
中国百万人群大队列何去何从?| 图源:
知识分子编者按:
大队列研究,做好了对人类医学非常有益。世界上有几个突出的例子。但是外国的榜样有时在中国走样,甚至变成要大钱,但不做大事,或者不把大事做好。经费大增后的中国科学界,是否对得起科学、是否对得起中国纳税人,如何做包括队列在内的大项目,可能是试金石之一,检验能力、作风、良心。
撰文 | 邸利会
责编 | 王一苇
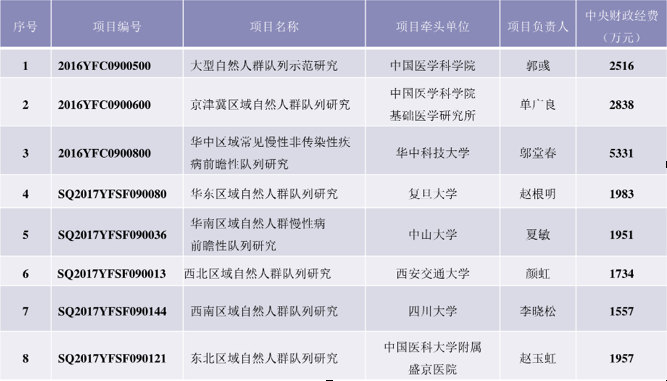
图1 科技部重点研发计划“精准医学研究”重点专项获批的大规模人群队列部分项目
14亿人口、56个民族,没有人怀疑,中国拥有丰富的人类遗传资源。然而,如同矿藏之于黄金,如果开采不善,资源的价值就无法得到好的发挥。
六年之前,当中国在《“十三五” 国家科技创新规划》中提出,“建立百万健康人群和重点疾病病人的前瞻队列”(后文简称百万人群队列)时,也许你会期待,有朝一日其产生的数据会开放给全球的研究者,就像 “英国生物银行”(UK Biobank) 或者美国的 “我们所有人”(All of Us) 研究计划那样。
然而,在今天这些大型队列结题的时候,《知识分子》了解到,实际结果和理想中的效果可能相去甚远——
采到的样本分散储藏在某处,极少测序,收集的基本数据去向不一,意味着课题组外的研究者或企业,如果想利用这些资源的话,会相当困难。
队列研究(Cohort studies)是一种研究设计,随着时间的推移跟踪人群,收集数据了解影响健康的遗传、环境、社会等因素。
除了科技部 “精准医学研究” 重点专项获批的百万人群队列外,此刻中国大地上开展的规模不一的队列研究还有很多,但影响也较为局限。
相对于英美发达国家,中国的病人数量、数据总量不低,但影响力却一般,少有文章基于中国的数据做出重要的发现,也少有药厂来花钱购买中国的数据。
“这些百万人群队列的建立,对我国的生物医药研究来说是开创新的,为标准化收集和使用宝贵的临床资源奠定了很好的基础。” 西湖大学生命科学学院特聘研究员郭天南说,“经过这一些努力,现在有必要做些小结:基于这几年的努力,我们取得了什么成绩?碰到了什么困难?下一步应该如何去做?”
