阅读:0
听报道

撰文|胡传鹏 吕小康
责编|赵亚杰
● ● ●
在科学实验中,研究者们往往需要判断某个结果在不同的实验条件下是否有差异,并检验这种差异是不是由于偶然因素造成的。
最伟大的统计学家之一、英国人Ronald Fisher(1890~1962)在上世纪20年代提出了一个假想的思路来确定实验效果是否只靠运气出现:首先假定实验结果在不同实验条件下没有差异,即所得结果是全然随机出现的;然后计算在完全随机的假设下出现当前数据结果或更极端的结果模式出现的概率,这就是当代统计学中所谓的P值。假如出现当前结果模式(及更极端模式)的概率很小,则可以认为,这么小的概率在一次试验中不太可能会出现。从而反推:我们所假设的前提(不同实验条件没有差异)可能是错误的,即不同实验条件应能产生不同的实验效果。这种思想被Fisher命名为显著性检验(test of significance),“显著”在他的原意中,并不表示其他意思,只是表明这一结果不是随机的。在这一推理模式中,最重要的统计指标就是P值。
更年轻的波兰裔统计学家Neyman和英国统计学家Pearson(此Pearson系提出线性相关系数、卡方检验的老Pearson之子),在Fisher的思想框架的基础之上,提出了更具通用性、数学气息也更强的假设检验模式。有意思的是,Fisher本人对Neyman-Pearson的“改进”并无好感,甚至宣称“我和我全世界的学生从未想过要使用他们的方法”,但在后来者的眼中,两者之间在技术与思想上的分歧逐渐淡化,他们的意见被整合成为了大部分研究者所熟悉的一种既不是纯Fisher式、也不是纯Neyman-Pearson式的统计推断方法——零假设显著性检验(Null hypothesis significant test, NHST,也翻译为虚无假设显著性检验)。在NHST模式下,建立原假设和备择假设,选择检验统计量并计算其值,根据P值是否小于显著性水平做出是否拒绝原假设的统计判断,最后再将这种统计判断转化为现实情境下的行为判断(如实验处理、政策干预是否确实有效),成为假设检验的标准流程。NHST是目前科学界使用最广泛的统计方法, P值也因此成为使用最广泛的统计指标。
难以理解的P值
虽然P值被广泛使用,但真正理解 P值所代表的意义的人却很少。2002年,德国研究者对心理学的研究者和学生进行一项调查,给他们呈现了6个关于 P值的陈述。所有学生均无法正确理解P值的意义(Haller & Krauss, 2002);即便是教授方法学的教师,也有80%无法正确理解P值。说明研究者极容易对P值产生误解。他们的这一结果与更早前的一项调查基本上一致(Oakes, 1986)。
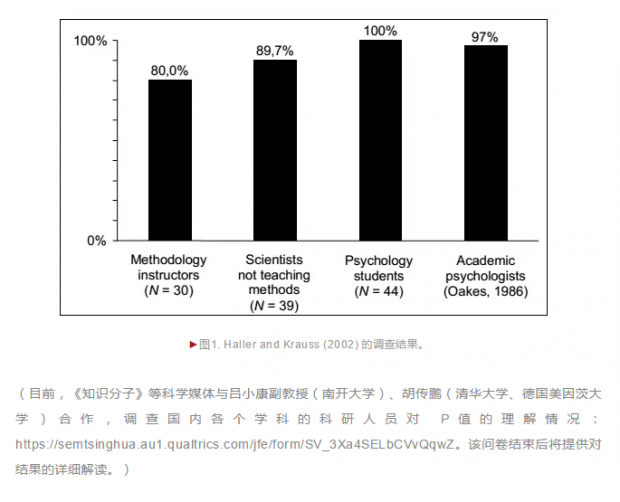
P值与科学界的可重复危机
由于P < 0.05在科研界被推上神坛,被研究者视“存在效应”及论文可能发表的指标,在当前“publish or perish(发表或是灭亡)”文化下,就有研究者想尽一切办法让 P值达到可发表的标准。这种做法导致了一个奇怪的现象:如果我们把已发表研究中的 P值分布画出来,会发现 P值分布在0.05附近出现了一个峰值,表明在已发表的研究中,P值在0.05附近是非常多(见图2、图3)。
