阅读:0
听报道
导语:
人工智能(AI)高度依赖于高质量有标识的大数据,在一个生物学假说驱动、效率低下、试错为主的新药创新领域,毋庸置疑,这将会显著提升新药研发流程中某些阶段的效率。但不管自古英雄出少年的IT创业精英风起云涌,还是有数十年研发经验的医药界老兵坐观潮起潮落,都缺乏对人工智能+新药研发全面的理性认识。鉴于此,挂一漏万,笔者愿与大家分享我们对于人工智能 +新药研发的观点和态度,分别从两个方面,理解疾病-影像诊断及生物学新机制/新靶点的发现,和设计药物-活性预测及化合物库的产生与合成,探讨人工智能在新药研发中的实与虚。
撰文 | 李 伟(瑞璞鑫(苏州)生物科技有限公司)
黄 牛(北京生命科学研究所)
责编 | 叶水送
1人工智能的崛起
天地玄黄,人类作为拥有NI (Natural Intelligence) 的生物,孤零零诞生于宇宙洪荒。从直立行走、刀耕火种、蒸汽电机、登月升空,到无处不在的互联网,人类在宇宙探索中实现了自我认知。从亚里士多德的形而上学,到牛顿的三大运动定律,再到爱因斯坦的相对论,这一切都闪耀于璀璨银河中。

作为万物之灵长的人类,不再满足于吃苹果获得智慧,而是期望在孤独的宇宙中创造出新的智能生命——人工智能(Artificial Intelligence)。时光荏苒,1997年深蓝战胜国际象棋大师卡斯帕罗夫后仅仅20年,人工智能便横扫人类最复杂棋盘游戏——围棋。短短不到一年时间,人工智能的称号从籍籍无名的阿尔法狗(AlphaGo)变成无人不知的大师(Master),再进化到已不爱搭理人类,左右互搏、自我学习的“零”(AlphaGo Zero)。
人工智能迅速蹿红,阿西莫夫的机器人“三定律”似乎已近在咫尺,不仅朋友圈里充斥着各种夸张报道和炒作宣传人工智能,如即将抢走人类饭碗的传闻,即使是严谨求实的学术圈、工业界也是热情洋溢,常有人言必称“我的朋友胡适之人工智能”,遑论永远盯着明天的投资界的追捧,大有一番“千红万紫安排著,只待新雷第一声”的气象。

其实严格来讲,人工智能算不得“新雷”,它始于1956年的达特茅斯会议,已有60多年的历史,涵盖众多学科和技术,包括机器人学、语音识别、自然语言识别与处理、图像识别与处理、机器学习等等。之前虽也有潮起潮落,但并无大风大浪。近年来,得益于迅猛增长的计算能力、深度学习方法的引入以及大数据的兴起,这“三板斧”的推波助澜,人工智能在多个行业崭露头角,其中笔者所在的生物医药行业就是人工智能席卷的重镇之一。

面对目前这批风口上的人工智能公司,我们总归要问所有新兴技术都需要面对的终极问题:人工智能目前到底处在技术成熟度曲线(Hype Cycle)的哪个阶段?人工智能能否正面PK当前可用的其它技术?在可预见的将来,人工智能究竟能做到什么样的程度?人工智能的征途可以是星辰和大海,但前行的补给却不能是画饼。缥缈的远景不是我们兴趣所在,毕竟DeepMind能否真的“Solve intelligence. Use it to make the world a better place”,比Deep Thought告诉我们宇宙的终极答案是42 ——语出科幻圣经《银河系漫游指南》—— 要实际得多。
2人工智能进行疾病诊断,竞争还是合作?