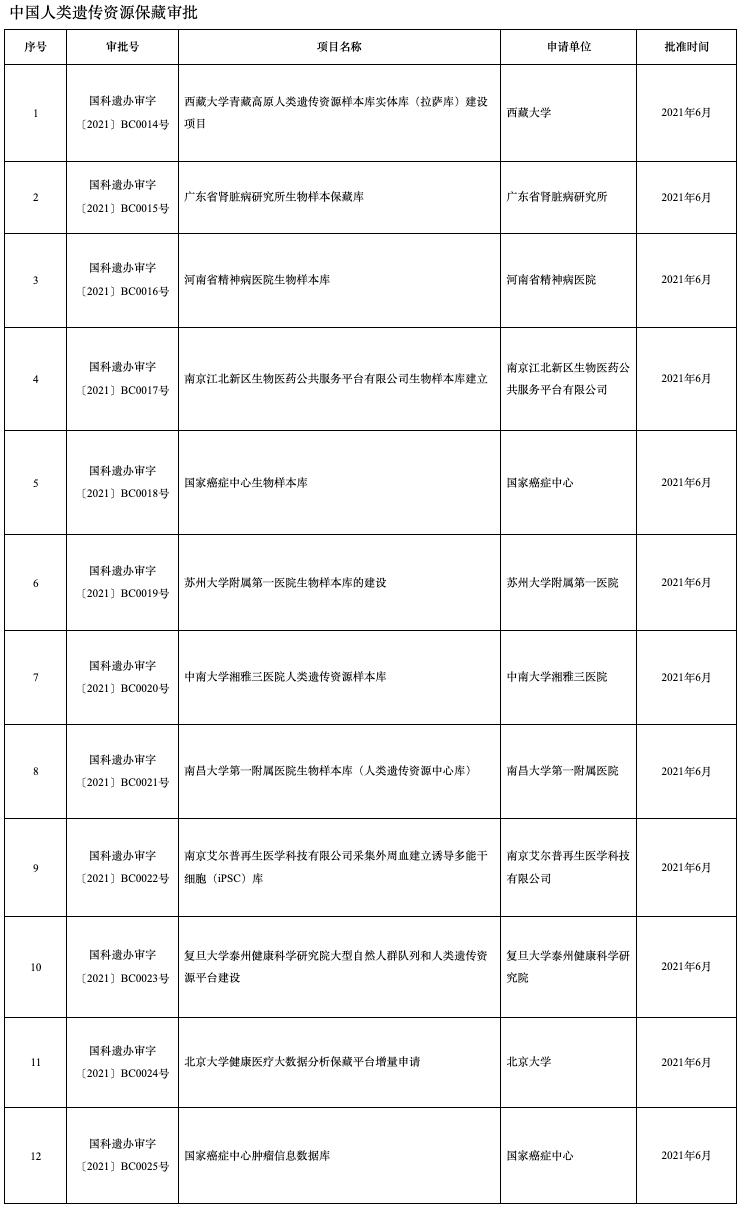
图2 2021年5月11日-2021年5月25日科技部受理行政许可申请事项中,12个项目获得保藏行政许可。数据来源:
交了就算是共享了?
在数据共享方面,“精准医学专项” 的队列研究还是有进步。
2016、2017年的申报指南提出,“队列所建立的样本和数据必须按照本专项的要求进行共享,数据必须及时提交本专项建立的精准医学大数据平台统一管理”。
之后的2019年6月,科技部、财政部发布了20个国家科学数据中心,根据2018年3月国务院办公厅颁布的《科学数据管理办法》,重大专项产生的数据需要汇交到这里。
参加过多个队列结题评审、不愿意具名的专家A告诉《知识分子》,在项目申请之初,课题组就必须承诺数据的汇交,“这点是做到了”,但究竟交在这20个里面的哪一个,并没有特别规定,“完全取决于项目负责人自己的方便”。
“所以理论上(精准医学专项的数据)交到比如地震数据中心或者气象数据中心都是可以的,” 不愿意具名的数据专家B说,“尽管这听起来有些不可思议。”
百万人群队列的立项在科技部,管理实施是卫健委,课题单位大多为医院和疾控中心,数据大概率会交到“国家人口健康科学数据中心”(卫健委主管)或 “国家基因组科学数据中心”(中科院主管)。
“设计了东西南北中几个区域的队列,如果数据最后都不在一个地方,使用起来就非常不方便,而且日后的共享也是问题。” A说。
“应该从数据类型的角度来界定可递交的数据中心,蛋白质、基因组、表型等生物数据跟其它学科的其实是很不一样的,规定清楚了(交到哪)也能避免重复建设,比如如果有人把基因组的数据递交到国家地震科学数据中心,为了能有效地使用这些数据,该中心就得重复建一套专门的基因组数据汇交、审编、检索系统,从国家角度,这是一种资源浪费。” B说。
此外,队列研究通常涉及两方面的数据,一方面是基因组、蛋白组、生物标记物等遗传信息数据;另一方面是临床的、表型的宏观信息,两者结合、关联起来才能产生有意义的结果,推动科学研究和产业发展,例如新药研发。
遗憾的是,百万人群队列大多只收集了宏观的表型数据,在采集了血液、尿液等样本后,进行了基因测序的几乎没有,而缺乏了遗传数据的队列,实际用途有限。
“测序、组学这些事情,大家都知道(其重要性),可是没钱,那东西就没办法做,我觉得主要还是没有经费。” A说。
据A介绍,整个 “精准医学专项” 的自然人群队列以及专病队列,分下来每个子课题不过几百万元,而这些队列少则5万人,多则20万人。
“我当时给他们算过,基本上每个参加者就两三百块钱,少得就一两百,你想他能干什么?连做基线数据都不够。” A说。
最终的情况是,在收集完生物样本,交了表型数据后就算结题了,至于数据可否在更大范围分享,并没有规划。这些花了巨大成本获得的生物样本和表型数据往往被遗忘在角落;而高质量生物样本的处理以及高昂的存储成本,是项目组的巨大负担,多数情况下并未实现。
“提交了就算是共享了,并没有留出一个真正的渠道,比如让该课题组之外的全国任何一个科研人员都可以上去看,并没有。现在大家都是3月份之前,至少先结完题再说,未来怎么使用(这些数据),没有统一规划。至于‘十四五’的布局,没看到,我不认为现在有,现在还没有到那步,我也每次都提,这完了以后你掉那块了就很可惜,但是队列,大家都知道,得有一个可持续性发展。” A说。
《知识分子》也从另外一位评审专家了解到,“后续如何支持,还在努力中”。
难以为继?