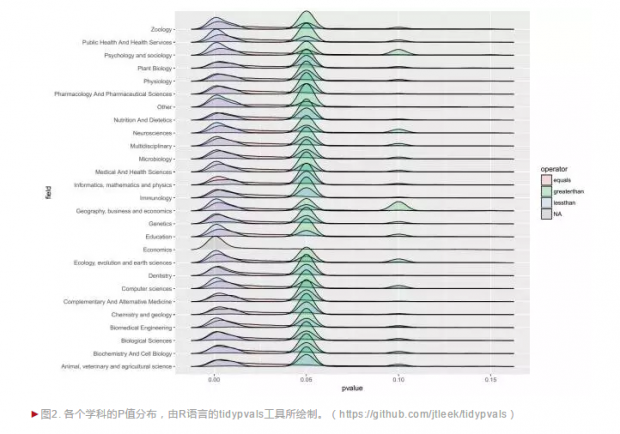
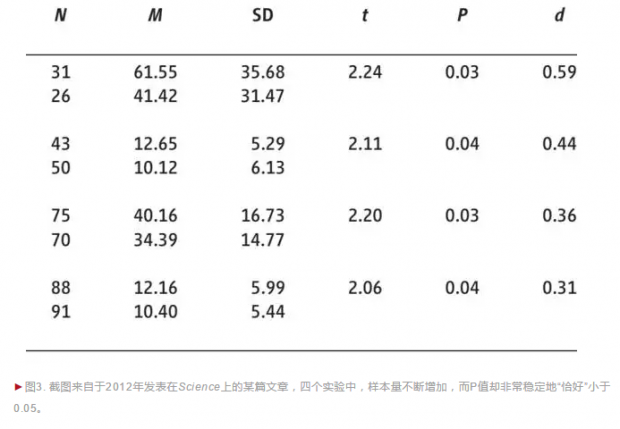
当然,对于这种P值 “恰好” 在0.05附近聚焦成峰的现象,也有多种可能的原因。比如可能是因为研究者在实验之前对实验设计进行优化(例如合理地选择样本量),从而让 P值恰好位于0.05附近;或者,是研究者使用了一些灰色手段,让 P值接近0.05从而达到可发表的标准。这些手段包括但不限于选择性报告变量、选择性删除数据、选择性增加样本量直至最关键的 P值小于0.05。
我们无法从发表的研究中判断研究者到底进行了何种操作导致大量研究的P值这样稳定在0.05附近,但是可以通过重复实验来验证这些结果是否可靠。2015年,Science上发表了200多个心理学研究者共同完成一项重复实验,在这个文章,他们报告了对100项研究结果的重复,发现大约39%的能够成功重复出来。
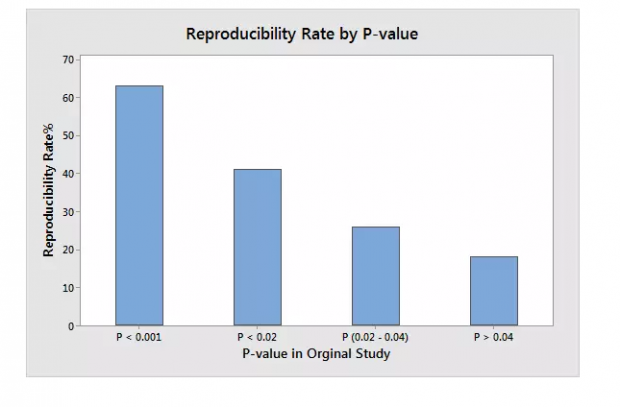
这个大规模的重复实验以及其他许多失败的重复研究,引起了研究者们的反思。研究者们发现,导致“可重复性危机”的原因很多,包括科研界的体制问题(如奖励发表论文,奖励吸引眼球的科研报道)、研究伦理问题(挑选数据,甚至数据造假)等各种原因。但是 P值 < 0.05对于产生不可重复的研究,“贡献”也很大:对2015年大规模重复实验的分析表明,P值与能够成功重复之间的关系也比较有趣:P值在0.04以上和0.05以下的研究中,被重复出来的最少。
P值在科研的“可重复性危机”中起到的推波助澜的作用,让许多统计学家非常担忧。虽然他们早已知道 P值不应该这样使用,但是却没有办法去改变众多学科中研究者们的实践。尽管如此,他们还是在2016年初专门发表声明,澄清关于 P值的真正意义以及应该如何使用P值的问题(Wasserstein & Lazar, 2016)。
但是这个声明引起小范围的关注后,P值仍继续着它一直被批判,却从未被取代的地位。“可重复性危机”出现后,虽然有一个杂志(Basic and Applied Social Psychology)要求彻底摒弃对 P值的使用(Trafimow & Marks, 2015),但绝大部分的研究仍然继续使用P值。
在大部分研究者“盲目”使用P值大环境下,对科学研究的可重复性忧心忡忡的研究者们来说,要对科研界的现状进行有效的改变,改变P值的统计阈限也许是一个简单有效的办法。
重新定义统计显著性
正是在这样的背景之下,一篇名《重新定义统计显著性(Redefine Statistical Significance)》横空出世(Benjamin, Berger, Johannesson, Nosek, et al., 2017)。这篇由72名的研究方法专家共同署名的论文建议:
We propose to change the default P-value threshold for statistical significance for claims of new discoveries from 0.05 to 0.005.