在整个大的医疗领域,疾病诊断,尤其是医学影像(X射线、超声、MRI 、CT和PET等)是人工智能比较得到认可的方向。2017年,Arterys公司的影像平台Cardio AI成为FDA批准的首例人工智能辅助诊断工具,用于帮助医生分析心脏核磁共振图像,可自动化描绘图像中的心室轮廓线,并计算心室功能相关参数;随后其Lung AI和Liver AI也陆续获得FDA的批准,用于辅助医生分析肺结节和肝脏损伤。今年2月份,公司的ContaCT也获得FDA批准用于分析大脑CT的扫描图像,用以发现与中风相关的信号(如可疑的大血管堵塞),及时通知医生。令人振奋的是,近日,FDA批准IDx公司的IDx-DR可独立用于初步筛查糖尿病视网膜病变,判断是否需要医生的进一步评估和诊断。
除了工业界的进展,学术界高水平杂志上人工智能影像相关的工作也屡见不鲜,2016年的JAMA和2018年的Cell都有人工智能在诊断眼科疾病如年龄相关性黄斑变性和糖尿病黄斑水肿的研究报道。简而言之,人工智能对疾病影像的识别有着较高的灵敏度和特异性,速度快和重现性也是人工智能的优势所在,医生群体都开始担心会不会被人工智能抢走工作。
人工智能在医学影像诊断方面的优异表现,其实一点也不意外,本来这一轮的人工智能浪潮的催化剂就是斯坦福大学教授、谷歌云首席科学家李飞飞的ImageNet。源于某些疾病的影像诊断有较为明晰的标识,以及足够的训练集,人工智能在影像数据集上能达到与医生不相上下的正确率。但现实环境会比文献或诸多人机PK大赛中严格控制的条件要复杂,虽然人工智能通过引入Dropout和DropConnect等算法来减少过度拟合,但数据多样性不足仍会导致人工智能存在偏向性,泛化能力不足,对罕见疾病更是束手无策。其次,当前的人工智能只能从事指定类型的智能行为,有诸多的适用条件和范围,譬如IDx-DR除了仍然需要专业人员操作眼底照像机获得高质量图像,而且需要在使用之前排除多种不适用状况,如持续性视力丧失、视力模糊、增殖性视网膜病和视网膜静脉阻塞等症状。再次,遇到某些模棱两可的疾病影像,就常常需要医生在读片时问诊病人及结合病人之前的病历报告来综合判断,这类需要根据医学常识进行逻辑推理判断的任务对人工智能而言似乎并不容易。在威诺格拉德模式挑战(一种代词消歧的自然语言问题,用于区分人工智能是基于常识来理解对话还是基于统计数据的猜测)中,人工智能溃不成军。最后,所有的人工智能工作只有遵循临床指南,才可能被医生群体所认可,譬如最像医生的IDx-DR擅长视网膜成像的图像解读,在2017年美国糖尿病协会对筛查糖尿病视网膜病变的立场声明中,视网膜成像属于证据分级系统的E级证据,而且FDA也明确表示病人在40和60岁以及有任何视觉问题时,仍然需要全套的眼科检查,更何况人工智能通过多层神经网络的黑匣子给出的结果并不令人放心。同时医学在不断进步,临床指南也会修改,有可能导致之前训练集的标识需要重新来过。数据标识工作可谓是劳动密集型工种,诸多类似富士康的雇佣大量人员,只是这些数据标识工厂并没有出现在光鲜的新闻上。医药类数据标识由于其专业性强,对标识人员的水平要求更高。人工智能医学影像肯定是未来的方向,有望广泛进入各大医院作为医生的助手在多种疾病的诊断上提供真正有实用价值的参考性意见。只是目前的人工智能离媒体宣扬的“替代医生”还有很长的路途。
其实如果着力于人眼不可及的领域,也许是另一条可行之路,譬如把疾病诊断简化到分子水平。如果人工智能选择弥补人类缺乏的能力,而不是去和人类竞争,那被接受的概率和速度要大得多、快得多。我们知道,肿瘤的异质性很强,即使是看起来很相似的肿瘤形态,也可能有着不同的基因变异,此时病理学常无能为力。而且肿瘤的异质性也是导致新药研发缺乏针对性而失败的重要原因。近期,Nature杂志发表了一篇文章,一百多位科学家联合开发了一套基于中枢神经系统肿瘤DNA甲基化来进行疾病诊断和分类的人工智能,它与标准的诊断方法有可比性,而且更重要的是,因为完全基于不同的角度,这套人工智能还可以发现目前医学指南中未分类的肿瘤类型,为肿瘤的精准治疗和新药开发提供重要信息。
3人工智能能否颠覆新药研发?