与一般的科研项目不同,大型队列的研究(比如一些慢性病)往往要持续几十年,每隔几年进行一次随访,只有这样才能厘清环境因素、生活习惯的长期影响。一方面,时间越长的队列越有价值,可随之而来的挑战是,需要有持续的经费投入。
从 “精准医学专项” 的大型队列看,其中一些队列研究早就启动并已进行了很多年,专项的设立再次将它们打包进去,不过是另外一笔资助。
比如,由中国医学科学院牵头的 “大型自然人群队列示范研究” 是基于迄今最大的中国汉族人研究队列,中国慢性病前瞻性研究项目(China Kadoorie Biobank,CKB)。该项目涉及中国5个城市和5个乡镇,共51万余人,基于血液的基础健康数据库,从遗传、环境和生活方式等多个环节研究危害中国人群健康的各类重大慢性病(如脑卒中、冠心病、癌症、糖尿病、高血压等)的致病因素、发病机理及流行规律和趋势。
CKB是中国医学科学院与英国牛津大学联合开展的国际合作项目,2002年得到了香港Kadoorie基金会的资助,已经有20年的历史。受中国人类遗传资源管控方面的影响,《知识分子》获悉,该项目三年前的一笔约1000万美元的企业投资处在暂缓拨付的状态。
作为专项 “示范” 的CKB应该会继续下去,其它的项目,尤其是新设立的队列如何呢?
“多数(课题)也就够人家注个册,有的连基线数据都没有;很多做了基线数据的,那是因为这些队列进来的时候都已经有了,都有基础,课题负责人后续可以再继续申请别的资助,比如基金委的,让队列继续滚动下去,但就专项而言,没有提供继续滚动的资助。” A说。
如果只靠财政拨付的科研基金,队列发展可能会有局限。
“纯靠国家经费或医院投入,是很难持续的。理想情况下,如同欧美成熟的队列管理一样,应该有商业资本和非营利组织基金会的资源投入,以及职业经理人的参与。这不仅是科研,也是巨大的商机。医学研究要真正影响患者,商业转化必不可少,这一个渠道还没有完全打开。” 郭天南说。
而如果没有持续的资金投入,不仅后续的随访没办法做,也无法进一步挖掘基因组、蛋白组等组学数据,无法建设高水准的计算平台,无法维持专业的团队。简言之,项目结束之日,恐怕就是队列结束之时。
“我国此前已经投入许多经费构建人群大队列。实际落地情况是,若干实验室非常辛苦地长期采集队列数据,但是很难维持团队,很难纵深形成标准,最后实际的效果是在初级层次上不断重复劳动。体现出来的情况,我国投入已经不少,但是至今没有任何可以跟 UN Biobank 抗衡的大数据中心,形成不了优势竞争力。” 北京脑科学与类脑研究中心下属基因组学中心和计算中心主任张力说。
他山之石
张力提到的 UK Biobank,在不少业内专家看来,是人类遗传资源利用和共享方面的典范——其全球注册用户已有28000名,发表了近25000篇论文,使用者八成来自其它国家,包括中国的大量研究者。
UK Biobank也已经有20年的历史。2002年4月29日,英国医学研究委员会(Medical Research Council)和惠康基金会(Wellcome Trust)出资4500万英镑启动了该项目。从2006年到2010年,项目组招募了年龄在40~69岁之间超过50万的志愿者,获得了家族病史、生活习惯、认知功能、职业状况、生活环境等社会经济和流行病学信息,测量了身高、体重、血压、握力以及骨密度等基本健康信息。当然,也采集了血液,尿液和唾液等生物样本。