“对于新发现的研究结论,我们建议将其统计显著性的默认P值阈限由0.05改为0.005”。
更加具体一点来说,这些研究者提出,对于新现象的探索研究,如果P值在0.005到0.05之间,则应该使用“启示性(suggestive)”这个词;如果P值小于0.005,才能使用统计显著。
这篇文章在Nature子刊Nature Human Behaviour上发表。文章的许多作者,都是应对“可重复危机”的主导者:其中包括弗吉尼亚大学心理学系教授Brian Nosek,他组织了大规模心理学重复研究、发起成立了推动科研界更开放和更透明的公益组织——开放科学中心(Center for Open Science);斯坦福大学医学院教授John P.A. Ioannidis,这位最早关注生物医药领域文章假阳性问题的大咖;认为心理学家应该抛弃P值使用贝叶斯统计的荷兰阿姆斯特丹大学心理学系的教授E-J Wagenmakers;普林斯顿大学社会学系教授、美国科学院院士、《知识分子》主编之一谢宇教授。
0.05代表的证据很弱;0.005则相对更强
为什么这些方法学上的知名学者要将P值 < 0.05的地位从“统计上显著”的神坛下降到“启示性”呢?文章中指出,因为P值在0.05附近时,只有很弱的证据表明存在着效应。实际上这一点在2015年美国统计学会关于P值的声明中就已经指出来过,但是却未能引起人们的重视。
为什么说P值小于 0.05得到的证据很弱?这一点Johnson (2013)在PNAS上发表的一篇文章中进行了说明,而在最近这篇重复定义显著性的文章,也再次使用这个思路——使用贝叶斯因子(Bayes factor)进行类比。
贝叶斯因子的思路是这样的:假如我们收集了一批数据,并使用这批数据来检验某个效应是否存在 。那么,分别计算出当前数据支持存在效应这个假设是真的概率和数据支持不存在效应假设的概率,然后把这两个概率相除。如果远大于1,表明更加倾向于支持备择假设;如果小于1,则更加倾向于零假设。
虽然贝叶斯因子与P值属于不同的统计流派,但可以采用两种方法对同一批数据进行分析,大致得到一个对应关系:研究者发现P值 = 0.05与贝叶斯因子3左右相当)。也就是说,当前数据支持有效应假设的可能性,与支持效应假设的可能性之比为3:1。从这个比例上来看,数据对有效应这个假设的支持力度并没有相对很强,而且从贝叶斯因子的直觉标准来看,这个证据强度是非常弱的。
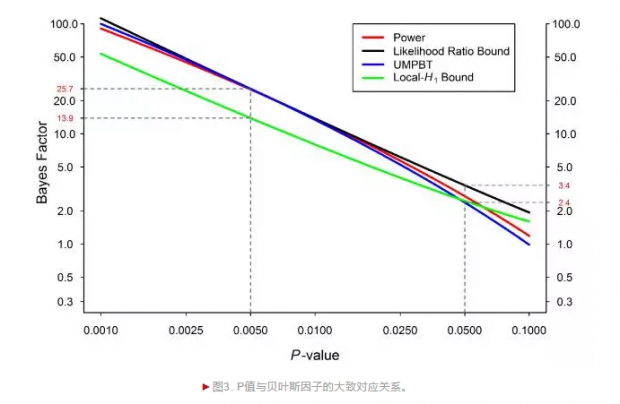
相反,如果P值为0.005,则证据更加强。与0.005对应的贝叶斯因子是13.9,25.7,也就是说,有效应与没有效应的比值为13.9:1或者25.7:1,这种情况之下,数据对有效应的假设的支持力度强得多(见图3)。
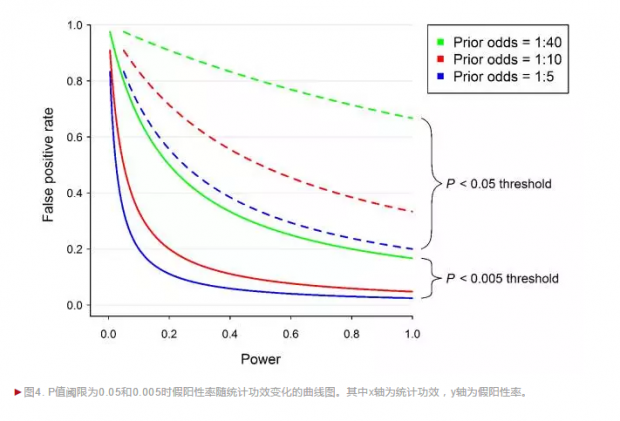
