矩阵和张量运算。在通用GPU出现之前,人工神经网络的发展长期受到传统的CPU有限计算能力的限制。这种限制包括了对于理论研究的创新以及对现有模型的产品化、产业化的应用。而GPU的出现,让这两方面的掣肘被大大削弱了。
2010年,施密德胡伯团队中的博士后研究员丹·奇雷尚(Dan Ciresan)利用GPU实现了对卷积神经网络训练的显著加速[12]。但GPU真正在人工神经网络领域里声名大噪是在2012年。那一年,加拿大计算机科学家亚历克斯·克里泽夫斯基(Alex Krizhevsky)、伊利亚·苏茨克维(Ilya Sutskever)以及前文提到过的杰弗里·辛顿提出了亚历克斯网络模型(AlexNet)[13]。亚历克斯网络模型本质上是一类卷积网络模型。克里泽夫斯基等人在训练模型时使用了GPU,并用该模型参加了一个国际著名的图像分类与标记的竞赛(ImageNet ILSVRC)。令人意外的是,该模型最后竟以大比分的优势获得了冠军。亚历克斯网络模型的成功极大地激发了各界对于人工神经网络在计算机视觉领域应用的兴趣与关注。
生成式神经网络与大型语言模型
递归神经网络可以逐字连续生成文本序列,因此常常被认为是早期的生成式神经网络模型。然而,尽管递归神经网络善于处理、生成自然语言数据,但它对于长序列数据一直无法有效捕捉全局信息(对于距离较远的信息无法进行有效联系)。
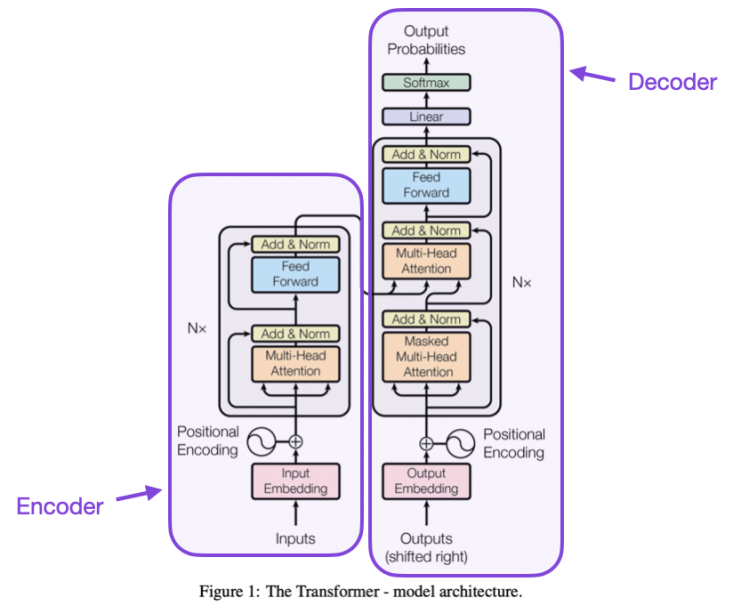
变压器模型 图源:[14]
2017年,美国谷歌公司的研究员阿希瑟·瓦斯瓦尼(Ashish Vaswani)等人提出了变压器模型(Transformer)[14]。该大型神经网络分为编码器与解码器两个主要部分。编码器对输入序列进行编码处理,通过自注意力层等来进一步处理编码后的信息。此后,信息传至解码器,并经过解码器部分的自注意力层等网络结构来生成输出序列。该模型的重要创新在于自注意力层(self-attention)。自注意力层使得神经网络模型能摆脱顺序处理文本的局限性,而是直接去文本中的不同位置抓取信息并捕捉各处信息之间的依赖关系,并且并行化计算不同位置之间在语义上的相关性。变压器模型的横空出世对自然语言处理领域乃至整个人工智能领域产生了巨大影响。在短短的几年里,变压器模型已经被广泛用在各类人工智能大模型中。
在层出不穷基于变压器结构的大型语言模型中,OpenAI公司推出的聊天机器人ChatGPT最为出名。ChatGPT所基于的语言模型为GPT-3.5(生成式预训练变压器模型-3.5)。OpenAI公司在训练该模型时用了大量的语料库数据,使其最终具备了广泛的语言理解能力与生成能力,包括提供信息、交流,文本创作、完成软件代码写作、以及轻松胜任各类涉及语言理解相关的考试。
尾声
几周前,我去参加一个中学生与科研人员共进午餐的志愿者活动。活动上,我与几名十五六岁的中学生聊天。很自然的我们就聊到了ChatGPT。我问他们:”你们用ChatGPT吗?你们可以跟我说实话,我不会告诉你们的老师的。"其中一位男生腼腆的笑了笑,说他现在已经离不开ChatGPT了。
80年前,四处流浪的皮特斯只能想象着那能够模拟大脑功能的数学模型。而在今天年轻人的世界里,神经网络不再仅是虚幻的数学公式,而变得无时无出不在。下一个80年会发生什么?人工神经网络中会像人类的神经网络一样产生意识吗?碳基大脑会持续主宰硅基大脑吗?还是会被硅基大脑主宰?
参考文献:
1.Warren S. McCulloch and Walter Pitts. "A Logical Calculus of Ideas Immanent in Nervous Activity." The Bulletin of Mathematical Biophysics, vol. 5, no. 4, 1943, pp. 115-133.
2.Donald O. Hebb. "The Organization of Behavior: A Neuropsychological Theory." Wiley, 1949.
3.Frank Rosenblatt. "The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain." Psychological Review, vol. 65, no. 6, 1958, pp. 386-408.
4.Frank Rosenblatt. "Principles of Neurodynamics: Perceptrons and the theory of brain mechanisms." MIT Press, 1962.
5.Marvin Minsky and Seymour Papert. "Perceptrons: An Introduction to Computational Geometry." MIT Press, 1969.
6.Paul Werbos. "Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.". Harvard University, 1974.
7.David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. "Learning representations by back-propagating errors." Nature, vol. 323, no. 6088, 1986, pp. 533-536.
8.Kunihiko Fukushima. "Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position." Biological Cybernetics, vol. 36, no. 4, 1980, pp. 193-202.
9.Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. "Gradient-based learning applied to document recognition." Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278-2324.
10.Jeffrey L. Elman. "Finding Structure in Time." Cognitive Science, vol. 14 1990, pp. 179-211.
11.Sepp Hochreiter and Jürgen Schmidhuber. "Long Short-Term Memory." Neural Computation, vol. 9, no. 8, 1997, pp. 1735-1780.
12.Dan C. Ciresan, Ueli Meier, Luca Maria Gambardella, and Jürgen Schmidhuber. "Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition." Neural Computation, vol. 22, no. 12, 2010, pp. 3207-3220.
13.Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. "ImageNet Classification with Deep Convolutional Neural Networks." Advances in Neural Information Processing Systems, 2012, pp. 1097-1105.
14.Vaswani, Ashish, et al. "Attention is All You Need." Advances in Neural Information Processing Systems, 2017, pp. 5998-6008.

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}