此后,UK Biobank 对样本进行了基因测序,还获得了三十种生物标志物的数据。在后续的随访中,UK Biobank 还进行了包括认知功能、饮食习惯、职业健康、心理健康、消化健康、食物偏好在内的问卷,相继获得了医学影像、运动与行为等数据,同时依托国民医疗服务体系(National Health Service,NHS)获得了参与者的患病、用药以及死亡信息。
在样本库方面,2009年7月,UK Biobank 正式启用了一个耗资450万英镑的专用高科技存储设施,可以在-80°C下保存1000万样品。如今,其自动化机器人有能力在一天内提取到4000个样本。
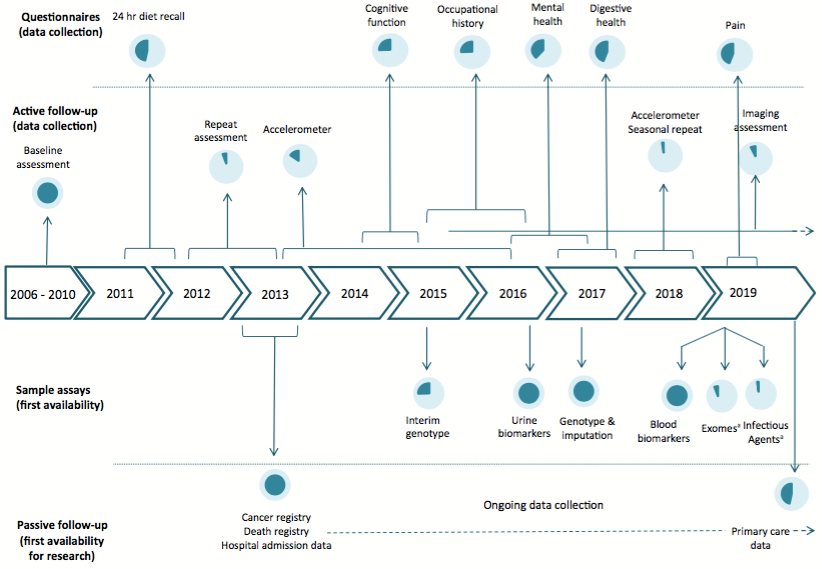
图3 截止到2019年中UK Biobank的数据收集过程 | 图源:
在数据处理方面,2017年5月,牛津大学李嘉诚健康信息与发现中心在牛津大学Old Road 校区正式开业,该中心除了有牛津大学纳菲尔德人口健康系(The Nuffield Department of Population Health,NDPH)的工作人员外,也是UK Biobank大数据研究所和数据分析、IT、记录链接、流行病学和沟通团队的所在地。UK Biobank 的数据量预计在2025年达到40PB(1PB = 1000 TB = 1000,000 GB)。
通过20年的滚动发展,UK Biobank 还在不断取得新的进展——
今年1月,UK Biobank完成了5万人器官成像(未来将完成10万人),结合基因和生活方式数据,将帮助痴呆、心脏病、关节炎和癌症等疾病的诊断、治疗或者预防。
去年12月,首批20万的全基因测序(Whole Genome Sequencing,WGS)数据开放给了全球的研究者。通过结合已经测得的50万全外显子测序数据,生活方式、生化、图像、健康数据,这些数据有助于增进对疾病的认识,发现新药物靶点、促进药物的研发。
值得注意的是,50万的全基因测序由安进(Amgen)、阿斯利康、葛兰素史克(GSK)、强生,以及惠康和英国研究与创新(UK Research and Innovation ,UKRI)公、私合作伙伴共同提供资金。之前的50万全外显子测序数据的产生,也有众多公司的参与。
这些基因组数据已经通过去年9月研发的云平台(Research Analysis Platform)发布,全球的研究者,无论在哪,都可以安全快速地在线登录和分析整个 UK Biobank 的数据库,无需将数据下载到本地就可以处理。
云平台的发布不仅解决了大量数据下载的麻烦,节约了用户的时间、存储和算力,而且让远程项目协作成为了可能,如此大体量的计算应用也反过来大大促进了云平台产业的软硬件发展。
“现在全基因组测序数据太大,动辄20~30个PB,一个国家大概没几个单位能存储这样级别的数据,所以这就是为什么UKBiobank要花几千万美金,依托亚马逊做远程分析的云平台,直接大家都线上操作,不用像传统的方式那样申请打包下载到本地。” 牛津大学临床试验和流行病学部门主任陈铮鸣说。他同时是CKB项目的中方负责人。
UK Biobank 为何如此成功?