与医学影像诊断相比,新药研发最大的特点在于大家时刻处于没有头绪的状态。如果有药物研发相关的新技术出现,不差钱的大药厂肯定非常乐意一试。不过这些新技术能否为新药研发的成功率带来革命性的提升?总体来看,很遗憾,基本上是没有;局部来看,某些技术在药物研发的某些阶段的确能够起到重要提速的作用,譬如已进入新药研发多年的高通量筛选和计算机辅助药物分子设计等曾经期待的“颠覆性”技术。究其原因,新药研发最大的坑是生物。整个药物研发进程,就是在验证某个靶点在人体中的生物学功能的过程。真正需要填充的大坑其实是优质靶点的缺乏,动物模型临床转化差和疾病异质性等。生物系统内在的复杂性,注定这是一个很难解决的问题。所以诸多媒体口中的人工智能无所不能,“提高新药研发成功率,引发制药革命”的赞誉之词得时刻警惕,泡沫破灭时,飞得越高,跌得也越重。
首先,人工智能能否预测一个化合物能成为药物?这个答案很可能是否定的,因为深度学习依赖于高质量、有标识的大数据集。目前只有大概1600个被FDA批准的新药(Nat Rev Drug Discov. 2017;16(1):19-34),远远谈不上大数据。而类似针对假肥大性肌营养不良(DMD)的药物Eteplirsen等,能否标注其为成功的新药,也需要打个问号。同时,不计其数倒在路上的化合物,也不能说就没有可能成为新药,如果能够寻找到合适人群和适应症,沧海遗珠也能镶上皇冠。这样看来,我们自己都没有闹明白什么样的化合物算是药物,加分罚分我们都无法给出明确的定义。与棋类游戏或者影像诊断相比,新药研发规则不明确,数据不明晰甚至含有错误信息,而且充满了高度不确定性,这给以高质量标识数据集为基础的深度学习人工智能带来巨大的挑战。
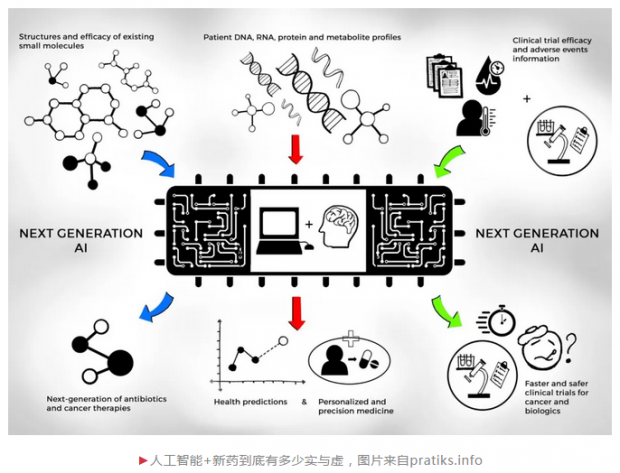
其次,人工智能在新药研发的各个阶段表现如何?新药研发是一个系统工程,从靶点的发现与验证,到先导化合物的发现与优化,再到候选化合物的挑选及开发,最后进入到临床研究,可谓是九死一生。目前,人工智能在新药研发的各个领域也的确是热闹非凡,诸多大型制药公司开始与人工智能初创公司开展合作:阿斯利康与Berg,强生与Benevolent AI,基因泰克与GNS Healthcare,默沙东与Atomwise,武田制药与Numerate,赛诺菲和葛兰素史克与Exscientia,辉瑞与IBM Watson等,各自合作的侧重点也有所不同,但主要集中于靶点的发现与验证包括生物标志物的发现(如何理解疾病)和先导化合物的发现与优化(如何设计药物)这两个领域。
4人工智能在新机制和新靶点发现上的应用
目前,常见的即利用人工智能分析海量的文献、专利和临床结果,找出潜在的、被忽视的通路、蛋白和机制等与疾病的相关性,从而提出新的可供测试的假说,以期望发现新机制和新靶点。药物靶点对于整个新药研发项目的重要性不言而喻,譬如胆固醇酯转运蛋白(CETP)让多少大佬折戟沉沙、马革裹尸,最后的“武士”——默沙东仍然惨淡谢幕;而PD-1又让多少人欣喜若狂、趋之若鹜,带动着整个生物大分子领域的快速飞升。