统计显著性的标准由0.05下降到0.005,会使假阳性出现的可能性下降到可接受的程度。这个结论一方面可以通过数据模拟得到(见图4),也得到了大规模重复实验结果的验证。最近两次大规模重复实验(心理学(Open Science Collaboration, 2015)和经济学(Camerer et al., 2016)也表明,如果以0.005作为标准,将原研究结果分为P值小于 0.005与P值在0.005与0.05之间的两部分,则可以看到,在重复成功的比例上,前者大约是后者的两倍:在心理学中是50% v 24%;在经济学中是85% v. 44%。这也许是为什么许多研究者认为,将显著性标准下降到0.005,会减少许多假阳性的研究。
此外,在文章中,作者们也指出,有两个研究领域采用非常严格的标准,而这样的标准对该领域来说是有好处的。在高能物理领域,采用的是5个sigma的标准,换作P值是大约是3×10^(-7);而基因研究中,基因组学研究的显著性标准被下降到5×10^(-8)后,整个领域变得更加稳健。
P值小于0.005适用的范围
尽管作者们认为,当P值 < 0.005时比 P值在0.005与 0.05之间时提供了更强的证据,但作者们也谨慎地说明,这一标准仅适用于探索新现象,而不适用于验证性研究或者是重复研究之中。对于原本采用更加严格标准的领域,如基因研究或者高能物理领域,也不适用。
在随后一篇博客文章中(Benjamin, Berger, Johannesson, Johnson, et al., 2017),几位作者进一步表明,0.005的标准适合于对证据的进行推断,而不是作为出版的标准。对于一个非常有原创性的效应,即使其结果在0.005与0.05之间,只要明确表示这是启示性的证据,也应该发表。
知名学者的支持
这篇文章的72名作者来自社会学、心理学、经济学、人类学、医学、生态学和哲学。而这个文章的署名,更像是一种签名,目的是为了获得各个领域研究者的广泛支持。
从某种程度上,这是研究者们为了扩大影响的一个举措。2016年,美国统计学会以权威姿态发表了P值的声明之后,总体上就像其他方法学的论文一样,最后变得寂寂无闻。这一次,作者们为了在更大范围内引起重视,作者们采用让更多领域的同行加入,扩大影响的做法。但是对于这一做法本身是否符合科学的规范,研究者们也有不同的意见。
降低P值带来的纷争
这篇文章一经刊出,立刻在科学圈引起了一阵热潮。虽然作者们在文章中已经想到了可能的反对的声音,但批评的声音仍旧不绝于耳。在社交媒体上的调查也显示,支持和反对这篇文章观点的人数基本持平。荷兰研究者Daniel Lakens在社交媒体上将反对者组织起来,准备写一篇关于这篇文章的评论,截止到现在已经得到超过72个研究人员的支持。
在讲反驳之前,需要先重述一下这篇文章的核心观点:对于新发现的研究结论,将其统计显著性的默认P值阈限由0.05改为0.005。其主要的目的是为了在以最广泛接受的方法来降低发表论文中结果的假阳性。同时0.005的标准主要是用于推断证据的强度,而非作为发表论文的标准。在此基础之上,我们再看其他研究者们的批评意见。
第一个反对的声音来自于对假阴性的担心:即实际上有效应,但是我们的高标准导致在一个实验中无法发现该现象。作者们的反驳(包括博客)是:如果说将科研当作一次性的试验,这个将会是一个问题,但是如果把科研当作不断累积的过程,则这个不会再是问题。因为当P值未达到显著水平时,我们无法拒绝零假设,不代表我们要接受零假设,而是需要进一步的证据。这种情况下,如果我们继续累积数据,并综合所有的数据进行判断,对于真正存在的效应,我们仍然可以发现。