如果说存在所谓的 “英国模式” 的话,张力认为,英国国家卫生服务体系是其中的核心环节。NHS是由政府税收统一支付的卫生服务体系,为全民提供免费的卫生服务。
“英国的模式,实际上跟NHS结合起来以后,相当于临床信息一直就在那了,剩下来的只要抽来血液一测,马上就有了基因组的这些遗传信息,等于他有一个专业的队伍长期在干这个事儿,是有积累的,最开始肯定都没那么成熟,但有这么一个机制以后就可以逐步地提高。” 张力说。
目前,英国政府正在加大投资NHS,给予NHS更大的灵活性,使其可以更有效率地连接国民、医疗机构、企业和国外政府,为英国社会提供先进的健康服务,并向全球输出英国的标准。
此外,除了政府的推动,英国在把健康数据变成产业的过程中,一系列的基金会、专业的公司也参与了进来,提供资金来支持数据的产生。
“比如说这库里面有了10万人的基因组、转录组,有一些组织投入资源测了蛋白组,之后又有另外的人投入资金测了不同时间药物的反应等等,然后花钱去看参与者几年、十年、几十年疾病的进展,健康状态的改变。这些数据的产生就像,刚开始只是一个冰晶,变成小雪球,变成大雪球,雪球越滚越大,价值也越来越高。” 郭天南说。
越来越多的病人资料、组学数据,吸引的不仅是研究人员,很多企业也充分意识到 UK Biobank 拥有的资源对加速药物研发、早期诊断等方面的价值。
截止到2019年,UK Biobank 的企业注册用户达到了12%。当然,企业用户的加入也提供了更多资金方面的支持。
全球的研究者在享受开放共享的同时,也在为 UK Biobank 的发展贡献智慧。
“这实际上相当于全世界的聪明人都去帮他,应该收集哪些样本,哪些信息更重要,怎么去做数据整合,算法具体怎么去弄,在临床上,比如说对新药的研发,药物如何落地是一个最有效率的途径等等提供意见。” 张力说。
“UK Biobank 负责人前一段时间跟我讲,因为中国科学家用户非常多,他们现在邀请中国的科学家参与这个项目的高级顾问团,对未来的科学,对这个平台的发展方向提供建议。所以,UK Biobank 是非常包容、国际化的,它的资助、使用也是国际化的。” 陈铮鸣说。
路漫漫
中国在近些年也意识到了数据的重要性。在政策层面,2018年出台的《科学数据管理办法》(以下简称 “办法”)提出,大力推进科学数据资源的开放共享;2019年还发布了20个国家科学数据中心。
就人类遗传资源利用而言,2019年5月印发的《中华人民共和国人类遗传资源管理条例》,在划定 “五条红线” 的同时,也特别强调,要加强我国人类遗传资源包括保藏等基础平台建设,并要求促进数据的共享和利用。
不过,要建成向像UK Biobank 那样的体系,业内专家向《知识分子》表示,需要战略的定力,顶层的设计,创设良好的开放共享机制,破除医疗界和学术界的藩篱,吸引工业界、慈善机构等,最终实现可持续发展。
“CKB其实和 UK Biobank 是姊妹项目,课题的头十年,我们就准备好了什么结果都不出,就是这么一个战略定位。因为前瞻性的队列研究需要花5~6年创建,期间你不可能做特别大的事情,主要的精力放在保质保量的收集基线数据,建立良好的发病死亡的随访,人员的培训,样本库,数据库的建立等等。直到2015年我们才开始真正出一些比较重量级的研究成果。急功近利就像是沙滩上盖大厦,最后也扛不住。” 陈铮鸣说。
从 “精准医学” 专项里的队列课题看,很多实施的年限在四年,如果是全新的队列,如此短时间内出成果或者实现转化的可能性不大,但不妨碍有些团队已经发表了一些论文。
陈铮明还表示,做好顶层设计也很关键——
“一定要有一个好的顶层设计,国内的很多项目可能不是集中管理,层层分包,都过来领点任务,最后质量、标准化方面就不好保障。”