当前的新药研发缺乏优质靶点,已经是众人皆知的事实,一旦出现一个获得临床验证的新靶点,叠罗汉式的前仆后继并不鲜见,而在该靶点位于前列的公司估值也是高不可攀。在制药界这般尴尬的境遇下,志在寻找新靶点新机制的人工智能的出现,自然成了茫茫大海中的救生浮木,获得追捧,催生了诸多的生物技术公司。Berg基于人工智能的Interrogative Biology平台技术通过分析海量病人和正常人样本(如蛋白相互作用网络)来寻找治疗疾病的新靶点和诊断疾病的生物标志物;GNS Healthcare 基于人工智能的REFS技术分析海量的生物医学和医疗保险数据,为患者推荐最合适的治疗手段和药物;IBM Watson新药发现系统通过分析海量文献寻找潜在的关联性来产生新的假说推动新药研发;还有年初刚获得国内领投的美国公司Engine Biosciences,也是利用其人工智能技术来进行老药新用、新靶点开发以及精准医疗等。
但人工智能会比目前优秀的生物学家做得更好吗?先关注一下人工智能近年来的战绩。2015年估值就已达到17.81亿美元的Benevolent AI公司,通过分析海量的科技文献、专利和临床实验结果等挖掘潜在的知识产生新的假说,在肌萎缩侧索硬化(ALS) 疾病治疗上,发现的化合物在动物模型上显示效果,准备进入临床研究;另外它还把强生之前开发用于注意缺陷多动障碍(ADHD)失败的Bavisant重新开发用于帕金森氏症病人的日间极度嗜睡症(EDS)的Phase 2b的验证性试验。近期获得软银领投的twoXAR,用人工智能技术平台进行老药新用,发现了艾塞那肽(Exenatide)和奥洛他定(Olopatadine)在类风湿性关节炎(RA)的动物模型上有较好的效果;明码生物的人工智能团队与耶鲁大学合作,发现了纤维细胞生长因子(FGF)通过糖酵解参与到血管发育的过程。不过仔细想想,拿得出手的进展大多是临床前的数据,研究结果未发表或者发表在非同行评议的网站,而根据老药新用的预测结果申请做一个Phase 2b的概念性验证试验并不是什么稀罕的事儿。通过实验筛选,甚至临床偶然观察发现的老药新用的事例数不胜数。至于FGF与血管发育的那篇文章,并没有提到多少人工智能的内容,更像是传统的转录组学(RNA-seq)分析加GO富集分析(当然也可能是限于文章篇幅而没有披露人工智能的细节)。但生物系统本身就很复杂,人工智能之前的传统方法也同样磕磕碰碰,毫无疑问人工智能可以帮助生物学家产生新的假说,但是否会是更好的假说仍面临极大的挑战。
首先,近期的Nature Reviews Drug Discovery统计了FDA批准的1578个药物总共的靶点数目是667个,而Ensembl标注的潜在药物靶点就有4479个,当然还有些其他的关于靶点数目的预估,数值有差异,但都远大于目前已经成药的靶点,更何况每期的CNS文章里常有些看起来很有前景的新靶点,这些潜在的新靶点都是有或多或少obvious-data支持,而不仅仅是人工智能费力找出来的hidden-data。我们究竟能有多大信心去花费足够资源验证这些由Natural Intelligence寻找的有obvious-data支持的新靶点?我们又能有多大信心去花费足够资源验证那些由人工智能寻找的有hidden-data支持的新靶点?