同时,只要统计功效(Statistical power)保持一定,0.005的标准并不会增加假阴性。这时,也有研究者反对说,在0.005的标准下保持较高的统计功率,其带来的样本量增加(及其金钱成本的增加),是小实验室所不能承受的。对于这个问题,研究者们的反驳是:a)样本量的增加并没有人们所想象的那么可怕,要保持80%的统计功效,从0.05到0.005标准的变化,需要增加70%的样本量。也就是说,原来是需要50人,现在大约要增加到85人(当然这一点与效应量<effect size>的关系非常大,效应量小的研究原本就需要更多的样本量);b)多个小的实验可以通过元分析的方法联合起来,提供更有说服力的证据;c)0.005并不是作为论文发表的标准,如果研究的方法严格,问题有意义,P值在0.005和0.05之间,并且作者明确说明证据是提示性的,那么就不应该拒绝发表这样的研究。
在这两个问题上,阿姆斯特丹大学的Wagenmakers教授在其博客上指出了P值显著性标准的变化,其实是在表明科研界对待证据态度:我们是否要继续保持 0.05,假装0.05这个标准得到的证据就足够强了(Wagenmakers, 2017)?
另一个比较有趣的批评是:可重复性的问题是由许多原因导致的,为什么不去解决其他的问题而是要拿P值来说事儿呢?这个批评有点类似于:为什么我们要做A呢,B也很重要啊。对于这个分散注意的问题,作者们承认可重复性问题是由许多原因导致的,而他们中的许多人都在致力于让研究变得更可重复,包括一直在呼吁的Innondias,创办了Center for Open Science的Brian Nosek。但是改变统计显著性的阈值,最主要是因为这标准使用范围最广泛,改变后产生的性价比也许是最高的。
还有研究者认为,应该完全抛弃P值及其背后的零假设检验,而不是这样小修小补。例如,《美国公共健康杂志》(AJPH)从1983年起就要求投稿者删除所有P值,否则就请转投其他杂志。《流行病学》(Epidemiology)在1990创刊之初也公开声明:“作者在投稿本刊时,若忽略显著性检验,将有助于提高稿件被录用的可能性……我们根本就不采用这一方法。”Basic and Applied Social Psychology杂志最近也宣布禁止使用P值(Trafimow & Marks, 2015)。许多统计学家也同意这一观点的,比如Wagenmakers和Rouder,他们一直呼吁让大家使用贝叶斯因子。但令研究者无奈的时,推广贝叶斯统计或者其他统计方法的阻力,也许比改变P值的标准更困难,更难以让研究者们广泛接受。
还有一个批评的声音是:对于不同的问题,应该采用不同的显著性标准。作者们完全同意这一点。比如基因研究和高能物理,确实使用了不同的标准。只是0.05这个标准已经在许多领域得到广泛应用(如图1所示),而0.005这个标准,也以许多领域来说是可以减少假阳性的,所以作者觉得有这个必要,将0.05这个标准向更严格的方向前移一下。
控制假阳性的钟摆,是否真会摆向更加严格的方向?