在美国有过科研经历的张力介绍说,只要是NIH资助的项目,都会指定送到纽约的一个测序中心去统一产生数据,如此才能保障数据的标准性、质量等,同时标准建立后也会经历不断的迭代,因此必须要有一支专业化的队伍,一个中心去统一这些标准。
张力还谈到,在美国做科研如果想拿样本、数据相对容易,流程上较为顺畅,但在国内却很困难。
“这里面有各种各样的原因,很多单位尤其是医院,对这些临床的信息把控比较严,共享比较困难,其实是我们面临的一个比较大的问题。” 中国科学院北京基因组研究所研究员鲍一明说。
多位研究人员向《知识分子》表示,现实中,临床和科研两张皮,医生群体和科研群体之间还缺乏有效的合作机制。
拿大型队列课题来说,主要牵头单位大多是医院,其中的道理也许很简单——人类遗传样本,尤其是涉及到一些专病的,产出的地方主要就在医院,可医院拿到这些样本和临床数据后,却很少共享。
随着越来越多队列研究的开展,生物样本库正在涌现。《知识分子》查到的信息显示,仅2021年全年和2022年迄今,获得保藏行政许可的单位有90家。
但它们的利用情况并不乐观。
“不少样本库,基本上都是人工管理的,没有实现自动化的,样本存在那,基本上没人用;反过来,搞基础科研的人因为做具体的研究,非常清楚自己想要怎么去处理这些样本,但他拿不到。” 张力说。
问题是,样本和临床的数据如果要产生价值,推动新药的研发,必须要流动利用起来。
一个比较现实的、可实施的途径,张力认为,可以先把信息打通,弄清楚全国范围内有哪些样本、大概的状况,在此基础之上国家有一个统筹,慢慢地把上游的医院和下游的基础研究对接起来,逐步实现样本的流转、处理的标准化。
“如果直接提数据共享,研究者会考虑竞争等很多因素,再加上国家顶层设计上没有特别清晰的规定,这事儿就不好办。可以先不谈共享,先把信息系统打通,这样至少大家知道在哪有什么样的数据,至少可以避免重复劳动,之后可以有的放矢地去谈合作,在这个过程当中把共享机制给建立起来。” 他说。
目前来看,对于 “精准医学” 专项里的大型队列,还没有见到一个统一的数据存储和共享平台。
而就共享而言,随着数据量的增长,目前传统的数据共享方式(如寄送硬盘或者下载到本地),都会变得不可持续,云存储和云计算将不可避免。
“一个人的全基因组数据也得100G,上万人的话,这个数据就很大了,任何一家单位要能承受同时好多人下载数据,光是去买商业网络带宽,都是天价,根本不可能的事儿。” 张力说。
看来要达到 UK Biobank 那样的水准,中国大型队列还有很长的路要走。
“这条路并非没有路标,而是已有发达国家的先行者探索出的一条光明大道正在前方。我们现在已经有一定基础,需要做的是携手相关利益方,解放思想,踏出一条中国具有中国特色的路。一旦我们大量尘封的生物样本资源能得到利用,必将对我国以及世界的生物医药、人民健康带来翻天覆地的升级。” 郭天南说。
《知识分子》资深主笔
尚存进取之心

邸利会
参考文献:
1. 国务院关于印发“十三五”国家科技创新规划的通知, Conroy M, Sellors J, Effingham M, et al. The advantages of UK Biobank's open-access strategy for health research. J Intern Med. 2019;286(4):389-397. doi:10.1111/joim.129554. 科技部 财政部关于发布国家科技资源共享服务平台优化调整名单的通知,

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}