其次,大数据训练出来的人工智能的好处在于有问必有答,坏处也在于有问必有答。通过学习海量的文献数据,人工智能肯定能找出非常多的相关性, 无论强弱,但是信噪比如何?生物系统复杂异常,有着无数的独立变量,深度学习的神经网络层数是否足够处理?更重要的是,海量的文献必然质量参差不齐,存在着相当多的错误信息和结论、不可重复的实验数据和结论、部分公开的实验数据和结论,似是而非的实验数据和结论,有意无意误导性的实验数据和结论,盲目追热点导致给相关性加分的实验数据和结论,笔者相信上述的这些情况,行业中人必然是深有体会。
基于这样的数据集,人工智能该如何学习呢?一个优秀的研究人员也需要多年的培训才有可能学会区分文献中的可靠或不可靠信息,这其中隐含了大量的逻辑推理和常识,甚至偶尔还涉及到对文章作者学术名誉的估量,这些并不是人工智能所擅长的领域。更进一步,我们都知道,相关性,即使是强相关性,也不是因果性。譬如全基因组关联分析(GWAS)常告诉我们某些基因与某些疾病相关性很强,可这些基因离成为药物靶点还离着十万八千里,需要科学家一步步的去探索和验证该基因与疾病的关系,弄明白具体的机制机理才有可能进入新药研发人员的眼眸,这一晃也许十多年就过去了。一个新药研发项目的启动意味着大量资金和人力的投入,因此能真正进入到新药研发管线中的药物靶标都是精挑细选和严苛验证的。所谓AI弱水三千,NI只取一瓢。
不过虽然生物体系异常复杂,但如果还原到更简单的水平,譬如细胞水平,结合人工智能强大的图像学习能力,有望取得突破。来自Janssen等公司和学校的研究人员,利用传统的高通量筛选针对糖皮质激素受体的细胞模型,筛选了50万个化合物,获得化合物的细胞表型图像数据,生成基于图像的分子指纹, 同时结合这些化合物之前在500多种不同靶点的筛选模型中测定的生物学活性作为训练集,采用深度学习的方法训练出一个人工智能模型,然后可以根据化合物在糖皮质激素受体的细胞表型图像数据,来预测化合物对其他不相关靶点的生物学活性数据。这意味着单个高通量细胞表型图像筛选模型可以取代许多耗时耗力构建的特定靶点和通路的筛选模型, 显著降低人力和时间成本。于此同时Cell Image Library提供了上万的化合物处理细胞后不同的图像和形态学数据以供人工智能学习,以寻找新的药物作用新机制。笔者推测这方面的研究是否会催生一门新兴学科-图像基因组学(Imagenome),结合其他组学研究的数据,综合用来研究细胞水平的表型变化的分子机制。
总体而言,基于大数据的人工智能,擅长的是对已有知识的挖掘、重新组织和分配,所以人工智能可以学习已有的影像诊断规则,甚至能够看得更细更快,也可以在海量的数据中寻找已有知识的关联性。但每一次新药研发的成功,都是人类突破已有的知识框架,对疾病认知的新突破。新知识的产生,来源于人类的无数次试错和实践,而不是一条条画在已有知识间的连线。能否更好的理解疾病,相信看到这里的读者,已经有了自己的判断。那能否成规模的产生药物候选物?究竟是“Garbage quick in, Garbage quick out”,还是另有洞天?不畏浮云遮望眼,下一篇,将会与大家聊一聊“人工智能能否设计药物”。
作者简介:
李伟,北京生命科学研究所博士毕业,计算化学和分子设计专业。曾在康龙化成(北京)新药技术有限公司担任高级研究组长,现任职瑞璞鑫(苏州)生物科技有限公司药物化学主管。
黄牛,北京生命科学研究所高级研究员。基于物理学原理的计算化学理论和分子模拟技术,研究在分子识别过程(蛋白-蛋白,蛋白-核酸和蛋白-配体相互作用)中的自由能和空间构象的变化,从而指导蛋白质结构和功能的改造,以及加速新药的设计与开发。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}