研究者们在是否要“重新定义显著性”这个问题上的争议,本质上也是一种权衡:要严格地控制假阳性,集中资源来做一些更有可能被重复出来的研究?还是分散资源,同时在多个问题上进行尝试?过去几年中关于可重复性危机的反思中,不少研究者似乎倾向于更加严格地控制假阳性,而另一些研究则认为这种做法得不偿失。
当然,随着类似于“众包”研究等新研究形式的出现,更加严格控制假阳性时要增加研究成本的问题,也许可能会缓解。
最终显著性是否会被“重新定义”,要看科研界的整体政策走向,尤其是科研杂志的审稿政策。也许在这个“publish or perish”的环境中,学术杂志的标准,才是真正的“黄金标准”吧。但无论如何,参考一下显著性检验的两位“始作俑者”的原话(译文引自吕小康.(2014)),仍是有益的:
假设检验不止是个数学问题,它还非常依赖高度哲学化的思考。只要给定足以作为出发点的原理,数学就能推导出检验假设所需要的公式。但这些原理并不源自数学本身,而是对各种条件进行分析的结果,而正这些条件决定了普通人是否愿意相信所提出的假设。即便没有一个明了证明过程的数学家会拒绝一个得到准确证明的定理,人们也可因为认定建立假设的原理本身有误,从而拒绝接受这些原理。
——Neyman
在我看来,不涉及实际经验正是其(指Neyman-Pearson)工作的严重缺陷所在。他们的方法能在引入数学假定的前提下得到确定结果,但是否相信这些数学假定却必须基于广博的经验。可惜的是,他们并未探讨支持这些假定的证据为何。若顾及这一点,他们就会发现,实际中只有凭借经验才能确定显著性检验在频率意义上的结果是否显著。总之,我们得到的结论,既依赖于对类似事物的直接实验,也依赖于我们对观测效应如何产生的一般性理解。潜在假定的引入,只会掩盖这一事实:真实知识的产生过程其实是试探性的。
——Fisher
参考文献
Benjamin, D. J., Berger, J. O., Johannesson, M., Johnson, V., Nosek, B., & Wagenmakers, E. J. (2017). We Should Redefine Statistical Significance. Retrieved from
Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A., Wagenmakers, E.-J., Berk, R., . . . Johnson, V. E. (2017). Redefine Statistical Significance. Nature Human Behaviour. doi:10.1038/s41562-017-0189-z
Bennett, J. H. (ed.). 1990. Statistical Inference and Analysis: Selected Correspondence of R. A. Fisher. Oxford: Clarendon Press.
Camerer, C. F., Dreber, A., Forsell, E., Ho, T.-H., Huber, J., Johannesson, M., . . . Wu, H. (2016). Evaluating replicability of laboratory experiments in economics. Science. doi:10.1126/science.aaf0918
Haller, H., & Krauss, S. (2002). Misinterpretations of significance: a problem students share with their teachers. Methods of Psychological Research Online, 7(1), 1–20. Retrieved from https://www.metheval.uni-
Johnson, V. E. (2013). Revised standards for statistical evidence. Proceedings of the National Academy of Sciences, 110(48), 19313-19317. doi:10.1073/pnas.1313476110
Oakes, M. W. (1986). Statistical inference: a commentary for the social and behavioral sciences. Chichester: Wiley.
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), 943. doi:10.1126/science.aac4716
Reid, C. 1982. Neyman-From Life. New York: Springer-Verlag.
Trafimow, D., & Marks, M. (2015). Editorial. Basic and Applied Social Psychology, 37(1), 1–2. doi:10.1080/01973533.2015.1012991
Wagenmakers, E.-J. (2017). Redefine Statistical Significance Part I: Sleep Trolls & Red Herrings. Retrieved from
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA's statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129–133. doi:10.1080/00031305.2016.1154108
胡传鹏, 王非, 过继成思, 宋梦迪, 隋洁, & 彭凯平. (2016). 心理学研究的可重复性问题:从危机到契机. 心理科学进展, 24(9), 1504–1518 Doi:10.3724/SP.J.1042.2016.01504
吕小康. (2014). 从工具到范式: 假设检验争议的知识社会学反思. 社会, 34 (6), 216–236.
除以上文献与博客外,本文还参考了果壳网科学人的《“可重复性危机”有多严重?》
本文感谢复旦大学心理学系李晓煦老师的帮助。

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号